While working with large data in Python, we sometimes need to analyze data for various purposes. In the analyzing process, we split the data based on the groups and performed certain operations on it. The “groupby()” method in Python is utilized to accomplish this operation. This method groups the data based on single or multiple columns or other values and applies certain methods to it.
This write-up will deliver you a detailed guide on Pandas “DataFrame.groupby()” method using this contents:
What is the “DataFrame.groupby()” Method in Python?
The “DataFrame. groupby()” method in Python is utilized to group the Pandas DataFrame data according to the particular condition. This method can be used to partition the DataFrames into groups and then apply the method to each group.
Syntax
Parameters
Based on the previously provided syntax:
-
- The “by” parameter represents the mapping function that is used to specify the grouping criteria.
- The “axis” parameter represents the axis “0” or “1” along which to group.
- The “level” parameter is utilized to indicate the level or levels of Multiindex to group by.
- The “as_index” parameter indicates whether to yield an object with group name/labels as the index.
- The “sort” parameter is used to specify whether to sort the group keys.
To get a comprehensive overview of the syntax, please refer to this official guide.
Return Value
The “DataFrame.groupby()” method retrieves the groupby object.
Example 1: Using the “DataFrame.groupby()” Method to Group the Data Based on a Specified Column
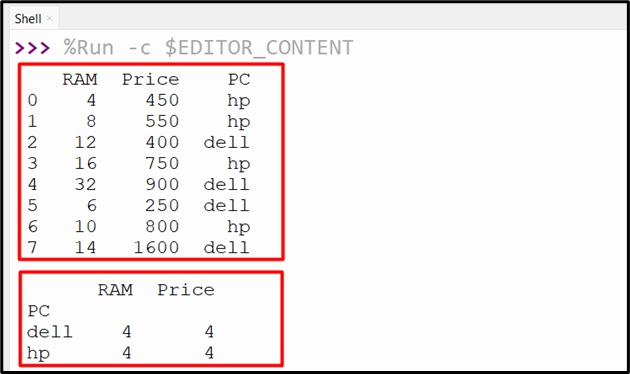
In the below code, first, we create the DataFrame and then apply the “groupby()” method on the specific column name to group the data. After grouping the data, the “count()” method is applied to the group data and finds the total element value:
data = {'RAM': [4, 8, 12, 16, 32, 6, 10, 14],
'Price': [450, 550, 400, 750, 900, 250, 800, 1600],
'PC': ['hp', 'hp', 'dell', 'hp', 'dell', 'dell', 'hp', 'dell']}
df = pandas.DataFrame(data)
print(df, '\n')
print(df.groupby(["PC"]).count())
The below output shows the total count of the grouped data:
Example 2: Using the “DataFrame.groupby()” Method to Group the Data According to the Multiple Column
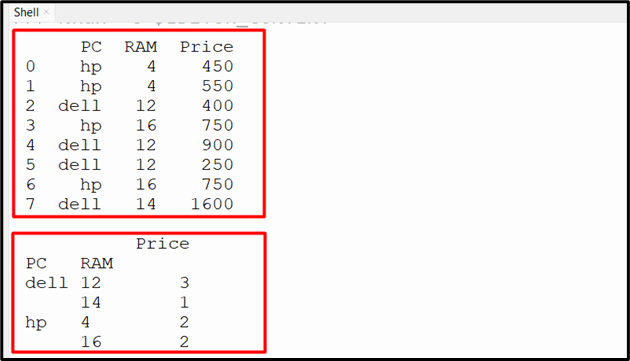
The “DataFrame.groupby()” method can also be used to group the data on multiple columns of DataFrame. After grouping the data on multiple columns the “count()” method is applied to the group data and retrieves the total count of the specified column value:
data = {'PC': ['hp', 'hp', 'dell', 'hp', 'dell', 'dell', 'hp', 'dell'],
'RAM': [4, 4, 12, 16, 12, 12, 16, 14],
'Price': [450, 550, 400, 750, 900, 250, 750, 1600]}
df = pandas.DataFrame(data)
print(df, '\n')
print(df.groupby(["PC", 'RAM']).count())
The following code is used to group the data based on the multiple column’s value:
Example 3: Using the “DataFrame.groupby()” Method to Group the Data According to the Index Column
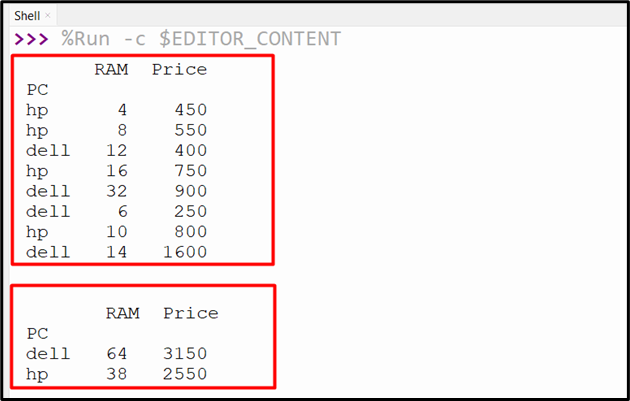
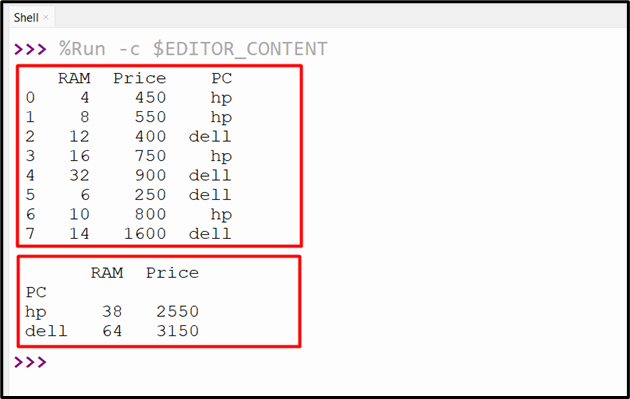
In the below code, the “DataFrame.groupby()” method is utilized to group the DataFrame columns data according to the index. First, we need to set the index for the DataFrame using the “DataFrame.set_index()” method. After that, the “DataFrame.groupby()” method is used to group the data based on the specified index and apply the “sum()” method to that data:
data = {'RAM': [4, 8, 12, 16, 32, 6, 10, 14],
'Price': [450, 550, 400, 750, 900, 250, 800, 1600],
'PC': ['hp', 'hp', 'dell', 'hp', 'dell', 'dell', 'hp', 'dell']}
df = pandas.DataFrame(data)
df.set_index(['PC'], inplace=True)
print(df, '\n')
result = df.groupby('PC').sum()
print('\n',result)
The below output shows the execution of the above code:
Example 4: Using the “DataFrame.groupby()” and “apply()” Methods to Apply the Function to Group Data
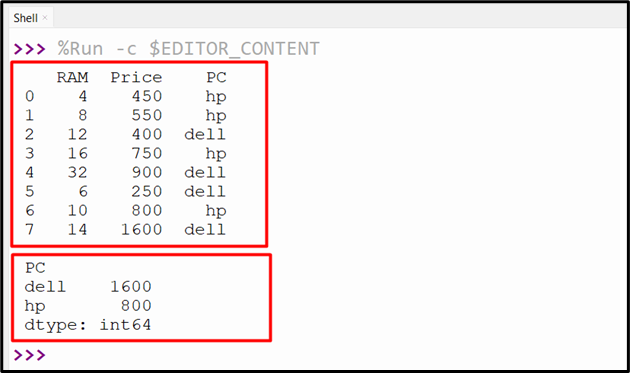
In the provided code, the “DataFrame.groupby()” method is employed along with the “apply()” method to apply the function to group/combine data. The “apply()” method applies the “max()” method to each “Price” column value based on the group data:
data = {'RAM': [4, 8, 12, 16, 32, 6, 10, 14],
'Price': [450, 550, 400, 750, 900, 250, 800, 1600],
'PC': ['hp', 'hp', 'dell', 'hp', 'dell', 'dell', 'hp', 'dell']}
df = pandas.DataFrame(data)
print(df, '\n')
df1 = df.groupby('PC').apply(lambda x: x['Price'].max())
print(df1)
The below output shows the maximum value based on the group data:
Example 5: Using the “DataFrame.groupby()” Method to Sort the Group Data
We can also sort the group data using the “sort=” parameter of the “DataFrame.groupby()” method. In the below code, first, we create the DataFrame, then apply the “df.groupby()” method with the sort parameter along with the “sum()”. The combinations of these methods retrieve the sum value in descending order based on the group data:
data = {'RAM': [4, 8, 12, 16, 32, 6, 10, 14],
'Price': [450, 550, 400, 750, 900, 250, 800, 1600],
'PC': ['hp', 'hp', 'dell', 'hp', 'dell', 'dell', 'hp', 'dell']}
df = pandas.DataFrame(data)
print(df, '\n')
df1=df.groupby(by=['PC'], sort=False).sum()
print(df1)
The above code retrieves the below output:
Conclusion
The “DataFrame.groupby()” method in Python is employed to group the DataFrame of Pandas according to the particular/specified condition. We can use this method along with other methods to group the data according to specified columns, index columns, and others. We can also use the “sort=” parameter to sort the group data resulting in ascending or descending order. This post presented a complete tutorial on Pandas “DataFrame.groupby()” method utilizing multiple examples.