The Function Used to Load the Model
The mlflow.<model_type>.load_model() function can be used to load a machine learning model in MLflow. The type of model we wish to load is specified by the <model_type> option.
For instance, we would use the load_model() function of mlflow.sklearn library to load a scikit-learn model.
The path to the model is the only argument required by the load_model() function. A registered model path, a DBFS (Databricks File System) path, or a run-relative path can all be used as the path.
Syntax to Load Model from Run-Relative Path:
Syntax to Load Model from a DBFS path:
Syntax to Load Model from a registered model path:
Example to Predict Price of Houses
A data scientist is working on a machine learning project to predict the cost of homes in a specific city. They are now ready to save the model for application after training it with various data sources.
The data scientist saves the model using the MLflow library. In this scenario, they first specify that it is a scikit-learn model and then provide a run-relative path as the model’s storage location.
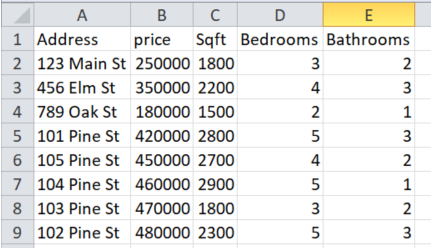
CSV File Data
Here is an example set of housing data in CSV format that will be imported into the code that follows.
Import the Required Libraries

Load Data from CSV File
The code creates a Pandas DataFrame called house_data and reads house_data.csv. The price column is added to house_feature_X, and the house_data DataFrame is divided into features (X) and targets (y).
Estimating a house’s price based on size, bedrooms, and location is done using the house_feature_X DataFrame and house_target_y Series. The target variable, price, is transferred to the house_feature_X DataFrame from the house_data DataFrame.
The Pandas Series object, similar to the NumPy array, allows label indexing and is created by selecting the price column from DataFrame house_data.
house_feature_X = house_data.drop("price", axis=1)
house_target_y = house_data["price"]
The tts() function requires four arguments: data, target, test size, and random state. The target and feature-containing DataFrame are used, with the target column forecasted. The test size is divided randomly, and the data undergoes modifications using ColumnTransformer and OneHotEncoder transformers. The remainder=’passthrough’ option prevents changes to other columns.
The preprocessor then transforms training data using the fit_transform() method, resulting in the modified X_train_preprocessed DataFrame.
house_preprocessor = CTF(
transformers=[('address', OHE(), ['Address'])],
remainder='passthrough'
)
X_train_preprocessed = house_preprocessor.fit_transform(House_Feature_training)
Train Machine Learning Mode
The first line of code creates a LinearRegression() object, a machine learning model for forecasting continuous values from features. The fit() method adjusts the model to match the training data, using the DataFrame and target as arguments.
house_model.fit(X_train_preprocessed, House_Trainings)
Log the Model and Associated Metrics using MLflow
House_price_model_run is the name of the new MLflow run that is initiated in the first line of code. The run name is the only argument required by the mlflow.start_run() function. A human-readable string known as the run name serves as the run’s identifier.
The model metrics and subsequent code lines are logged. The mlflow requires two arguments.log_param() function: the parameter name and the parameter value. The mlflow requires two inputs.log_metric() function: the metric name and the metric value.
The model and any related artifacts are logged by the log_model() function. The model is stored as a sterilized file in the MLflow artifact store.
The run ID and name is printed to the console.
mlflow.log_param("model_type", "LinearRegression")
mlflow.log_metric("train_rmse", 100)
mlflow.sklearn.log_model(house_model, "house_price_model")
house_run_id=run.info.run_id
run_name=run.info.run_name
print("Run ID: "+house_run_id)
print("Run Name: "+run_name)
Method 1: Load the Model Using the artifact_uri From the Run
mlflow.sklearn.load_model() only accepts the artifact URI as an input. The URI indicates the model’s position in the MLflow artifact storage.
Prepare Input Data for Predictions
The data input is prepared for predictions in the next few lines of code. The data for which we wish to create predictions is contained in the house_input_data DataFrame. Using the same encoder that was used to train the model, the house_preprocessor object analyzes the input data.
The preprocessed input data is stored in the house_input_preprocessed DataFrame.
The predict() method generates predictions using a home-loaded model, with projected house prices printed to the console.
"Address": ['123 Main St', '789 Oak St'],
"Sqft": [1500, 1800],
"Bedrooms": [3, 3],
"Bathrooms": [2, 2]
})
# Preprocess the input data using the same encoder
house_input_preprocessed = house_preprocessor.transform(house_input_data)
# Make predictions using the loaded model
house_predictions = house_loaded_model.predict(house_input_preprocessed)
print("Predicted House Prices:")
print(house_predictions)
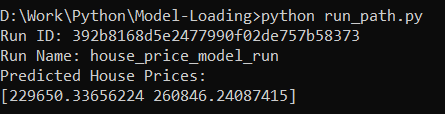
Execute the Code
Execute the code using the python compiler. Here is the output of the successful execution:
Method 2: Register & Load Model using Registered Model Path
We must first register the model in the model registry. There is just one modification in the code below; the rest is unchanged:
A model URI is created in the very first line of code. A string called the model URI identifies the model’s position in the MLflow artifact store. The format of the model URI is Runs:/RUN_ID>/ARTIFACT_PATH>. In this instance, the run ID is the run ID for which the model was logged in.
Create a registered model name in the second line of code, a human-readable string for model identification in MLflow. MLflow registers a model using the mlflow.register_model() function, registering it in the model registry, which is the main repository for MLflow models.
registered_model_name = "house_price_model"
mlflow.register_model(model_uri=model_uri, name=registered_model_name)
Load Model from Registry
The registered model name and version define the model registered with MLflow and are given in the first line of code. In the second line of code, the registered model is loaded using the mlflow.pyfunc.load_model() function, which requires only 0the model URI as a parameter. The model’s URI, which is a string, indicates where it is located in the MLflow model registry. This function returns a prediction-making Python function.
model_version = "1" # Replace with the correct version
# Load the registered model
loaded_model = mlflow.pyfunc.load_model(
model_uri=f"models:/{House_price_model}/{model_version}"
)
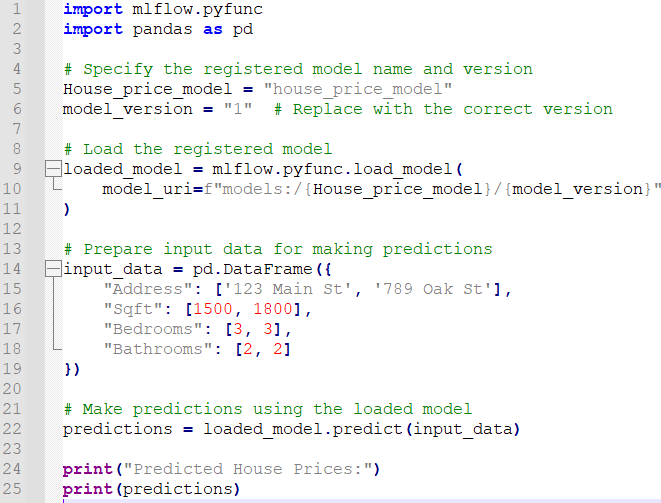
Here is the Output

Conclusion
MLflow is an outstanding tool for loading models. There are numerous ways to load models, including using files, the MLflow model registry, and Docker images. The output of a model run can always be replicated since MLflow keeps track of a model’s history.