Chroma or ChromaDB is a relatively new embedding database to build the AI applications. It is a free and open-source embedding database with a lot of functionality to work with AI applications.
Using Chroma DB, you can perform the actions such as:
- Storing the embeddings data and corresponding metadata
- Embed documents and queries
- Search the embedding data
The following illustration shows the architecture of the Chroma database:
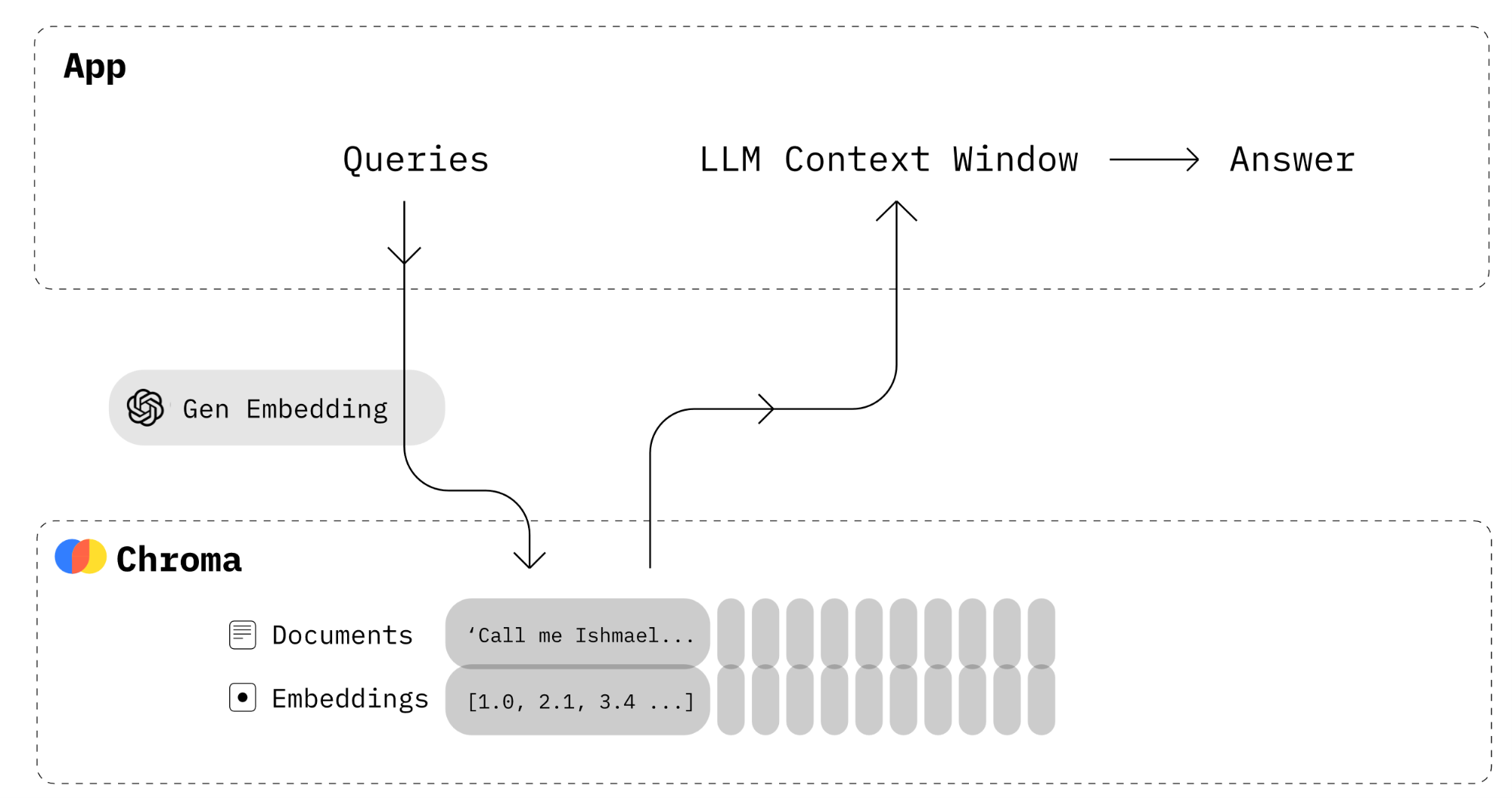
In this tutorial, we will quickly show you how you can set up a basic Chroma DB instance and use the Python SDK to create a collection and insert a sample data.
Requirements:
To follow along with this post, you need to have the following:
- Installed Python 3.10 on your machine. It may cause issues with Python 3.11 and above.
- Basic Python programming knowledge
Step 1: Install and Run Chroma
At the time of writing this tutorial, we can run Chroma DB by installing it with “pip”. It runs in-memory in alpha mode as a client-server.
Using “pip”, run the following command to install and run Chroma DB:
Step 2: Import the Chroma Client
Once you have the Chroma DB installed, we can use it in our Python project. The first step is importing the Chroma DB package and creating a client for the server.
client = chromadb.Client()
This should import the Chroma DB package and create a client that connects to the server.
Create a Collection
Once connected, we need to create a collection in the database. Think of a collection as a storage container to store the embedding.
We can accomplish this using the create_collection() method as demonstrated in the following example code:
This should create a collection under the sample_collection name.
Add a Sample Data to the Collection
The next step is to add a sample data to the created collection. We can do this using the collection.add method as demonstrated in the following example code:
documents=["sample doc 1", "sample doc 2"],
metadatas=[{"tag": "1"}, {"tag": "2"}],
ids=["id1", "id2"]
)
This code uses the “add” method to add the documents, the corresponding metadata, and the ids to the collection.
Query the Data
Finally, we can query the collection with a list of query texts, and Chroma returns the “n” most similar results.
query_texts=["sample"],
n_results=2
)
This should return the top 2 most similar results.
Conclusion
In this fundamentals article, we explored how to install and use Chroma DB to create a collection, add sample documents, and query the stored embedding for the matching results.