This blog will discuss the application of beam search in transformers.
What is the Concept of Beam Search in Transformers?
The quality of the textual output is a vital point of concern when developing machine learning models for natural language processing tasks. The “Beam Search” method works to improve this quality and produce results that have a natural feel and are closer to actual human writing.
Key features of Beam Search in Transformers are listed below:
- The significant improvement in the quality of the generated text is the biggest feature of the beam-search technique.
- Maintenance of textual context is also possible by implementing the Beam Search because it can gauge the tone of the input text and respond in kind.
- The beam width is a customizable variable in beam search and it allows the users much-needed flexibility regarding the available hardware specifications.
- Versatility is also a major selling point for beam-search because it can be used in all kinds of NLP transformer models such as text generation, translation, and summarization.
How to Apply Beam-Search in Transformers?
The Beam Search technique can be applied to the “GPT-2” Transformer to increase the quality of the results produced by the model. The overall context of the entire output is improved with sentences that are interconnected and appear to properly transition between ideas.
Go through the below steps to learn how to apply beam-search in transformers:
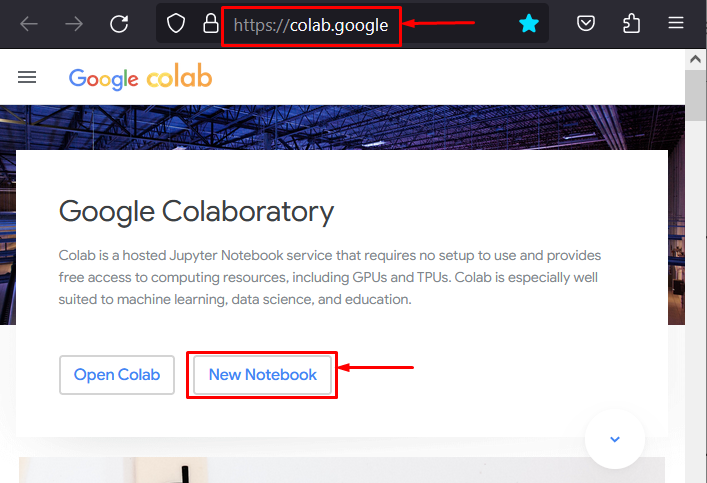
Step 1: Open the Colaboratory IDE
First launch the Google Colab IDE for development. Colab is a good choice because of the GPUs available for users free of cost. Go to the Colab website and launch a “New Notebook” to start working as shown below:
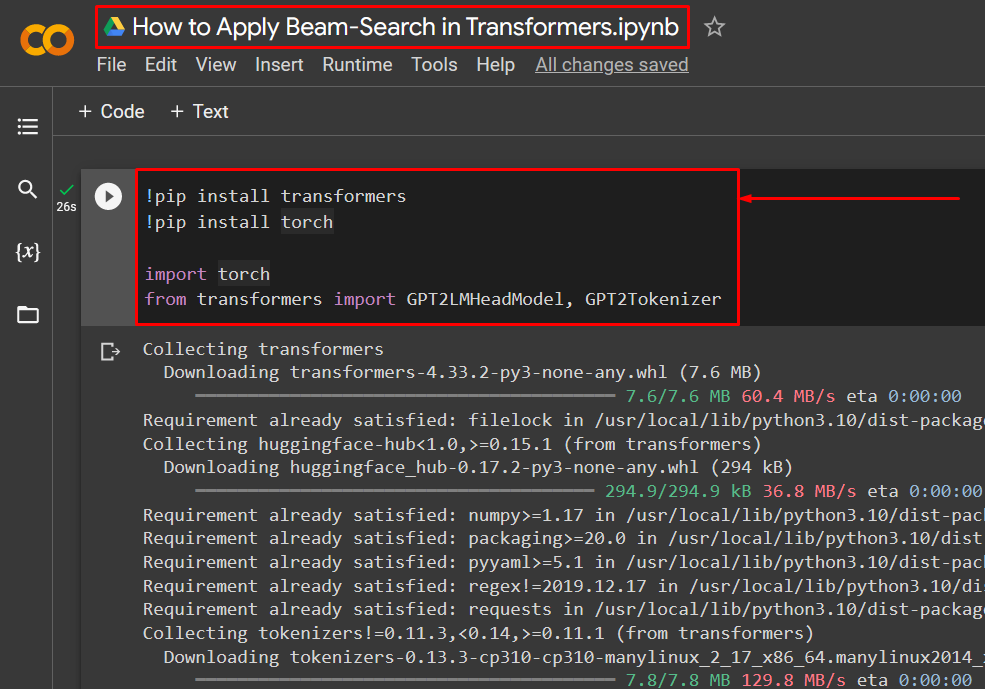
Step 2: Install and Import the Required Libraries
After having set up the Colab Notebook, the project requires the installation and import of the necessary libraries that contain the functionalities needed for transformers. Importing the proper packages ensures that no errors are faced when running the code:
!pip install torch
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
The above code works as follows:
- The Python package installer is used to install the “transformers” and the “torch” libraries.
- The “import” command is utilized to add these packages to the project.
- Lastly, the GPT-2 model and tokenizer are also imported to the project to add their functionality to the workspace:
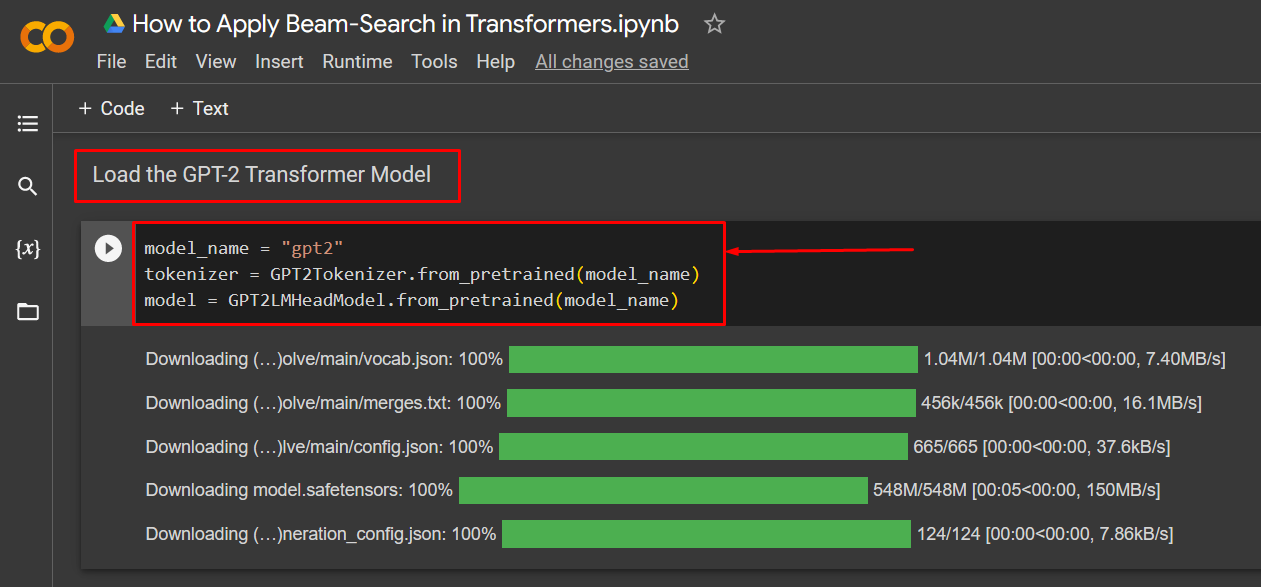
Step 3: Load the GPT-2 Transformer Model
The next step in this tutorial is to load the GPT-2 transformer model upon which the beam-search technique will be applied. This model comes pre-trained on a vast collection of input data and it is a next-generation AI model:
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
The above code works as follows:
- Add the “gpt2” model to the “model_name” variable.
- Next, define the “GPT2Tokenizer” for the transformer model using the “from_pretrained()” method and add the “model_name” variable as its argument.
- Lastly, use the “from_pretrained()” method again to define the “GPT2LMHeadModel” transformer model for use in this project:
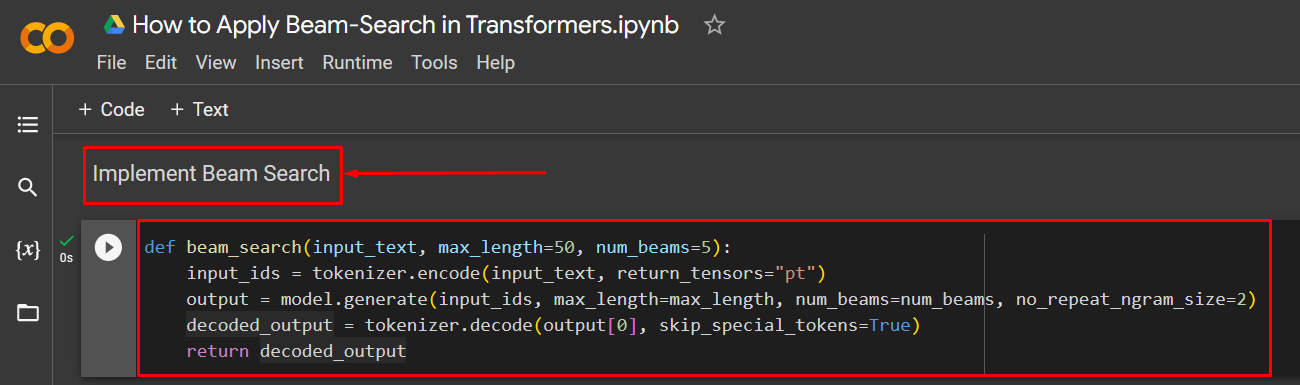
Step 4: Implement the Beam-Search Technique
Now, apply the Beam-Search technique on the GPT-2 Transformer model:
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=max_length, num_beams=num_beams, no_repeat_ngram_size=2)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
return decoded_output
The above code works as follows:
- The definition of the beam-search technique is done in this step using a “def” loop.
- The input text, maximum length, and number of beams are added as the arguments of the “beam_search()” function.
- The “encode()” function is used to tokenize the input text.
- Next, the “generate()” function is used to define the output for the model. The input variable, maximum length, and beam number are all added to its argument.
- Lastly, the “decode()” function is used with the tokenizer to produce the decoded output that is set to skip any special tokens.
- The loop is closed with the “return” statement used for the “decoded_output” variable:
Step 5: Generate Sample Text using Beam-Search
Now, test the code written in the previous steps. The generated text from using beam-search is to be assessed for its quality and coherence:
generated_text = beam_search(input_text)
print(generated_text)
The above code works as follows:
- The “input_text” variable is used to add the user-defined “prompt” for the GPT-2 Transformer model.
- Next, the “input_text” variable is added as the argument of the “beam_search()” function coded for in the previous step.
- Lastly, the “print()” method is used to print the “generated_text” output.
The output below shows the text generated by the GPT-2 transformer model with the beam-search technique applied in response to the user prompt:
The attention mask and pad token are not set because they are optional parameters. The attention mask is used to pay attention to the specific input tokens and padding maintains the sequence length.
Note: You can access our Colab Notebook at the following link.
Pro-Tip
This beam-search method can also be used in translation transformer models because of its versatility and enhanced capabilities. It is used to produce text translations that are coherent and maintain the relevant context of the original input so that no information is lost in translation.
Conclusion
To apply the beam-search in transformer models, first, load the transformer into the project, code the beam-search function, and generate the results. The technique of beam-search is very useful for programmers and data scientists to create deep learning models that can provide the best quality results. In this blog, we have showcased the method to apply the beam-search technique on the text generated by the GPT-2 Transformer model.