- Experiment tracking: MLflow can track the metrics evaluated for each configuration of a hyperparameter along with all of the hyperparameters used in an experiment. With this knowledge, the hyperparameter search space may be visualized, and the ideal hyperparameters for a given model can be determined.
- Model registry: Hyperparameter optimizing experiment models can be saved and tracked in MLflow. This makes it simple to contrast various models and choose the optimal model for a given application.
- Pipeline execution: MLflow can accomplish hyperparameter tuning experiments as pipelines.
Here’s a complete guide on using MLflow for hyperparameter tuning in models:
Create a Project Directory
Open the command prompt or bash and navigate to the working directory. Use the mkdir command to create a separate folder inside the active directory with the desired name, like HyperParameter, to store the necessary code files, data files, and other relevant output files.
![]()
Install MLflow Module
Install the MLflow module with the help of the pip command if it is not already installed on the working machine. The following command will install it when you open the command prompt:
Mobile Network Company Scenario
A real-world scenario for a mobile network company to use MLflow for hyperparameter tuning:
A mobile network provider is creating a new machine learning model to forecast how many calls will be dropped in the system. They have access to an extensive collection of past call data, but they are unsure of the hyperparameters their model should employ. They choose to track their experiments with hyperparameter tweaking using MLflow.
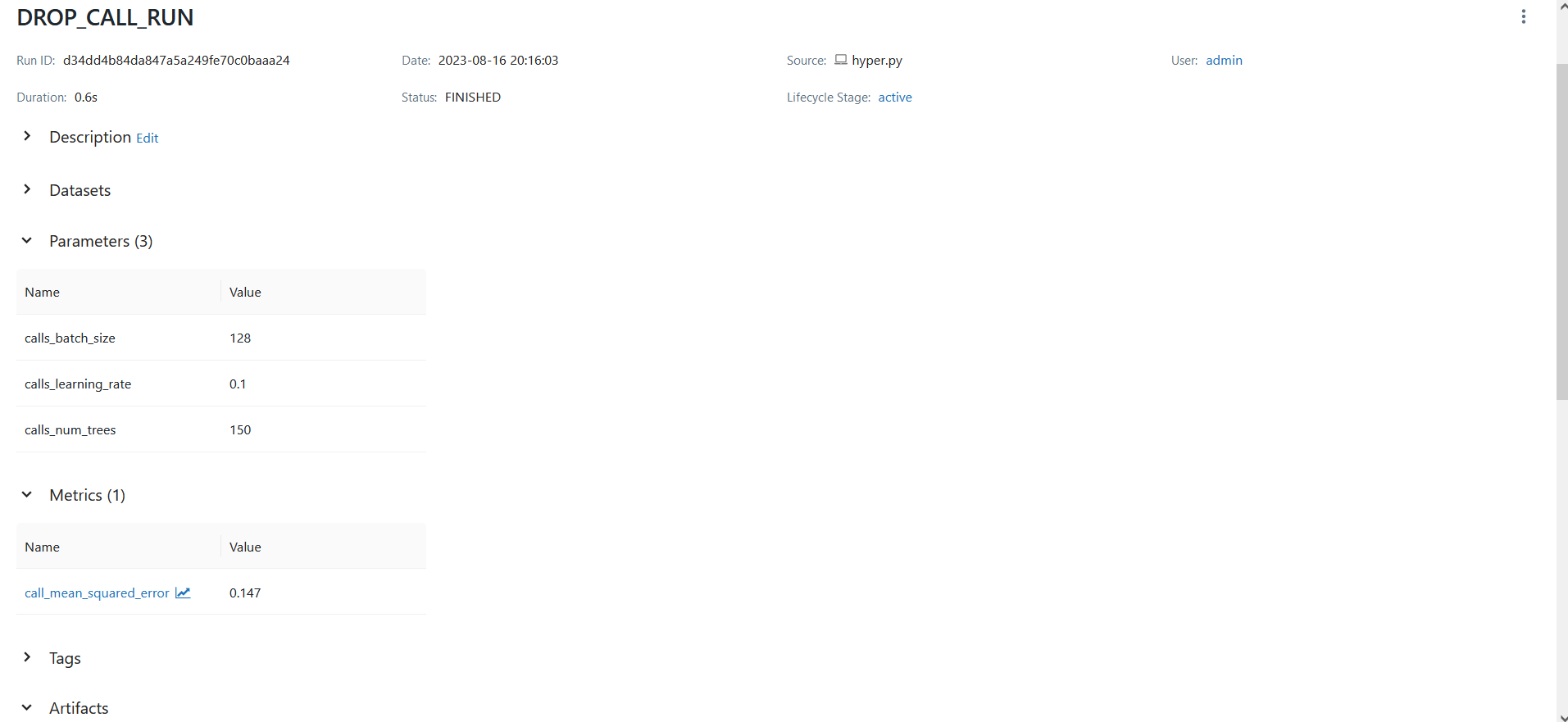
Define hyperparameters like learning rate, decision tree number, and batch size, and create a training and evaluation pipeline using the mlflow.sklearn module for tracking hyperparameters and metrics.
The company utilizes MLflow to track hyperparameter configurations, analyze results, and visualize search spaces to identify optimal hyperparameters for their models.
The company optimizes its model using a 0.00% learning rate, 100 decision trees, and 128 batch sizes for optimal performance.
MLflow helps the company track hyperparameter tuning experiments, reducing dropped calls and improving service quality by identifying optimal hyperparameters.
Mobile network companies should tune hyperparameters like cell number, signal power, frequency, bandwidth, and error correction code for efficient data transmission.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split as TTS
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.metrics import mean_squared_error as MSE
import numpy as np_obj
Load and Preprocess Data
The random number generator is given the value 42 as its initial seed in the line np_obj.random.seed(42). This ensures that the same random integers come out each time the code is run. This is necessary for repeatability so that it is possible to compare code results with reliability.
There are 100 entries in the call_drop_data array, each indicating a call. The signal strength, the distance to the nearest cell tower, and the weather are just a few examples of variables that could influence whether a call is dropped, represented by the five random integers that make up each row.
Each of the 100 elements in the drop_calls_target array denotes the number of dropped calls for a specific call. The values in the call_drop_data array are used to calculate the number of dropped calls.
call_drop_data = np_obj.random.rand(100, 5)
drop_calls_target = np_obj.random.rand(100)

Define Hyperparameters
Three lists of hyperparameters are specified in the code that can be used to fine-tune a machine learning model to forecast the frequency of dropped calls:
Three learning rates are listed in drop_calls_learning_rates. The learning rate is a hyperparameter that regulates how rapidly the model learns. Although the learning process will be slower with a lower learning rate, the model might be more accurate.
There are three numbers of trees in the list drop_calls_num_trees. A hyperparameter that regulates the model’s complexity is the number of trees. A model with more trees will be more complicated but might also be more accurate.
Three batch sizes are listed in drop_calls_batch_sizes. A hyperparameter called batch size regulates how much data is applied to train the model at once. Faster training will come from a larger batch size, but the model can end up being less accurate.
drop_calls_num_trees = [50, 100, 150]
drop_calls_batch_sizes = [32, 64, 128]
Create an Experiment:
Create Hyperparameter Search Loop:
A random forest regression is trained to forecast the frequency of dropped calls using the hyperparameter tuning loop in the code provided below. Three distinct learning rates, tree counts, and batch sizes are iterated over in the loop. The loop executes the following actions for each combination of hyperparameters:
- Trains a Regressor using a random forest model with the given hyperparameters.
- Predicts the quantity of dropped calls on a test set withheld-out call.
- Identifies the projected and actual number of dropped calls, and calculates the mean squared error (MSE).
- Logs the MSE and the hyperparameters to MLflow.
- At the conclusion of the loop, the MLflow experiment is shut down.
for n_trees in drop_calls_num_trees:
for call_drop_batch_size in drop_calls_batch_sizes:
with mlflow.start_run(run_name="DROP_CALL_RUN"):
# Train-test split
Call_Drop_Trainings_Feature, Call_Drop_Testings_features, call_drop_train, call_drop_tests = TTS(call_drop_data, drop_calls_target, test_size=0.2, random_state=42)
call_drop_model = RFR(n_estimators=n_trees, random_state=42)
# Train the model
call_drop_model.fit(Call_Drop_Trainings_Feature, call_drop_train)
# Predict on the test set
call_drop_predictions = call_drop_model.predict(Call_Drop_Testings_features)
# Calculate metrics
call_drop_metrics_means_square = MSE(call_drop_tests, call_drop_predictions)
# Log hyperparameters and metrics to MLflow
mlflow.log_param("calls_learning_rate", obj_call_learning_rate)
mlflow.log_param("calls_num_trees", n_trees)
mlflow.log_param("calls_batch_size", call_drop_batch_size)
mlflow.log_metric("call_mean_squared_error", call_drop_metrics_means_square)
# Close the MLflow experiment
mlflow.end_run()
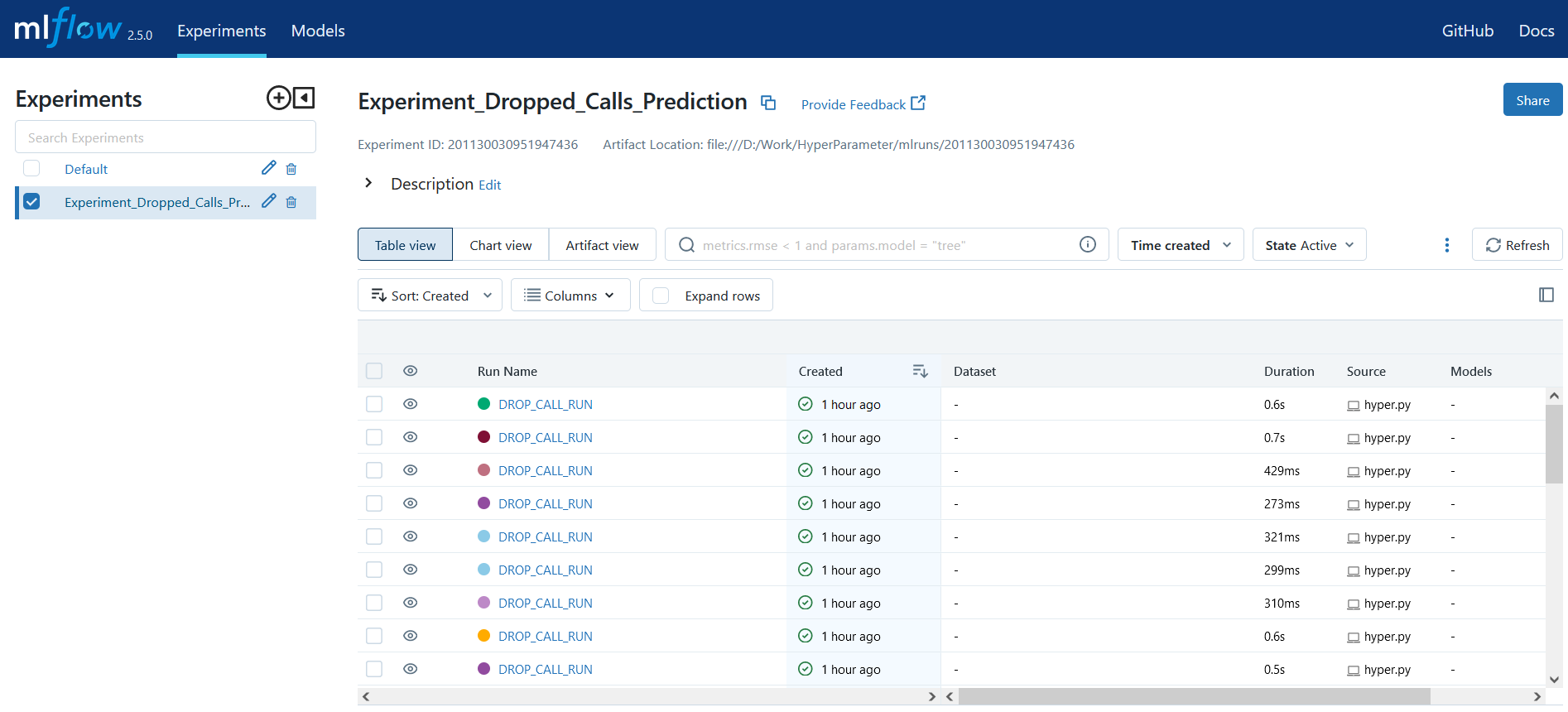
Visualize Results in MLflow UI
Start the mlflow server using the command below:
![]()
Select Best Hyperparameters
After completing the experiments, the company may select the optimal hyperparameters from the MLflow UI based on the performance metric (for example, mean squared error).
Here is the Output on the MLflow Server:
Train Final Model with Best Hyperparameters
The final model is deployed to production using the code. The hyperparameter tuning loop was used to determine the best hyperparameters for the model, which are then defined in the code. The best hyperparameters are then used to generate a final random forest regression model. The training data is then used to fit the model.
# Run 'mlflow ui' in the terminal to launch the UI
best_lr = 0.01
best_call_drop_num_trees = 100
best_batch_size = 128
final_call_drop_model = RFR(n_estimators=best_call_drop_num_trees, random_state=42)
final_call_drop_model.fit(Call_Drop_Trainings_Feature, call_drop_train)
# Deploy the final model to production
# Replace this with your deployment code
print("Model training and hyperparameter tuning complete.")
Deploy Model to Production:
The company can deploy the finished model into production by leveraging a preferred deployment framework or infrastructure.
Conclusion
A robust framework for managing and tracking machine learning experiments is MLflow. It may be used to keep track of the metrics and hyperparameters for each experiment, which can assist in choosing the ideal set of hyperparameters for our model. With its ability to be replicated, scaled, collaborative, and well-documented, MLflow is a fantastic option for hyperparameter tweaking.