This post will explain what some of the best prompts are to use with Stable Diffusion 1.5 and why they work well.
- What are Prompts?
- How to Write Good Prompts for Stable Diffusion 1.5?
- What are Some Examples of Good Prompts for Stable Diffusion 1.5?
- How Does Stable Diffusion 1.5 Compare to Other Models?
What are Prompts?
Prompts are the text inputs that instruct the model for generating an image. They can be simple or complex, depending on how much detail and control you want to have over the output. Prompts can also include special tokens or symbols that modify the behavior of the model, such as changing the style, resolution, or sampling method.
How to Write Good Prompts for Stable Diffusion 1.5?
Writing good prompts is both a science and an art. There is no definitive answer to what makes a good prompt, but there are some general guidelines and tips that can help you improve your results.
A few factors that influence the quality of the prompts are:
Clarity
The prompt should be clear and unambiguous about what users like the model to generate. Avoid vague or contradictory terms that could confuse the model or lead to unwanted outputs.
Specificity
The prompt should be specific enough to capture your vision and avoid generic or bland images. However, it should not be too specific or restrictive that it limits the creativity or diversity of the model.
Length
The prompt should be concise and avoid unnecessary or redundant words that could clutter the input or distract the model. However, it should not be too short or incomplete that it misses important information or context.
Style
The prompt should match the style and tone of the model and the desired output. For example, if users wish for a realistic image, use descriptive and factual language. If you want a comic image, you should use expressive and humorous language.
Tokens
The prompt should use special tokens wisely and sparingly to enhance the output without overpowering it. For example, you can use [style:…] to change the style of the image, [res:…] to change the resolution of the image, or [sample:…] to change the sampling method of the image.
What are Some Examples of Good Prompts for Stable Diffusion 1.5?
Here are some examples of good prompts for Stable Diffusion 1.5 and why they work well:
Example 1
Let’s explore the result after writing “a cute cartoon cat wearing glasses and reading a book” in a prompt:
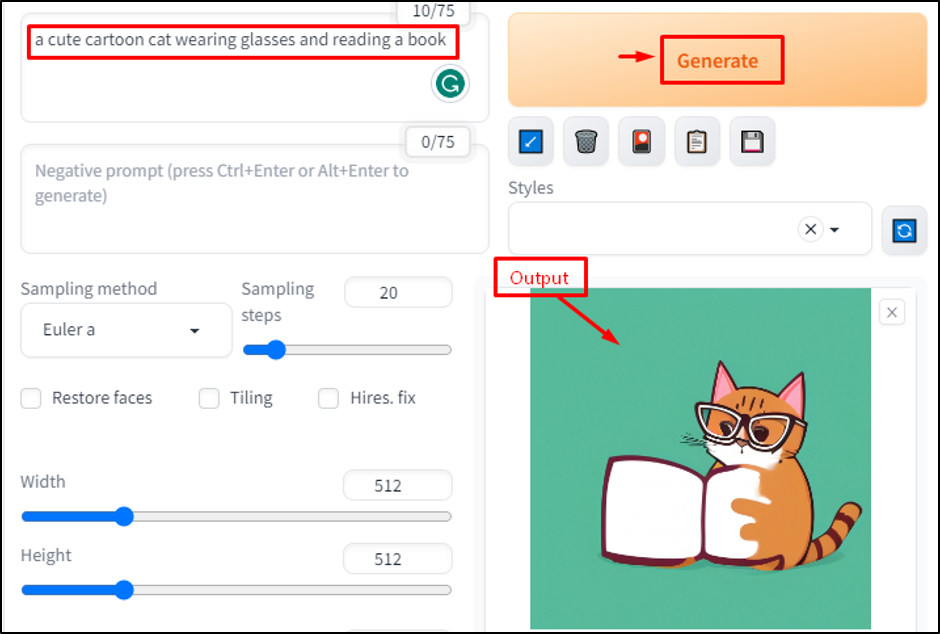
This prompt is clear, specific, concise, and matches the style of the model.
Example 2
Let’s explore another example by inputting “a realistic portrait of Albert Einstein with a funny expression” in a prompt:
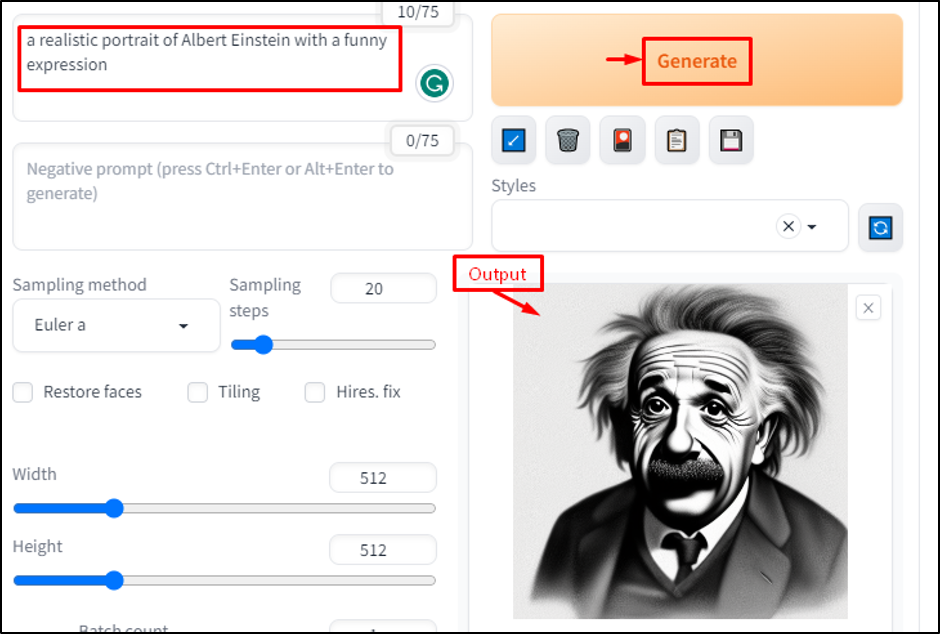
This prompt is clear, specific, concise, and matches the style of the model.
Example 3
Another example can also be considered by typing “a fantasy landscape with mountains, forests, rivers, and a castle” in a prompt window:
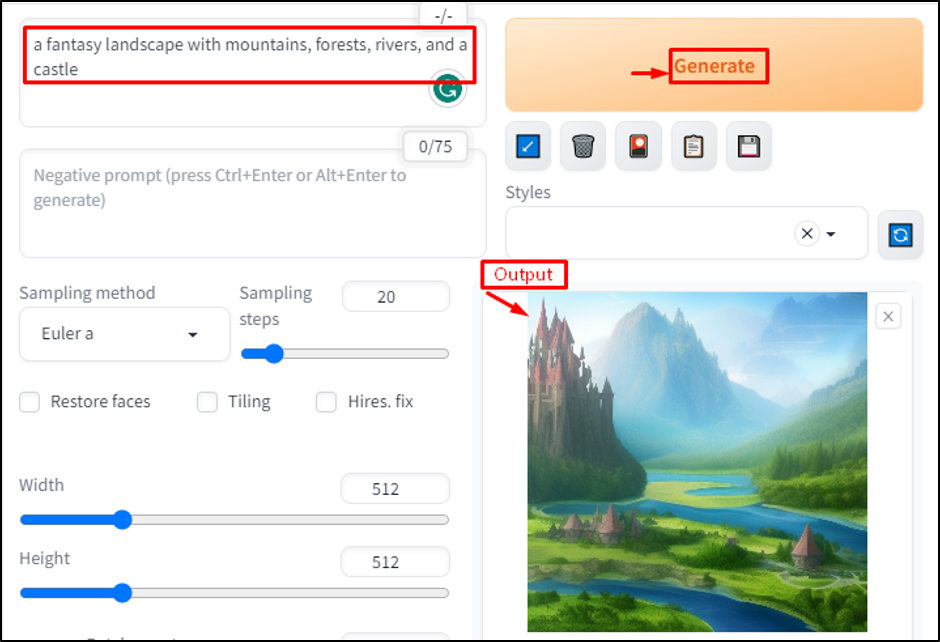
This prompt is clear, specific, concise, and matches the style of the model.
Example 4
Users can also generate some art by writing “[style:pixel art] [res:64×64] a spaceship shooting lasers at an alien” in a window:
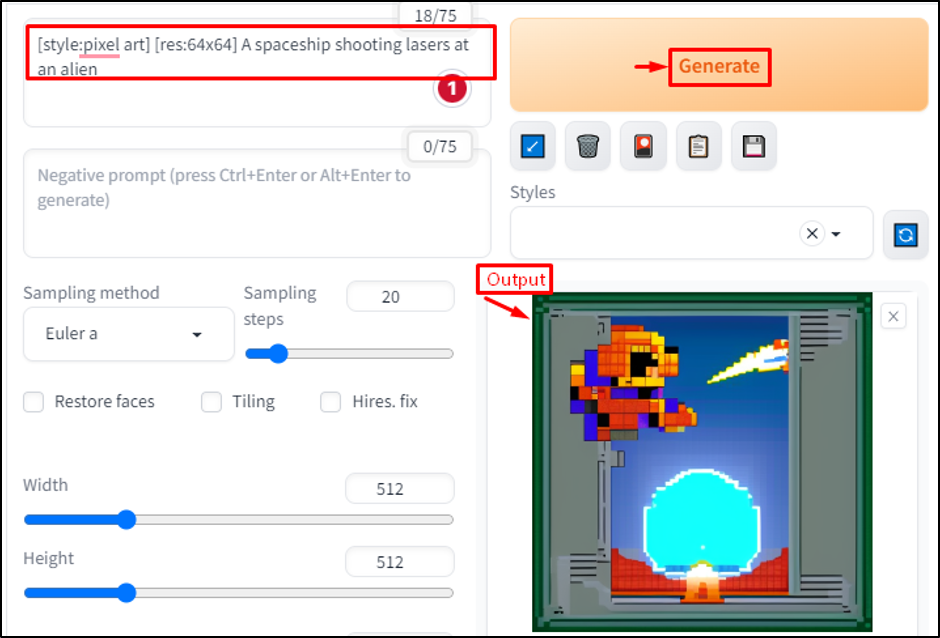
This prompt is clear, specific, and concise, and uses special tokens explicitly to change the style and resolution of the image. It also matches the style of pixel art by using words like “spaceship”, “lasers”, and “alien”.
How Does Stable Diffusion 1.5 Compare to Other Models?
Stable Diffusion 1.5 is one of the best text-to-image models available today. It can produce high-quality images that are realistic, diverse, and faithful to the prompts. It can also handle different styles, resolutions, and sampling methods with ease.
Here are some examples of how Stable Diffusion 1.5 compares to other models:
- Compared to DALL-E (a VAE-based text-to-image model), Stable Diffusion 1.5 can generate more realistic and diverse images that avoid artifacts or distortions.
- Compared to CLIP+VQGAN (a GAN-based text-to-image model), Stable Diffusion 1.5 can generate more faithful and consistent images that avoid mode collapse or repetition.
- Compared to OpenAI Codex (a transformer-based text-to-code model), Stable Diffusion 1.5 can generate more expressive and creative images that avoid syntax errors or logical flaws.
Conclusion
Stable Diffusion 1.5 is a powerful and versatile text-to-image model that can generate amazing images from natural language prompts. It is based on the diffusion framework, which models the image generation process as a reverse diffusion process, starting from a noisy image and gradually refining it until it matches the desired text description.