MLflow Model Registry: What Is It?
Tracking the model stages is one of MLflow Model Registry’s primary goals. Thanks to this, the developers can quickly shift the models between stages and keep track of where each model is in the lifecycle.
Model Stages in MLflow
MLflow offers several predefined stages for collective cases such as:
- None: The initial or default status for each created model is none.
- Staging: Before being used in production, the models undergo testing and are evaluated at this stage.
- Production: In this phase, the models are deployed and predictions are made using them.
- Archived: The models are no longer being used at this point, although they are still stored for historical purposes.
Tracking the Model Stages in the MLflow Model Registry
Registering a Model
The create_registered_model() function is widely employed to foster a model and add it to the model registry. The model’s name is the input for this function.
Assigning a Stage to a Model
The mlflow.set_model_stage() function must be used to assign a model to a stage. The model name, version, and stage are the inputs for this function.
Transition of a Model from One Stage to Another
Employ the transition_model_version_stage() function to transition or shift the model from one stage to another. The model name, version, and target stage are the inputs for this function.
Listing the Stages of a Model in the MLflow Model Registry
We may track a model’s stages that are entered in the MLflow Model Registry which eploys the mlflow.list_models() function.
Required: The model name is the only required argument for this function which outputs a list of models with their versions and stages.
We can track the model stages in the MLflow Model Registry as follows:
Let’s use the example of “FuelX Inc.”, a car company that creates a fuel efficiency prediction model. This project aims to develop or create a machine learning model that is used to precisely predict how many miles per gallon (MPG) their vehicles would get depending on various factors including the engine size, weight, and gearbox type. The customers will be able to choose the fuel-efficient vehicles with the aid of the model.
Stage 1: Staging
Data Collection
The data on factors that affect the fuel efficiency such as engine size, weight, and driving behaviors must be acquired at this phase. Historical data can be acquired from various sources including multiple sensors, automakers, and other governmental agencies.
Here is the sample data that is recorded in a CSV file and is used at various phases of the model:
With the use of the following given code, register the vehicle model in the Model Registry. In the initial phase, set the stage to “Staging” for this model. Observe and validate the model on a regular basis. If the model is successful in testing and training, move it to the next “Production” stage.
Code Details
The following code is used to build a machine learning model that predicts the fuel efficiency using features. The code first loads the data from a CSV (Coma Separated Values) file and splits it into sets for testing and training. The model is then trained with the assistance of a linear regression model.
MLflow is then used to log the model without identifying a model URI. This means that a log of the model is sent to MLflow’s default tracking server. The code also logs the model’s metrics and settings.
The function then registers the model in the MLflow Model Registry. The model “Model_FUEL_Efficiency” and the step “Data Collection” are configured.
The code finally moves the model to the “Staging” step. As a result, the model may now be tested and evaluated.
Code Snippet:
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
import mlflow
import mlflow.sklearn
import pandas as pd_obj
from sklearn.model_selection import train_test_split as tts
from sklearn.linear_model import LinearRegression as LR
# Data Collection Load data from fuel_efficiency_data CSV file
historical_vehicles_data = pd_obj.read_csv("fuel_efficiency_data.csv")
F = historical_vehicles_data.drop(columns=["MPG"])
t = historical_vehicles_data["MPG"]
F_training, F_testing, t_training, t_testing = tts(F, t, test_size=0.1, random_state=40)
# Set the tracking URI to an HTTP or HTTPS scheme
tracking_url="REMOTE_SERVER_URI"
#set the Remote Server URL
mlflow.set_tracking_uri(tracking_url)
# Train the model using Linear Regression
model_LR = LR()
model_LR.fit(F_training, t_training)
# Log the model with MLflow without specifying model URI
with mlflow.start_run(run_name="Fuel Efficiency Run") as run:
mlflow.log_params({"model": "LinearRegression"})
mlflow.log_metric("r2_score", model_LR.score(F_testing, t_testing))
mlflow.sklearn.log_model(model_LR, "fuel_efficiency_model")
# Register the model in the Model Registry
fuel_Efficient_Model_URI = f"runs:/{run.info.run_id}/fuel_efficiency_model"
fuel_Efficient_Model = "Model_FUEL_Efficiency"
# Create MLF_client Object
fuel_Efficient_MLFclient = mlflow.tracking.MlflowClient()
# Create the model using registered model
registered_model = mlflow.register_model(name=fuel_Efficient_Model, model_uri=fuel_Efficient_Model_URI, tags={"stage": "Data Collection"} )
fuel_Efficient_MLFclient.update_model_version(version=registered_model.version,
name=fuel_Efficient_Model, description="Data Collection")
fuel_model_stage="Staging"
# Transition the Model to Staging and Set the version
fuel_Efficient_MLFclient.transition_model_version_stage(version=registered_model
.version, stage=fuel_model_stage,name=fuel_Efficient_Model)
Stage 2: Production
Model Development: Register the Model in the Model Registry
The fuel efficiency model’s success also depends on the model development phase. The model needs to be able to learn from the data and generate accurate forecasts.
Code Snippet:
fuel_Efficient_MLFclient.update_model_version(description="Model Development",
name=fuel_Efficient_Model, version=registered_model.version)
fuel_Efficient_MLFclient.transition_model_version_stage(stage="Production", version=registered_model.version, name=fuel_Efficient_Model)

Fuel Efficiency Model Evaluation
To ensure that the model is functioning properly, it is crucial to go through the evaluation stage. To ensure that the model is fulfilling the intended accuracy and precision requirements, the performance of the model should be assessed using a range of metrics.
Code Snippet:
name=fuel_Efficient_Model, version=registered_model.version)
fuel_Efficient_MLFclient.transition_model_version_stage(stage = "Production", version= registered_model.version, name= fuel_Efficient_Model)
Model Deployment
The fuel efficiency model’s deployment phase is the last step in its development. The model should be implemented so the consumers can use it to predict the future.
Code Snippet:
name=fuel_Efficient_Model, version=registered_model.version)
fuel_Efficient_MLFclient.transition_model_version_stage(stage = "Production", version= registered_model.version, name= fuel_Efficient_Model)
Model Monitoring
The model monitoring stage is crucial to make sure that the model keeps working correctly. It is important to regularly check the model’s functioning for any potential issues.
Code Snippet:
name=fuel_Efficient_Model, version=registered_model.version)
fuel_Efficient_MLFclient.transition_model_version_stage(stage = "Production", version= registered_model.version, name= fuel_Efficient_Model)
Stage 3: Archive
Assume that the fuel-efficient consumption model is malfunctioning. Archive the model if it is unsuccessful, which is a clear indication that this model has never been used in the near future but may be required in the long run. In order to reflect the new stage, the code also changes the model version.
Code Snippet:
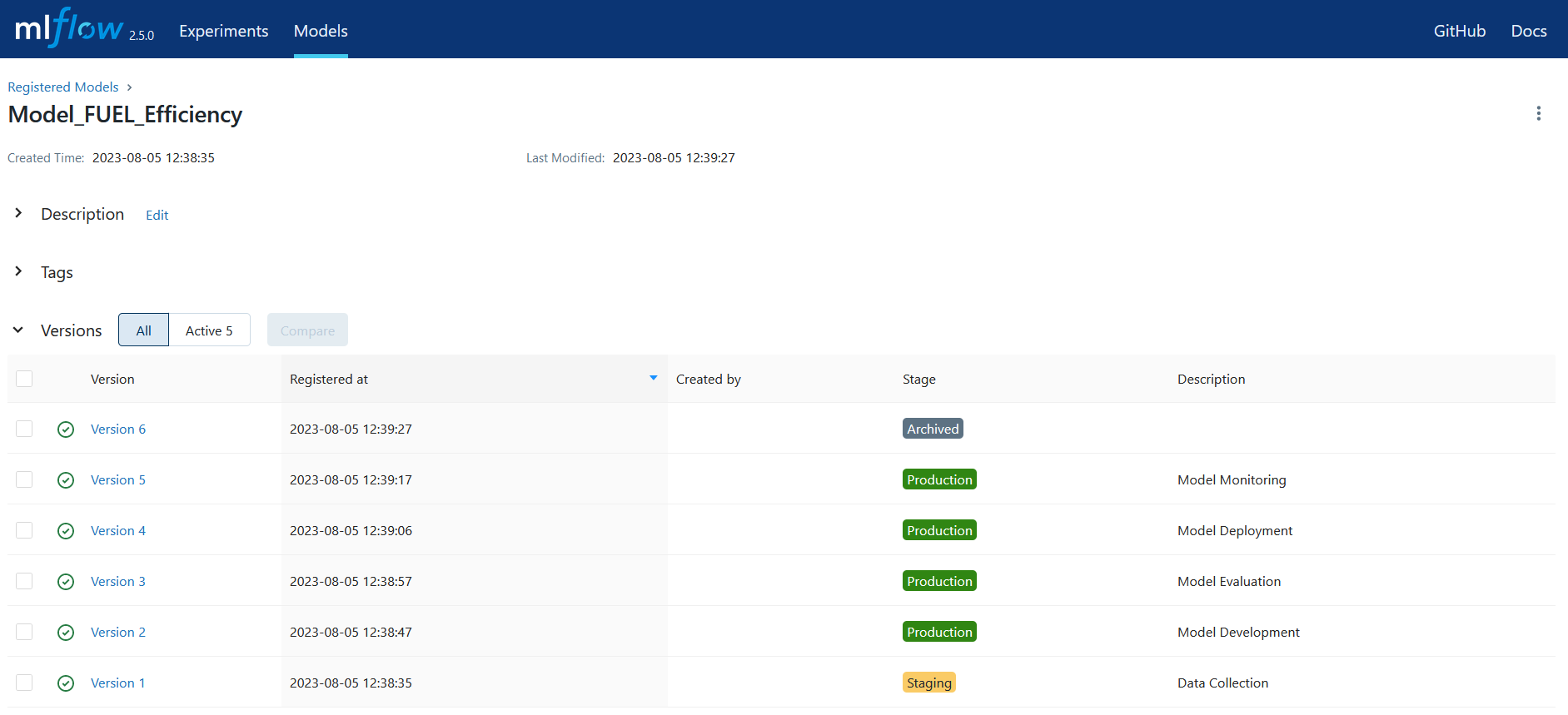
MLFlow Model Stages in the MLflow Server URI
Select the “Models” tab while MLflow Tracking Server is open in the browser. There is a list of models:
Conclusion
We covered about MLflow Model Registry tracking model stages. We discovered that MLflow has several predefined stages for typical use scenarios including Staging, Production, and Archive. In addition, we learned how to list the steps of a model in the model registry, register a model in the model registry, assign a model to a stage, and move a model from one stage to another.
By monitoring the model development in MLflow, a model’s lifecycle can be tracked effectively with the help of a model registry. This makes it simple for developers to manage the models and ensure that they are ready for the purposes for which they are designed.