MLflow Models: Machine learning models can be packaged in the MLflow Models standard format and implemented with a range of downstream technologies, including the REST API, Apache Spark, and Microsoft Azure ML. As a result, deploying models to different environments is insignificant.
MLflow Tracking: MLflow Tracking can monitor how well machine learning models perform while being trained and employed. This information is beneficial in identifying the models that are performing best, and it also assists in making wise decisions about when to apply updates to models.
MLflow Pipelines: MLflow Machine learning model deployment can be done automatically through pipelines. This may help guarantee that models are implemented in a consistent and repeatable manner while also saving time and effort.
Process of Serving Machine Learning (ML) Models with MLflow
There are three basic steps involved in serving the models with MLflow:
Train the Model: A model must first be trained and logged using the preferred framework, such as PyTorch, Scikit-Learn, TensorFlow, etc. All of the training’s variables, metrics, and artifacts may be recorded.
Package the Model: Once trained, the model needs to be packed in the MLflow Models format. For this, we might employ the mlflow.sklearn.save_model() function. This might make tracing several iterations and versions of previously trained models possible.
Deploy the Model: A local workstation, an AWS or Azure server, a Kubernetes cluster, a Docker container, Google Cloud, or a cloud server are just a few of the various storage locations where the model can be deployed. One of the many tools offered by MLflow to assist us deploy models is the MLflow server.
Example
MLflow can be used to deliver machine learning models trained to recommend products to consumers based on their prior purchases, browsing history, wish list, and other factors in the context of product recommendation. This could be a very effective strategy to enhance client satisfaction and increase online sales.
Here is an illustration of how to utilize MLflow to support a product recommendation model:
Pre-Requisite Steps:
Import Required Libraries:
![]()
Ignore Warnings
Python will be instructed to ignore any warnings reported from the UserWarning category that contain the message “Distutils was imported before Setuptools” by using this code. This will stop the console or prompt screen from displaying the warning.
Define Product Recommendations, Model Class
A class called Product_Recommendation_Model has been defined in the code given below. This class is an inherited or child class of the PythonModel class from mlflow.pyfunc. The base class for Python models that MLflow can serve is mlflow.pyfunc.PythonModel.
The Product_Recommendation_Model class has two methods:
load_context(): This method is called when the model is loaded from the MLflow artifact store. Any already-trained model weights, embedded data, or other resources that the model requires are loaded using this approach.
predict(): This method is called when the model is used to make predictions. It takes two arguments:
- context: This is a dictionary that contains information about the model and the prediction request.
- model_input: This information serves as the prediction’s input.
- The predict() method should return the expected result. A list of products that are suggested for the consumer is the projected result in the case of the Product_Recommendation_Model class. Both the predict() and load_context() methods are abstract techniques. This indicates that subclasses of the mlflow.pyfunc.PythonModel class are required to implement them.
def load_context(self, context):
# Load pre-trained model weights, embeddings, or other resources
pass
def predict(self, context, model_input):
# Perform recommendation based on the loaded resources
recommendations = ... # Your recommendation logic here
return recommendations
Train & Log the Product Recommendations Model
Product_train_log_model() is a function that is defined in the code. The model and training metrics are logged to MLflow via this function, which also trains a product recommendation model. The steps in the product_train_log_model() function are as follows:
A new instance of the Product_Recommendation_Model class is created in step one.
It establishes a training metrics dictionary (key-value pairs). It will log this dictionary to MLflow.
It launches MLflow. This is used to record models and training metrics as well as the training process. Set Product_Recommendation_Model_RUN as the run’s name.
The model is logged to MLflow using the mlflow.pyfunc.log_model() function. The model is logged under the product_recommendation artifact path.
The training metrics are logged to MLflow using the mlflow.log_metrics() function.
# Code to train product recommendation model
product_model = Product_Recommendation_Model() # Create an instance of your model
product_metrics = {"loss": 0.15, "accuracy": 0.89}
# Log the model and training metrics to MLflow
with mlflow.start_run(run_name="Product_Recommendation_Model_RUN") as run:
mlflow.pyfunc.log_model(artifact_path="product_recommendation", python_model=product_model)
mlflow.log_metrics(product_metrics)
Model Packaging & Registration
The function package_and_register_product_model() appears in the code. The trained model is packaged using this function, which also registers it in the MLflow model registry. The steps involved in this function are outlined below:
It employs warnings. To ignore a warning about Setuptools replacing distutils, use the filterwarnings() function. This is a minor warning that we can ignore.
The trained model is saved to a local directory as provided in the path. The product_model_path variable specifies the directory path.
A fresh MLflow run context is established. The registration process is tracked using this.
The saved model is registered in the MLflow model registry. Product_Recommendation_Model is the name given to the model when it is registered. This name must coincide with the name that was used to log the model into MLflow. (in previous code).
warnings.filterwarnings("ignore", category=UserWarning, message="Setuptools is replacing distutils")
# Save the trained model to a local directory
product_model_path = "product/model" # Replace with your desired local directory
mlflow.pyfunc.save_model(path=product_model_path, python_model=Product_Recommendation_Model())
# Start a new run context for registering the model
with mlflow.start_run(run_name="Product_Package_Model_Run") as run:
# Register the saved model in the MLflow model registry
product_registered_model_name = "Product_Recommendation_Model" # Should match the name used during logging
mlflow.register_model(model_uri=product_model_path, name=product_registered_model_name)
Call the Functions in Main Method
product_train_log_model()
package_and_register_product_model()
Run the Code
Navigate to the working directory using the bash or command prompt and python command compiler to run the code. Here is the output of the file after successful execution:

This creates multiple folders inside the working directory and saves the product model into the product/model folder. Here is a snippet of the directory:
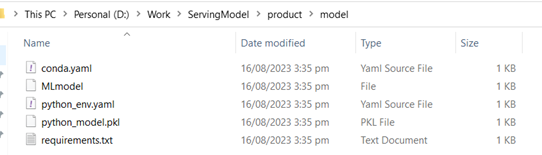
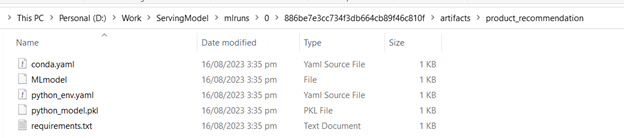
Product Model Deployment on Local Host
The code you provided defines a Flask application that can be used to deploy the product recommendation model.
The Flask application has the following steps:
- It imports the Flask library.
- It makes a Flask application object.
- It defines a route for the /predict endpoint.
- The predict() function loads the model from the MLflow artifact store.
- The predict() function gets the input data from the request.
- The predict() function makes a prediction using the model.
- The predict() function returns the prediction to the browser.
- The if __name__ == “__main__”: block starts the Flask application.
In the exact same working directory where the model is built and saved, create a new Python file. In our case, the file name is deploy_script.py. Copy the below code into it:
product_app = flask.Flask(__name__)
@product_app.route("/predict")
def predict():
product_model = mlflow.pyfunc.load_model("product/model")
# Get the input data
input_product_data = request.args.get("input_data")
# Make a prediction
product_prediction = product_model.predict(input_product_data)
# Return the prediction
return jsonify(product_prediction)
if __name__ == "__main__":
product_app.run()
Execute the code:

Open the MLflow Server and see the output there:
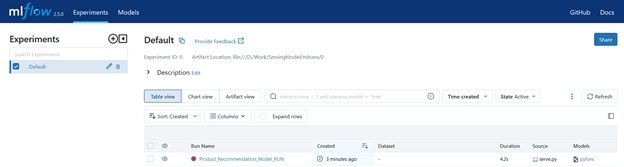
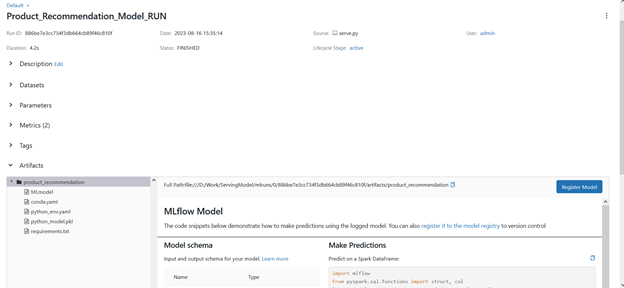
Conclusion
The platform MLflow manages model serving and contains the entire ML lifecycle. MLflow offers several solutions for providing models, including REST APIs, Google Cloud, web UIs, and Docker images. A model must first be logged to the MLflow model registry to be used in MLflow. One of the aforementioned tools can be used to deploy the model after it has been logged. Models can be quickly deployed to production owing to the robust MLflow platform.