UTF-8 stands for “Unicode Transformation Format 8-Bit” and corresponds to a great encoding format that ensures that the characters are displayed appropriately on all devices irrespective of the utilized language/script. Also, this format is assistive for web pages and is utilized for storage, processing, and transmission of text data on the internet.
This tutorial covers the below-stated content areas:
- What is UTF-8 Encoding?
- How Does UTF-8 Encoding Work?
- How are the Code Point Values Computed?
- How to Encode/Decode UTF-8 in JavaScript?
- Encode/Decode UTF-8 in JavaScript Using the “encodeURIComponent()” and “decodeURIComponent()” Methods.
- Encode/Decode UTF-8 in JavaScript Using the “encodeURI()” and “decodeURI()” Methods.
- Encode/Decode UTF-8 in JavaScript Using the Regular Expressions.
- Conclusion
What is UTF-8 Encoding?
“UTF-8 Encoding” is the procedure of transforming the sequence of Unicode characters to an encoded string comprising 8-bit bytes. This encoding can represent a large range of characters as compared to the other character encodings.
How Does UTF-8 Encoding Work?
While representing characters in UTF-8, every individual code point is represented by one or more bytes. Following is the breakdown of the code points in the ASCII range:
- A single byte represents the code points in the ASCII range (0-127).
- Two bytes represent the code points in the ASCII range (128-2047).
- Three bytes represent the code points in the ASCII range (2048-65535).
- Four bytes represent the code points in the ASCII range(65536-1114111).
It is such that the first byte of a “UTF-8” sequence is referred to as the “leader byte” which gives information about the number of bytes in the sequence and the character’s code point value.
The “leader byte” for a single, two, three, and four bytes sequence is in the range (0-127), (194-233), (224-239), and (240-247), respectively.
The rest of the bytes in sequence are called the “trailing” bytes. The bytes for a two, three, and four-byte sequence are all in the range (128-191). It is such that the character’s code point value can be computed by analyzing the leading and trailing bytes.
How are the Code Point Values Computed?
The code point values for different byte sequences are calculated as follows:
- Two-byte Sequence: The code point is equivalent to “((lb – 194) * 64) + (tb – 128)”.
- Three-bytes Sequence: The code point is equivalent to “((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)”.
- Four-bytes Sequence: The code point is equivalent to “((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)”.
How to Encode/Decode UTF-8 in JavaScript?
The encoding and decoding of UTF-8 in JavaScript can be carried out via the below-stated approaches:
- “enodeURIComponent()” and “decodeURIComponent()” Methods.
- “encodeURI()” and “decodeURI()” Methods.
- Regular Expressions.
Approach 1: Encode/Decode UTF-8 in JavaScript Using the “encodeURIComponent()” and “decodeURIComponent()” Methods
The “encodeURIComponent()” method encodes a URI component. Also, it can encode special characters such as @, &, :, +, $, #, etc. The “decodeURIComponent()” method, however, decodes a URI component. These methods can be utilized to encode and decode the passed values to UTF-8, respectively.
Syntax(“encodeURIComponent()” Method)
In the given syntax, “x” indicates the URI to be encoded.
Return Value
This method retrieved an encoded URI as a string.
Syntax(“decodeURIComponent()” Method)
Here, “x” refers to the URI to be decoded.
Return Value
This method gives the decoded URI.
Example 1: Encoding UTF-8 in JavaScript
This example encodes the passed string to an encoded UTF-8 value with the help of a user-defined function:
return unescape(encodeURIComponent(x));
}
let val = 'àçè';
console.log("Given Value -> "+val);
let encodeVal = encode_utf8(val);
console.log("Encoded Value -> "+encodeVal);
In these code lines, perform the below-given steps:
- Firstly, define the function “encode_utf8()” that encodes the passed string represented by the specified parameter.
- This encoding is done by the “encodeURIComponent()” method in the function definition.
- Note: The “unescape()” method replaces any escape sequence with the character represented by it.
- After that, initialize the value to be encoded and display it.
- Now, invoke the defined function and pass the defined combination of characters as its arguments to encode this value to UTF-8.
Output
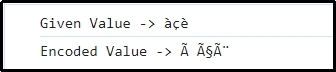
Here, it can be implied that the individual characters are represented and encoded in UTF-8 accordingly.
Example 2: Decoding UTF-8 in JavaScript
The below code demonstration decodes the passed value(in the form of characters) to an encoded UTF-8 representation:
return decodeURIComponent(escape(x));
}
let val = 'à çè';
console.log("Given Value -> "+val);
let decode = decode_utf8(val);
console.log("Decoded Value -> "+decode);
In this block of code:
- Likewise, define the function “decode_utf8()” that decodes the passed combination of characters via the “decodeURIComponent()” method.
- Note: The “escape()” method retrieves a new string in which various characters are replaced by hexadecimal escape sequences.
- After that, specify the combination of characters to be decoded and access the defined function to perform the decoding to UTF-8 appropriately.
Output
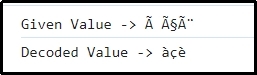
Here, it can be implied that the encoded value in the previous example is decoded to the default value.
Approach 2: Encode/Decode UTF-8 in JavaScript Using the “encodeURI()” and “decodeURI()” Methods
The “encodeURI()” method encodes a URI by replacing each instance of multiple characters with a number of escape sequences representing the character’s UTF-8 encoding. As compared to the “encodeURIComponent()” method, this particular method encodes limited characters.
The “decodeURI()” method, however, decodes the URI(encoded). These methods can be implemented in combination to encode and decode the combination of characters in a UTF-8 encoded value.
Syntax(encodeURI() Method)
In the above syntax, “x” corresponds to the value to be encoded as a URI.
Return Value
This method retrieves the encoded value in the form of a string.
Syntax(decodeURI() Method)
Here, “x” represents the encoded URI to be decoded.
Return Value
It returns the decoded URI as a string.
Example 1: Encoding UTF-8 in JavaScript
This demonstration encodes the passed combination of characters to an encoded UTF-8 value:
return unescape(encodeURI(x));
}
let val = 'àçè';
console.log("Given Value -> "+val);
let encodeVal = encode_utf8(val);
console.log("Encoded Value -> "+encodeVal);
Here, recall the approaches for defining a function allocated for encoding. Now, apply the “encodeURI()” method to represent the passed combination of characters as a UTF-8 encoded string. After that, likewise, define the characters to be evaluated and invoke the defined function by passing the defined value as its arguments to perform the encoding.
Output
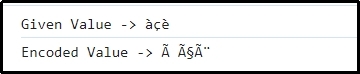
Here, it is evident that the passed combination of characters is encoded successfully.
Example 2: Decoding UTF-8 in JavaScript
The below code demonstration decodes the encoded UTF-8 value(in the previous example):
return decodeURI(escape(x));
}
let val = 'à çè';
console.log("Given Value -> "+val);
let decode = decode_utf8(val);
console.log("Decoded Value -> "+decode);
According to this code, declare the function “decode_utf8()” that comprises the stated parameter that represents the combination of characters to be decoded using the “decodeURI()” method. Now, specify the value to be decoded and invoke the defined function to apply the decoding to the “UTF-8” representation.
Output
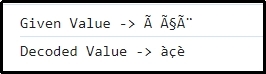
This outcome implies that the encoded value previously is decided accordingly.
Approach 3: Encode/Decode UTF-8 in JavaScript Using the Regular Expressions
This approach applies the encoding such that the multi-byte unicode string is encoded to UTF-8 multiple single-byte characters. Likewise, the decoding is carried out such that the encoded string is decoded back to multi-byte Unicode characters.
Example 1: Encoding UTF-8 in JavaScript
The below code encodes the multi-byte unicode string to UTF-8 single-byte characters:
if (typeof val != 'string') throw new TypeError('The Parameter 'val' is not a string');
const string_utf8 = val.replace(
/[\u0080-\u07ff]/g, // U+0080 - U+07FF => 2 bytes 110yyyyy, 10zzzzzz
function(x) {
var out = x.charCodeAt(0);
return String.fromCharCode(0xc0 | out>>6, 0x80 | out&0x3f); }
).replace(
/[\u0800-\uffff]/g, // U+0800 - U+FFFF => 3 bytes 1110xxxx, 10yyyyyy, 10zzzzzz
function(x) {
var out = x.charCodeAt(0);
return String.fromCharCode(0xe0 | out>>12, 0x80 | out>>6&0x3F, 0x80 | out&0x3f); }
);
console.log("Encoded Value Using Regular Expression -> " +string_utf8);
}
encodeUTF8('àçè')
In this snippet of code:
- Define the function “encodeUTF8()” comprising the parameter that represents the value to be encoded as “UTF-8”.
- In its definition, apply a check upon the passed value that is not the string using the “typeOf” operator and return the specified custom exception via the “throw” keyword.
- After that, apply the “charCodeAt()” and “fromCharCode()” methods to retrieve the Unicode of the first character in the string and transform the given Unicode value to characters, respectively.
- Finally, invoke the defined function by passing the given sequence of characters to encode this value as a “UTF-8” representation.
Output
![]()
This output signifies that the encoding is carried out appropriately.
Example 2: Decoding UTF-8 in JavaScript
In this demonstration, the sequence of characters is decoded to “UTF-8” representation:
if (typeof val != 'string') throw new TypeError('The Parameter 'val' is not a string');
const str = val.replace(
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g,
function(x) {
var out = ((x.charCodeAt(0)&0x0f)<<12) | ((x.charCodeAt(1)&0x3f)<<6) | ( x.charCodeAt(2)&0x3f);
return String.fromCharCode(out); }
).replace(
/[\u00c0-\u00df][\u0080-\u00bf]/g,
function(x) {
var out = (x.charCodeAt(0)&0x1f)< "+str);
}
decodeUTF8('à çè')
In this code:
- Similarly, define the function “decodeUTF8()” having the parameter that refers to the passed value to be decoded.
- In the function definition, check for the string condition of the passed value via the “typeOf” operator.
- Now, apply the “charCodeAt()” method to retrieve the Unicode of the first, second, and third-string characters, respectively.
- Also, apply the “String.fromCharCode()” method to transform the Unicode values into characters.
- Likewise, repeat this procedure again to fetch the Unicode of the first and second string characters and transform these unicode values into characters.
- Lastly, access the defined function to return the UTF-8 decoded value.
Output
![]()
Here, it can be verified that the decoding is done correctly.
Conclusion
The encoding/decoding in UTF-8 representation can be carried out via the “enodeURIComponent()” and “decodeURIComponent() methods, the “encodeURI()” and “decodeURI()” methods, or using the Regular Expressions.