
This article will discuss some of the ways to crawl a website, including tools for web crawling and how to use these tools for various functions. The tools discussed in this article include:
[adthrive-in-post-video-player video-id=”hTOr1xiD” upload-date=”2020-06-17T14:09:40.000Z” name=”Five Ways to Crawl a Website” description=”Five Ways to Crawl a Website” player-type=”collapse” override-embed=”true”]
- HTTrack
- Cyotek WebCopy
- Content Grabber
- ParseHub
- OutWit Hub
HTTrack
HTTrack is a free and open source software used to download data from websites on the internet. It is an easy-to-use software developed by Xavier Roche. The downloaded data is stored on localhost in the same structure as was on the original website. The procedure to use this utility is as follows:
First, install HTTrack on your machine by running the following command:
After installing the software, run the following command to crawl the website. In the following example, we will crawl linuxhint.com:
The above command will fetch all the data from the site and save it in the current directory. The following image describes how to use httrack:

From the figure, we can see that the data from the site has been fetched and saved in the current directory.
Cyotek WebCopy
Cyotek WebCopy is a free web crawling software used to copy contents from a website to the localhost. After running the program and providing the website link and destination folder, the entire site will be copied from given URL and saved in the localhost. Download Cyotek WebCopy from the following link:
https://www.cyotek.com/cyotek-webcopy/downloads
Following installation, when the web crawler is run, the window pictured below will appear:

Upon entering the URL of the website and designating the destination folder in the required fields, click on copy to begin copying the data from site, as shown below:
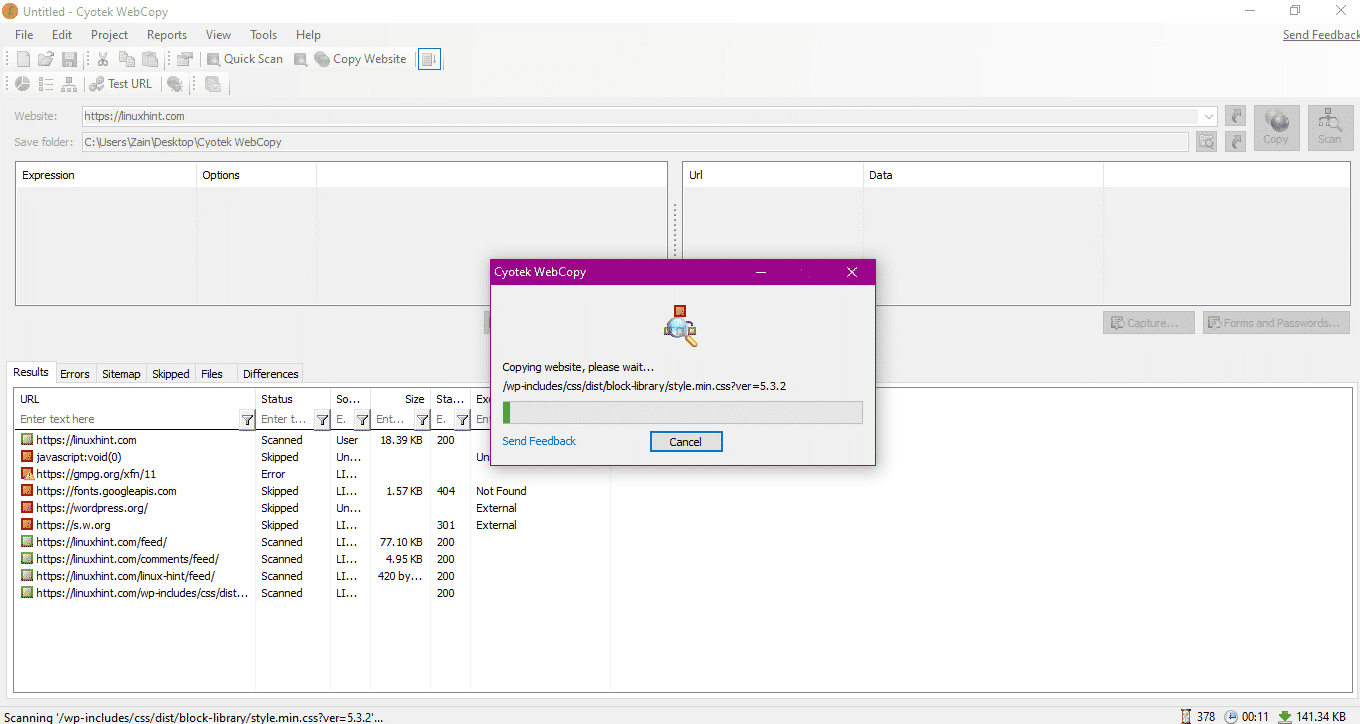
After copying the data from the website, check whether the data has been copied to the destination directory as follows:

In the above image, all of the data from the site has been copied and saved in the target location.
Content Grabber
Content Grabber is a cloud based software program which is used to extract data from a website. It can extract data from any multi structure website. You can download Content Grabber from following link
http://www.tucows.com/preview/1601497/Content-Grabber
After installing and running the program, a window appears, as shown in the following figure:

Enter the URL of the website from which you want to extract data. After entering the URL of the website, select the element you want to copy as shown below:
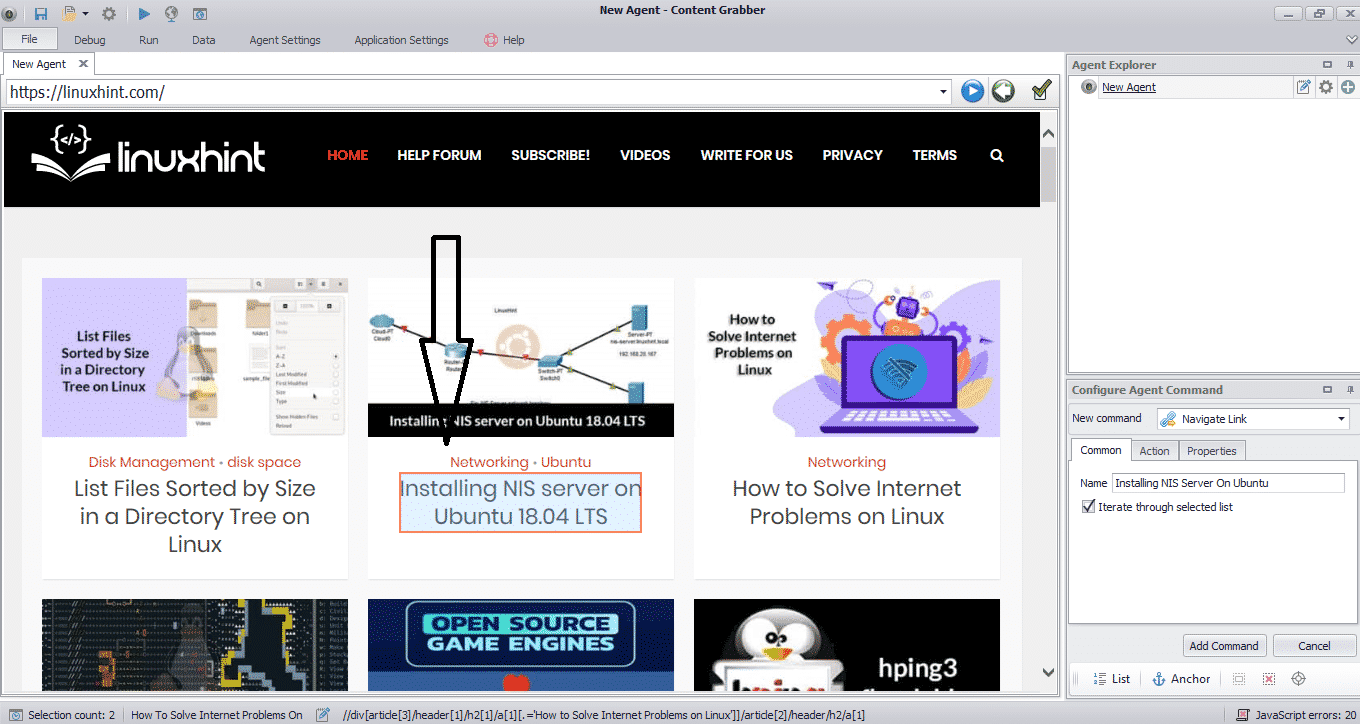
After selecting the required element, begin copying data from the site. This should look like the following image:
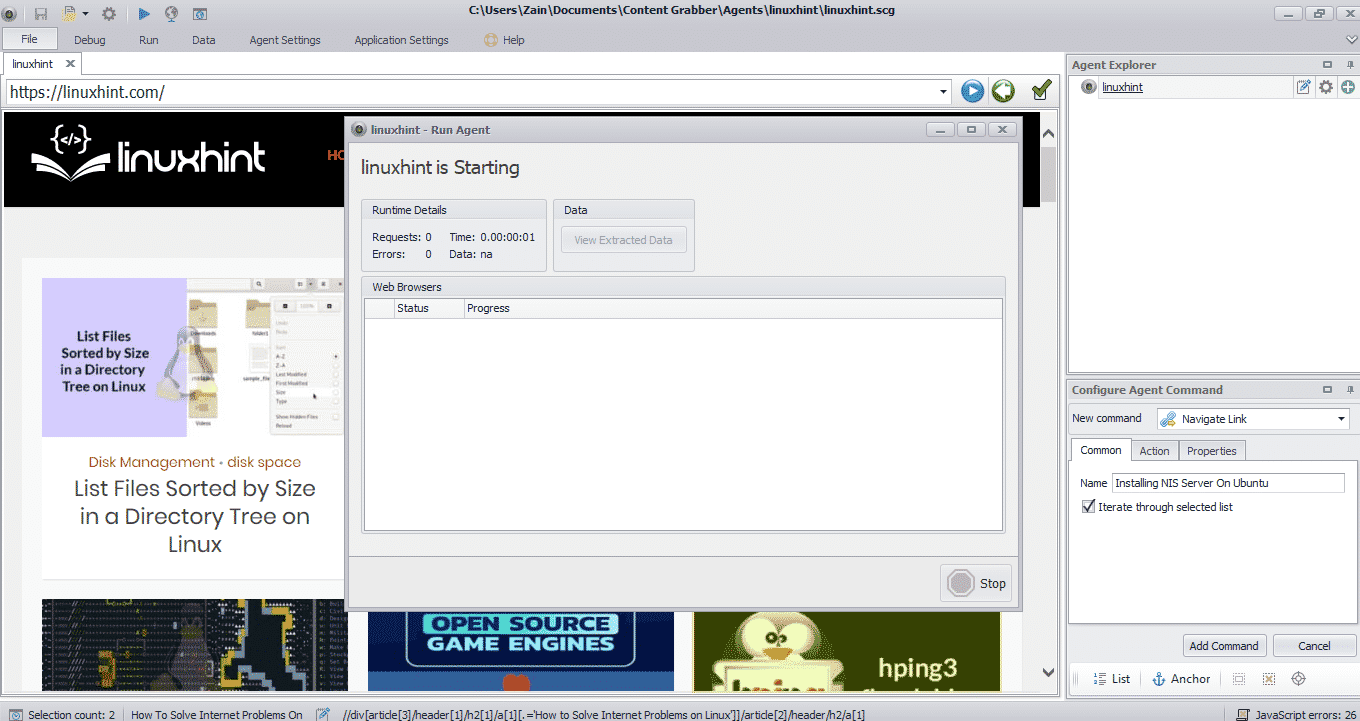
The data extracted from a website will be saved by default in the following location:
ParseHub
ParseHub is a free and easy-to-use web crawling tool. This program can copy images, text and other forms of data from a website. Click on the following link to download ParseHub:
https://www.parsehub.com/quickstart
After downloading and installing ParseHub, run the program. A window will appear, as shown below:

Click on “New Project,” enter the URL in the address bar of the website from which you wish to extract data, and press enter. Next, click on “Start Project on this URL.”
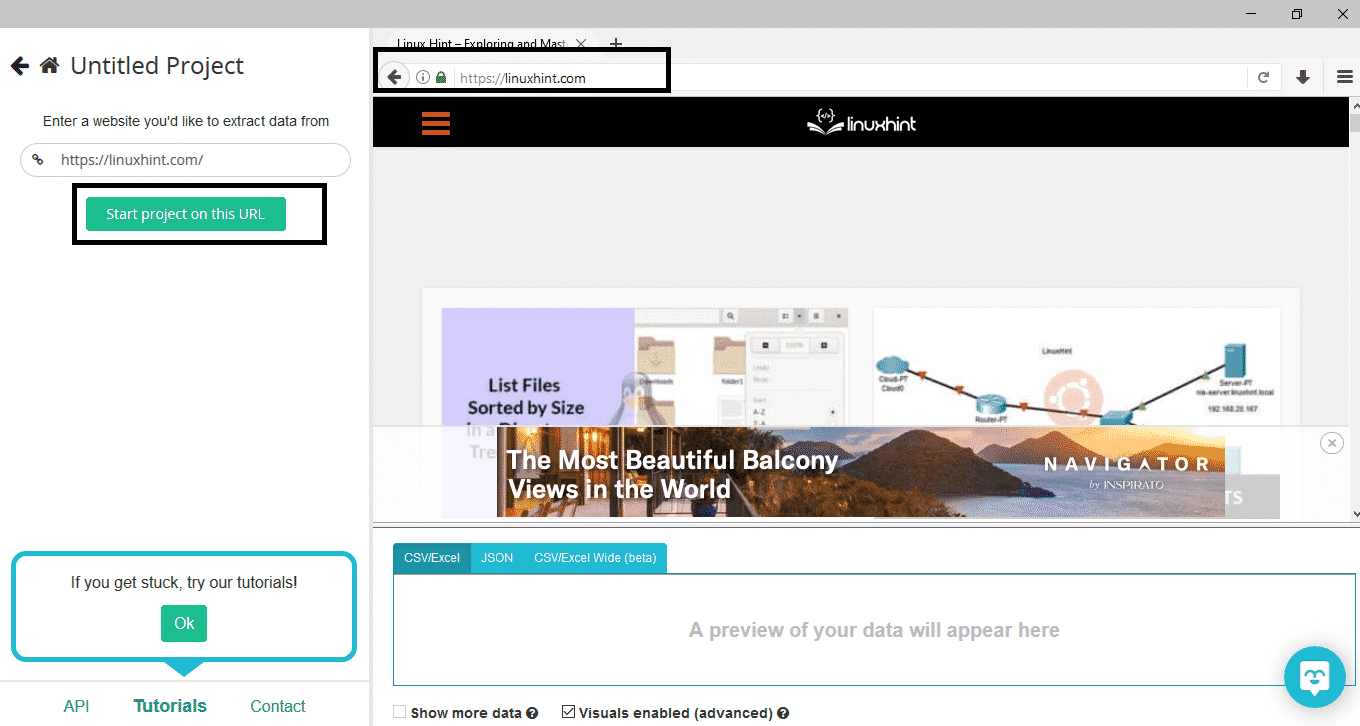
After selecting the required page, click on “Get Data” on the left side to crawl the webpage. The following window will appear:

Click on “Run” and the program will ask for the data type you wish to download. Select the required type and the program will ask for the destination folder. Finally, save the data in the destination directory.
OutWit Hub
OutWit Hub is a web crawler used to extract data from websites. This program can extract images, links, contacts, data, and text from a website. The only required steps are to enter the URL of the website and select the data type to be extracted. Download this software from the following link:
https://www.outwit.com/products/hub/
After installing and running the program, the following window appears:
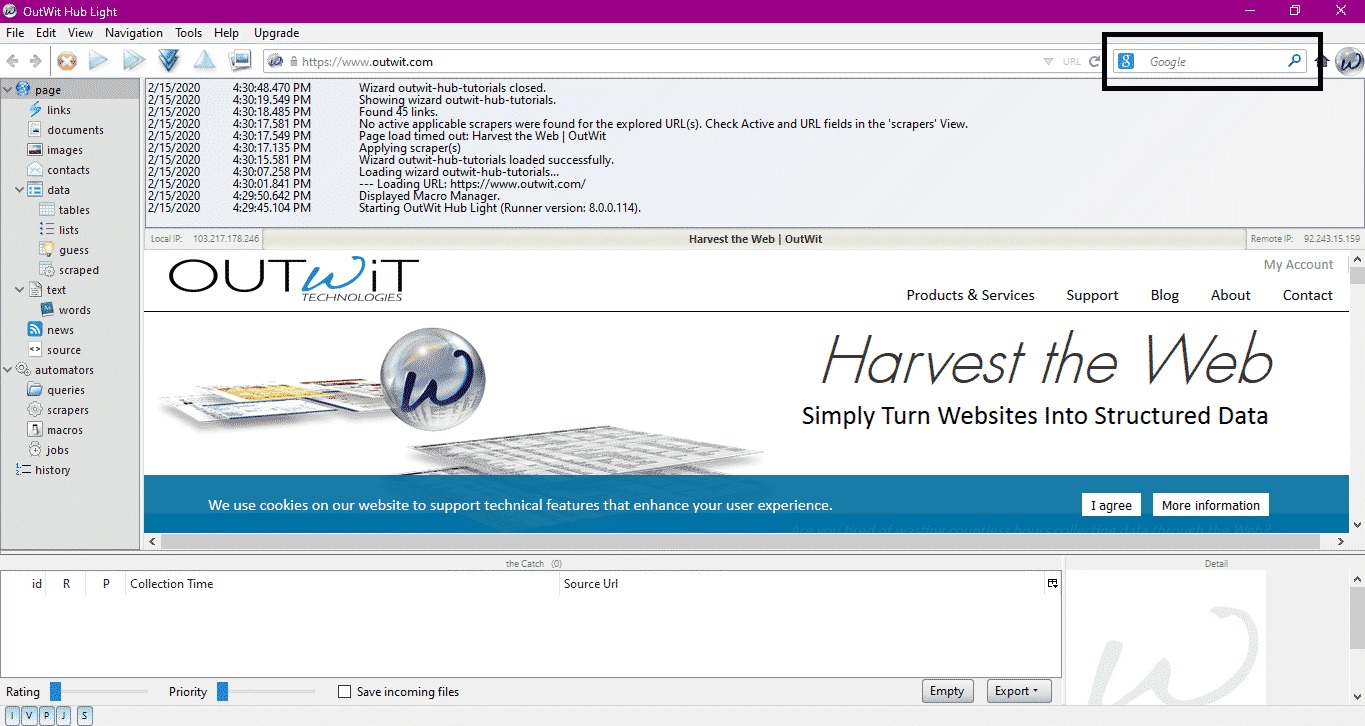
Enter the URL of the website in the field shown in the above image and press enter. The window will display the website, as shown below:
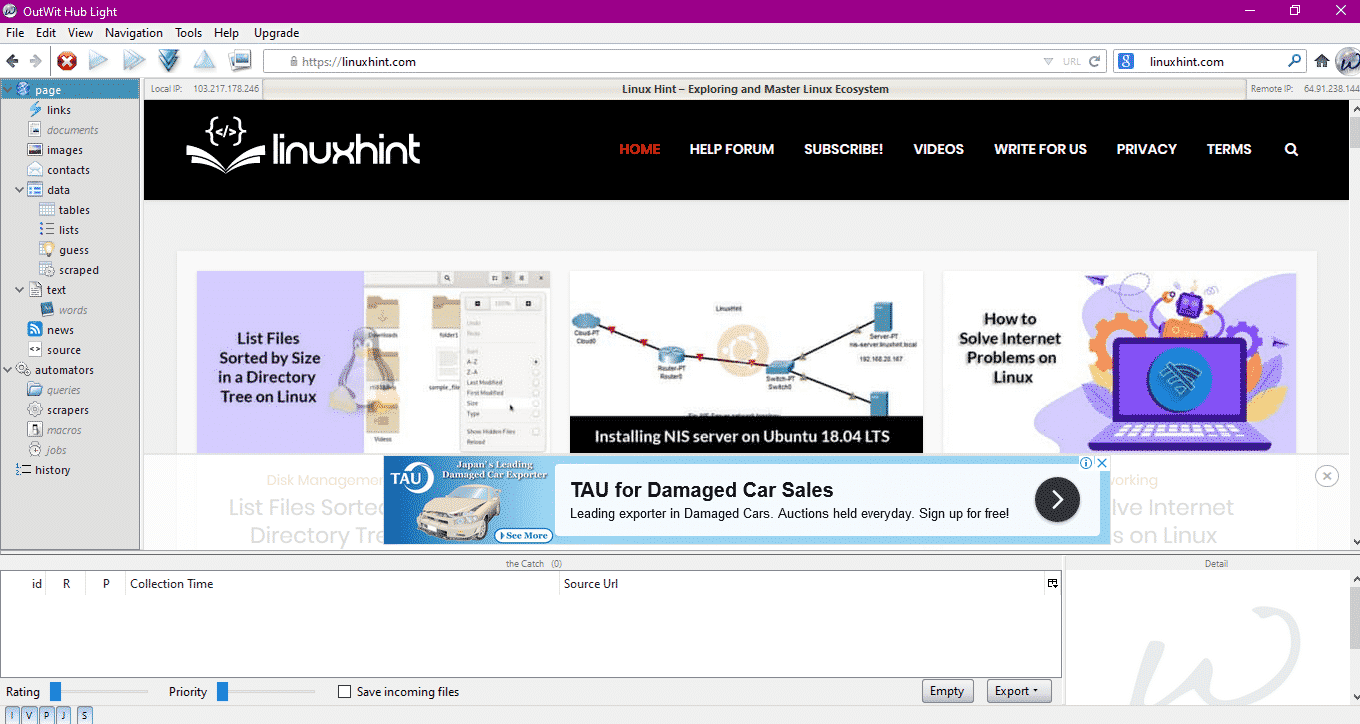
Select the data type you wish to extract from the website from the left panel. The following image illustrates this process precisely:

Now, select the image you wish to save on the localhost and click on the export button marked in the image. The program will ask for the destination directory and save the data in the directory.
Conclusion
Web crawlers are used to extract data from websites. This article discussed some web crawling tools and how to use them. The usage of each web crawler was discussed step by step with figures where necessary. I hope that after reading this article, you will find it easy to use these tools to crawl a website.