Fuzzy matching is a technique that allows determining approximate matches between strings based on their similarity. We can use this technique to find any errors in the data such as spelling errors, abbreviations, or missing information, etc. Fuzzy matching can be performed in Python using different modules and methods utilizing various algorithms.
This guide will discuss the following content:
How to Perform Pandas Fuzzy Match in Python?
Reducing Threshold Value
Example of Using Different Python fuzzywuzzy Module Function
Conclusion
How to Perform Pandas Fuzzy Match in Python?
To perform Pandas fuzzy match the following methods are used in Python:
Method 1: Perform Fuzzy Matching in Pandas Using the “get_close_matches()” Function
Method 2: Perform Fuzzy Matching in Pandas Using the “fuzzywuzzy” Module
Step 2: Converting DataFrame to List and Setting Threshold
Step 3: Iterating Over the First List to Extract the Closest Match From the Second List
Method 1: Perform Fuzzy Matching in Pandas Using the “get_close_matches()” Function
In Python, the “get_close_matches()” function of the “difflib” module is used to find a list of good enough matches for a particular word in a given list of possibilities. This method can also be utilized to perform/execute fuzzy matching of two Pandas DataFrame while merging. Take this code as an example:
import difflib
# create two DataFrames
df1 = pandas.DataFrame({'country': ['USA', 'China', 'India', 'Brazil', 'Russia'],
'population': [331, 1441, 1380, 213, 146]})
print(df1, '\n')
df2 = pandas.DataFrame({'country': ['US', 'Chin', 'Indi', 'Brazl', 'Rusia'],
'gdp': [21.4, 14.9, 2.9, 1.8, 1.7]})
print(df2, '\n')
# use fuzzy matching to find the closest matches
df2['country_match'] = df2['country']
df2['country'] = df2['country'].apply(lambda x: difflib.get_close_matches(x, df1['country'], n=1)[0])
df3 = df1.merge(df2)
print(df3)
In the above code:
-
- We first imported two libraries: “pandas” and “difflib”.
- Next, we created two DataFrame. The first DataFrame contains two columns named “country” and “population”.
- Similarly, the second DataFrame is created with two columns named “country” and “gdp”.
- After creating DataFrame, we now use the fuzzy matching techniques to find the closest matches between the country column values of both DataFrame.
- We use the “difflib.get_close_matches()” function to apply the fuzzy matching techniques.
- After that, the two DataFrame merged using the “df.merge()” method and displayed to output.
Output
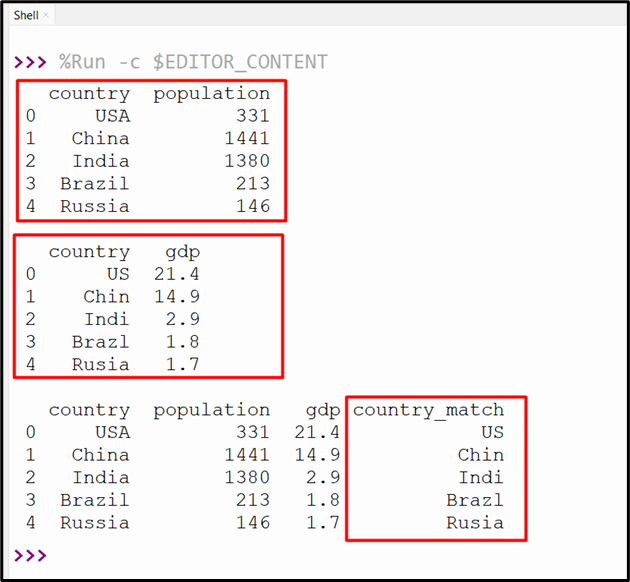
The Two DataFrame has been merged based on the closest match of the column “country”. The “country_match” column displays the value of the second DataFrame that most closely matches the value of the specified column of the First DataFrame.
Method 2: Perform Fuzzy Matching in Pandas Using the “fuzzywuzzy” Module
We can also use the “fuzzywuzzy” module to compare two DataFrames. The following steps will provide you with a step-by-step guide on how to perform fuzzy matching in Pandas:
Step 1: Create DataFrame
Firstly, we need to import the “pandas” along with the “fuzz” and “process” modules from the “fuzzywuzzy”. Then we create the two DataFrame. The first DataFrame contains the correct name of the country while the second DataFrame contains the names slightly misspelled.
import pandas
df1 = pandas.DataFrame({'country': ['USA', 'China', 'India', 'Brazil', 'Canada'],
'population': [331, 1441, 1380, 213, 146]})
print(df1, '\n')
df2 = pandas.DataFrame({'country': ['US', 'Chin', 'Indi', 'Brazl', 'Cnda'],
'gdp': [21.4, 14.9, 2.9, 1.8, 1.7]})
print(df2, '\n')
Step 2: Converting DataFrame to List and Setting Threshold
After creating DataFrames, we now create three empty lists for storing the result of fuzzy marching. Next both the columns of the given DataFrame are converted into a list using the “tolist()” method. We also assign the threshold for the matching score. The threshold value indicates that the fuzzy matching occurs when the string is 80% close to each other.
list1 = df1['country'].tolist()
list2 = df2['country'].tolist()
threshold = 80
Step 3: Iterating Over the First List to Extract the Closest Match From the Second List
The next step is to loop through each element of the previously created “list1”. During iteration, the “process.extract()” function is used to find the two best matches from the list2. The “append()” method appends the matches and their scores to the empty list “L1” as the list of tuples. Lastly, we added a new column “country_match” with “L1” values.
L1.append(process.extract(i, list2, limit=2))
df1['country_match'] = L1
Step 4: Iterate Through Matches
Now, we perform an iteration on the list of tuples and check whether the score of each tuple is greater than or equal to the threshold. If the threshold is greater than the matched country names is appended to the empty list “p”. After appending, it joins all the elements of the “p” empty list with a comma separator and appends it to another empty list “L2”. The “p” list is empty again and ready for the next iteration. In the end, we assigned the values of L2 to the DataFrame column “country_match”, which replaced the tuples list value.
for k in j:
if k[1] >= threshold:
p.append(k[0])
L2.append(",".join(p))
p = []
df1['country_match'] = L2
print(df1)
Complete Example Code
All the previous steps are gathered and are executed in Python at once:
import pandas
df1 = pandas.DataFrame({'country': ['USA', 'China', 'India', 'Brazil', 'Canada'],
'population': [331, 1441, 1380, 213, 146]})
print(df1, '\n')
df2 = pandas.DataFrame({'country': ['US', 'Chin', 'Indi', 'Brazl', 'Cnda'],
'gdp': [21.4, 14.9, 2.9, 1.8, 1.7]})
print(df2, '\n')
L1, L2, p = [], [], []
list1 = df1['country'].tolist()
list2 = df2['country'].tolist()
threshold = 80
for i in list1:
L1.append(process.extract(i, list2, limit=2))
df1['country_match'] = L1
for j in df1['country_match']:
for k in j:
if k[1] >= threshold:
p.append(k[0])
L2.append(",".join(p))
p = []
df1['country_match'] = L2
print(df1)
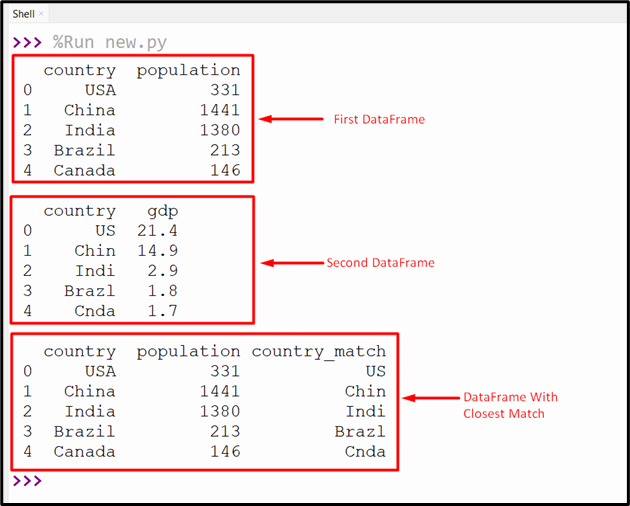
The above code displays the following output:
Reducing Threshold Value
When we reduce the threshold value, the fuzzy matching will match the find the value that is 50% close to each other. Let us take this code as an example:
import pandas
df1 = pandas.DataFrame({'country': ['USA', 'China', 'India', 'Brazil', 'Canada'],
'population': [331, 1441, 1380, 213, 146]})
print(df1, '\n')
df2 = pandas.DataFrame({'country': ['US', 'Chin', 'Indi', 'Brazl', 'Cnda'],
'gdp': [21.4, 14.9, 2.9, 1.8, 1.7]})
print(df2, '\n')
L1, L2, p = [], [], []
list1 = df1['country'].tolist()
list2 = df2['country'].tolist()
threshold = 50
for i in list1:
L1.append(process.extract(i, list2, limit=2))
df1['country_match'] = L1
for j in df1['country_match']:
for k in j:
if k[1] >= threshold:
p.append(k[0])
L2.append(",".join(p))
p = []
df1['country_match'] = L2
print(df1)
The below output shows multiple closest values based on the threshold. Any value that is 50% close to each other in fuzzy matching will retrieve to output:

Example of Using Different Python fuzzywuzzy Module Function
The “fuzzywuzzy” Python library provides distinct functions for measuring the similarity between two strings. These functions include “fuzz.ratio()”, “fuzz.partial_ratio()”, “fuzz.token_sort_ratio()” and “fuzz.token_set_ratio()” They use different methods to determine the edit distance or the number of operations required to transform/convert a specified string into another. Let us examine these functions:
-
- “fuzz.ratio” Function: It is used to determine the similarity ratio between the given two strings according to the Levenshtein distance.
- “fuzz.partial_ratio” Function: it is used to find the best matching substring of the longer/greater string and compare it to the shorter string.
- “fuzz.token_sort_ratio” Function: It is used to sort the token in each string by determining the similarity ratio.
- “Fuzz.token_set_ratio” Function: it tries to rule out the difference in the strings by creating three sets of tokens: intersection, difference, and the union of two input strings. It then compared each set and retrieved the highest score.
Now, let’s assign the “scorer=fuzz.ratio” value to the “process.extract()” method in the precious code:
import pandas
df1 = pandas.DataFrame({'country': ['USA', 'China', 'India', 'Brazil', 'Canada'],
'population': [331, 1441, 1380, 213, 146]})
print(df1, '\n')
df2 = pandas.DataFrame({'country': ['US', 'Chin', 'Indi', 'Brazl', 'Cnda'],
'gdp': [21.4, 14.9, 2.9, 1.8, 1.7]})
print(df2, '\n')
L1, L2, p = [], [], []
list1 = df1['country'].tolist()
list2 = df2['country'].tolist()
threshold = 50
for i in list1:
L1.append(process.extract(i, list2, scorer=fuzz.ratio))
df1['country_match'] = L1
for j in df1['country_match']:
for k in j:
if k[1] >= threshold:
p.append(k[0])
L2.append(",".join(p))
p = []
df1['country_match'] = L2
print(df1)
The output will look like this:

When using “scorer=partial_ratio” in the “process.extract()” method of the previous code, we retrieve this output:

Conclusion
The “get_close_matches()” function and the “fuzzywuzzy” module are used to perform fuzzy matching of two Pandas DataFrame in Python. The “get_close_matches()” function finds the closest match of two DataFrame and merges it using the “DataFrame.merge()” method. Similarly, the “fuzzywuzzy” library provides several “fuzz” and “process” modules to perform the fuzzy matching technique. This tutorial provided a complete overview of Pandas’ fuzzy match using several examples.