Data compression is an approach that is used to reduce the size of data by eliminating/removing the encoding information more efficiently. It is useful for several reasons, such as saving disk space, improving performance, and enhancing security. In Python, the “zlib” library is used for performing data compression and decompression of strings or files.
The following contents will be discussed in this guide to provide an overview of the Python “zlib” library:
What is the “zlib” Library in Python?
- Example 1: Compress String Data Using “zlib.compress()” Function
- Example 2: Decompress String Data Using “zlib.decompress()” Function
- Example 3: Compress the File Data Using “zlib.compress()” Function
- Example 4: Decompress the File Data Using “zlib.decompress()” Function
- Example 5: Compress Large Stream Data Using “compressobj()” Function
- Example 6: Decompress Large Stream Data Using “zlib.decompressobj()” Function
- Example 7: Writing Compress Data to File
What is the “zlib” Library in Python?
The “zlib” is a Python library that provides the “zlib” C library interface, as it is a higher-level generalization for deflating lossless compression algorithms. The “zlib” library is used with the gzip file tool/format. It can also be used for data compression and decompression of binary strings, files, or streams of data with various options in Python.
Python “zlib” Functions
In Python, the “zlib” library provides various sets of functions for file compression and decompression using the zlib format. The “compress()” and “decompress()” functions are normally used for small data, whereas the “compressobj()” and “decompressobj()” functions are used with large data streams. Let’s begin with the below/following example:
Example 1: Compress String Data Using “zlib.compress()” Function
The “zlib.compress()” function of the “zlib” module is used to compress string data based on the compression level.
Syntax
Parameter
In this syntax, the “data” specifies the data required to compress, while the “level” specifies the compression level to apply to the data.
Let’s get started with below code:
import binascii
str1 = b'Welcome to Python Guide!'
print('Original data: ', str1)
com_str = zlib.compress(str1, 2)
print('Compressed data: ', binascii.hexlify(com_str))
In the above code:
- We first imported the “zlib” and “binascii” modules.
- After that, the binary byte string containing binary data is declared in the program.
- Next, the “zlib.compress()” method takes two arguments “Input String” and “Compression level (2)”. The level of the compression normally ranges from “0” to “9”.
- The “zlib.compress()” function retrieves a byte string that contains the compressed data.
- Finally, we use the “binascii.hexlify()” method to convert the byte string compressed data into hexadecimal representation.
Output
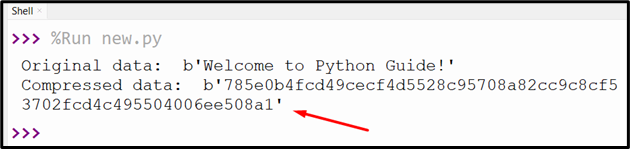
The compressed data has been represented as a hexadecimal representation.
Let’s consider another example, in which we are finding the length of the input byte string and compressed byte string:
str1 = b'Welcome to Python Guide!'
print(len(str1))
# using zlib.compress()
print(len(zlib.compress(str1)))
Here, the “zlib.compress()” is used with the len() function to show the compressed version length. In this case, the compressed length is slightly larger/greater than the specified string length. This is because the compression algorithm adds some overhead to store information about how to decompress the data.
Output
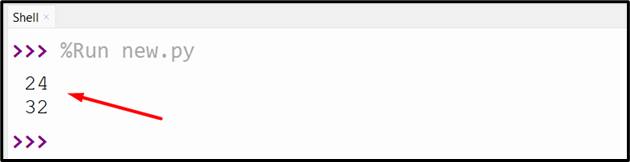
The output shows the length of the input byte string and the compressed byte string:
Example 2: Decompress String Data Using “zlib.decompress()” Function
The “zlib.decompress()” function of the “zlib” module is used to decompress the string data.
Syntax
Parameter
In this syntax, the “data” represents the byte string value. The “wbits” specify and manage the size of the buffer history, while the “bufsize” specifies the size of the buffer.
Let overview this code:
import binascii
str1 = b'Welcome to Python Guide!'
print('Original data: ', str1)
com_str = zlib.compress(str1, 2)
print('\nCompressed data: ', binascii.hexlify(com_str))
print('\nDecompressed data: ', zlib.decompress(com_str))
According to the above code:
- The required modules are imported and the byte string is initialized and compressed using the “zlib.compress()” function.
- Next, the “zlib.decompress()” is used to decompress the compressed data and retrieve the original data.
Output
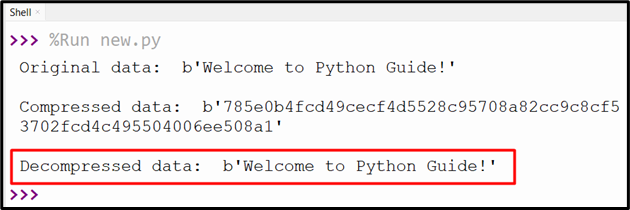
The decompression of the given compressed data has been retrieved.
Example 3: Compress the File Data Using “zlib.compress()” Function
The following example code compresses the data in a file using the “zlib.compress()” function:
data1 = open('example1.txt', 'rb').read()
com_data = zlib.compress(data1, zlib.Z_BEST_COMPRESSION)
x1 = float(len(data1))
x2 = float(len(com_data))
compress_ratio = (x1 - x2) / x1
print('Compressed: %d%%' % (100.0 * compress_ratio))
In the above code:
- Firstly, import the “zlib” module and open the files in binary mode.
- Next, use the read() method to read the file contents.
- After that, apply the “zlib.compress()” function to the given data by taking two arguments. The “1st” argument is the data to be compressed and the “2nd” argument is the compression level. The “zlib.BEST_COMPRESSION” is used as the compression level here.
- Next, we calculate the compression ratio by dividing the difference between the length of the input and compressed data by the input length of the data.
- We convert the length into floats to avoid integer division.
- In the end, the compression ratio is displayed as the percentage,
Note: The compression ratio is a measure of how much space is saved by compression. The higher/more the ratio, the more space is saved.
Output
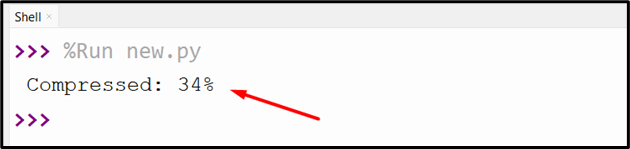
The above code displayed the compressing file size in percentage.
Example 4: Decompress the File Data Using “zlib.decompress()” Function
We can also decompress the file data using the “zlib.decompress()” function. Consider the below sample compressed file named “new.txt”:
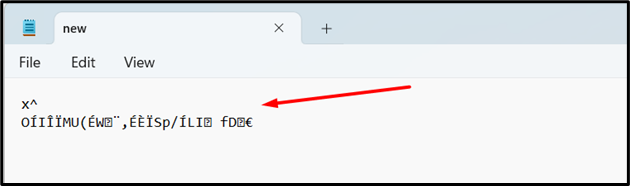
Take this code to decompress the file:
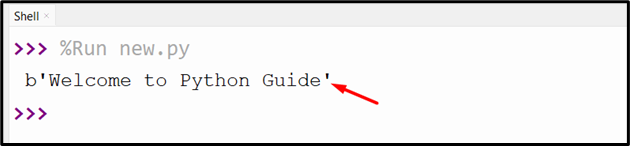
com_file = open('new.txt', 'rb').read()
print(zlib.decompress(com_file))
In this example code:
- The “open()” method is used along with the “read()” method to open the compressed file and read its content.
- Next, the “zlib.decompress()” method is used to decompress the file data and retrieve the byte string.
Output
Example 5: Compress Large Stream Data Using “compressobj()” Function
The “compressobj()” function retrieves a compression object that supports the compression of data incrementally.
Syntax
The following code is used to compress the large stream data:
import binascii
str1 = b'Welcome to Python Guide!'
print('Original data: ', str1)
com_str = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, -15)
compressed_data = com_str.compress(str1)
compressed_data += com_str.flush()
print('\nCompressed data: ', binascii.hexlify(compressed_data))
According to the above code:
- Firstly, imported the “zlib” and “binascii” modules along with the initialization of the string data.
- Next, the compression object is created using the “zlib.compressobj()” method.
- This function takes three arguments: “Z_DEFAULT_COMPRESSION”, “zlib.DEFLATED” and “-15”.
- The “Z_DEFAULT_COMPRESSION” specifies the default compression level “6”.
- The “DEFLATED” specific compression algorithm.
- Lastly, the “-15” specifies the window size, which can range from 8 to 15. The negative means no header or trailer is added to the compressed data.
- After that, we compress the data by using the “zlib.compress()” method.
- Next, we use the “flush()” method on the compression data, to retrieve the byte string that contains any remaining compressed data.
- Finally, we show the hexadecimal representation of the compressed data using the “binascii.hexlify()” method.
Output
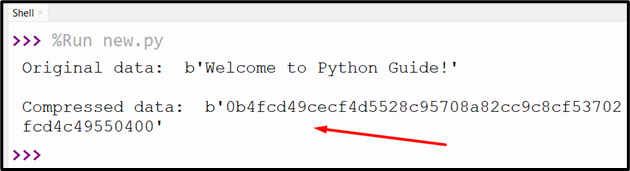
The large data stream has been compressed.
Example 6: Decompress Large Stream Data Using “zlib.decompressobj()” Function
The “zlib.decompressobj()” function is used for decompressing large stream data in Python. It decompresses single compressed streams or multiple concatenated streams in a loop. Let’s Understand it via the example code below:
str1 = b'Welcome to Python Guide'
print('Before Compress: ', str1)
compress = zlib.compressobj()
compress1 = compress.compress(str1) + compress.flush()
print('\nAfter Compress: ', compress1)
with open('compressed.dat', 'wb') as f:
f.write(compress1)
str2 = zlib.decompressobj()
with open('compressed.dat', 'rb') as my_file:
decomp = str2.decompress(my_file.read()) + str2.flush()
print('\nDecompressed Data: ', decomp)
In the above code:
- Firstly, we import the “zlib” module and initialize the byte string.
- Next, we create a “compressor object” using the “zlib.compressobj()” function. The compressor object is used for incremental compression of data.
- After that, we compress the given string data using the “compress()” function and add any remaining compressed data using the “flush()” method.
- Next, we store the compressed data in the file named “compressed.dat” using the “open()” and “write()” methods.
- The “zlib.decompressobj()” function creates the “decompressor object” and the same compressed file is opened in “rb” mode.
- Lastly, we decompress the data from the file using the decompressor object and add any remaining decompressed data by applying the “flush()” method.
Output
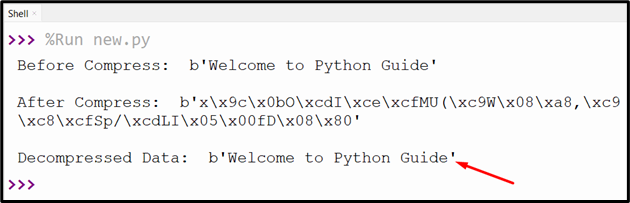
We have decompressed the large data stream.
Example 7: Writing Compress Data to File
We can also compress data to a file using the “write()” method. In the below code, we first compress the string data and open the file in “wb” mode. After that, we write the byte string data using the “write()” method and close the file.
str1 = b'Welcome to Python Guide'
comp_data = zlib.compress(str1, 2)
file1 = open('new.txt', 'wb')
file1.write(comp_data)
file1.close()
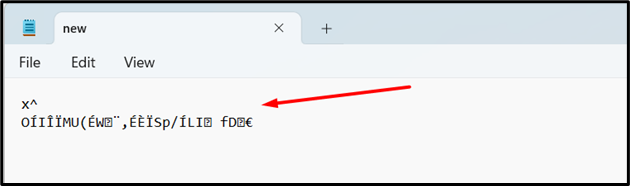
The below snippet verifies that the specified byte has been successfully written to the file:
Conclusion
In Python, the “zlib” library provides various functions such as “compress()”, “decompress()” and others to perform compression and decompression on data. The “zlib.compress()” method takes the string data or file and compresses them using a specified compression level and algorithm. Similarly, we can decompress the compressed data using the “zlib.decompress()” method. We can also employ the “zlib.compressobj()” function for compressing large data streams. This guide gave a thorough overview of the Python “zlib” library using several examples.