Let’s start with a naïve definition of ‘statelessness’ and then slowly progress to a more rigorous and real-world view.
A stateless application is one which depends on no persistent storage. The only thing your cluster is responsible for is the code, and other static content, being hosted on it. That’s it, no changing databases, no writes and no left over files when the pod is deleted.
A stateful application, on the other hand, has several other parameters it is supposed to look after in the cluster. There are dynamic databases which, even when the app is offline or deleted, persist on the disk. On a distributed system, like Kubernetes, this raises several issues. We will look at them in detail, but first let’s clarify some misconceptions.
Stateless services aren’t actually ‘stateless’
What does it mean when we say the state of a system? Well, let’s consider the following simple example of an automatic door.
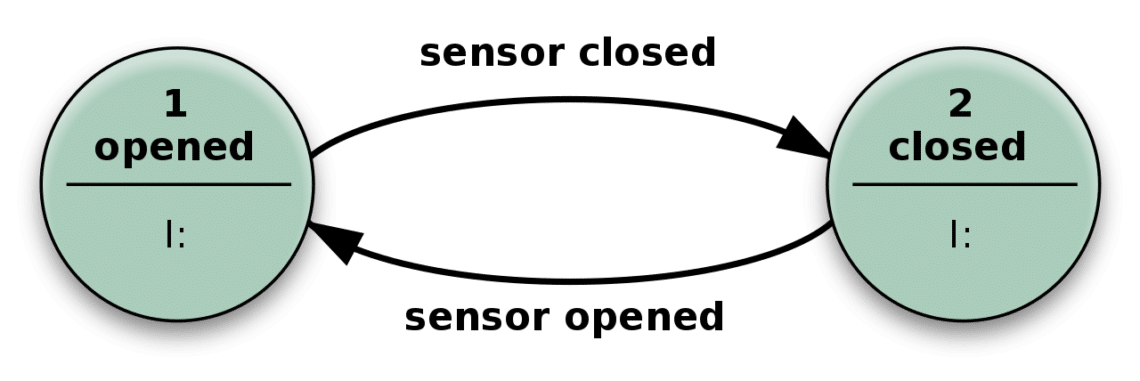
The door opens when the sensor detects someone approaching, and it closes once the sensor gets no relevant input.
In practice, your stateless app is similar to this mechanism above. It can have many more states than just closed or open, and many different types of input as well making it more complex but essentially the same.
It can solve complicated problems by just receiving an input and performing actions which depend on both the input, and ‘state’ it is in. The number of possible states are predefined.
So statelessness is a misnomer.
Stateless applications, in practice, can also cheat a little by saving details about, say, the client sessions on the client itself (HTTP cookies are a great example) and still have a nice statelessness which would make them run flawlessly on the cluster.
For example, a client’s session details like what products were saved in the cart and not checked out can all be stored on the client and the next time a session begins these relevant details are also recollected.
On a Kubernetes cluster, a stateless application has no persistent storage or volume associated with it. From an operations perspective, this is great news. Different pods all across the cluster can work independently with multiple requests coming to them simultaneously. If something goes wrong, you can just restart the application and it will go back to the initial state with little downtime.
Stateful services and the CAP theorem
The stateful services, on the other hand, will have to worry about lots and lots of edge-cases and weird issues. A pod is accompanied with at least one volume and if the data in that volume is corrupted then that persists even if the entire cluster gets rebooted.
For example, if you are running a database on a Kubernetes cluster, all the pods must have a local volume for storing the database. All of the data must be in perfect sync.
So if someone modifies an entry to the database, and that was done on pod A, and a read request comes on pod B to see that modified data, then pod B must show that latest data or give you an error message. This is known as consistency.
Consistency, in the context of a Kubernetes cluster, means every read receives the most recent write or an error message.
But this cuts against availability, one of the most important reasons for having a distributed system. Availability implies that your application functions as close to perfection as possbile, around the clock, with as little error as possible.
One may argue that you can avoid all of this if you have just one centralized database which is responsible for handling all of the persistent storage needs. Now we are back to having a single point of failure, which is yet another problem that a Kubernetes clusters is supposed to solve in the first place.
You need to have a decentralized way of storing persistent data in a cluster. Commonly referred to as network partitioning. Moreover, your cluster must be able to survive the failure of nodes running the stateful application. This is known as partition tolerance.
Any stateful service (or application), being run on a Kubernetes cluster, needs to have a balance between these three parameters. In the industry, it is known as the CAP theorem where the tradeoffs between Consistency and Availability are considered in presence of network Partitioning.
Further References
For further insight into the CAP theorem you may want to view this excellent talk given by Bryan Cantrill, who takes much closer look at running distributed systems in production.