- Experiment ID or name
- Run ID
- Parameters and Values
- Metrics and Values
- Tags
- Other attributes that are associated with the runs
Runs can be filtered by status, start time, finish time, and duration with the use of the MLflow search API. It makes it easier to filter through many runs and find specific runs that the users are interested in.
MLflow Search Function
Use the mlflow.search_runs() function to access the MLflow search API. This function accepts a variety of arguments like the following:
- The experiment ID or name
- Filter string or text
- The maximum number of runs to return is specified by the max_results argument
A simplified variant of the SQL (Structured Query Language) WHERE clause is the filter string or text. It can be used to indicate the criteria by which we want to sort the runs.
Syntax of the MLflow Search_Runs() Function
The actual ID or name of the experiment that we want to search within must be substituted for “experiment_id or experiment_name” in the following example. The search_criteria variable allows inputting the search criteria as desired. These criteria may be determined by metrics, tags, parameters, or additional characteristics. The search_runs() function’s basic syntax is as follows:
import mlflow
# Provide some Experiment id or name (it is optional; )
exp_id = "Experiment ID or NAME"
# Define the search criteria for runs
search_string = "metrics.accuracy > 0.8 AND params.learning_rate = '0.01' AND params.efficiency_rate > '80'"
# Perform the search
runs = mlflow.search_runs(experiment_ids=exp_id, filter_string=search_string)
# Display the results
print("Search Results:")
print(runs)
Run a Search Using Numerous Criteria
1. Search by Metric Value
Runs can be filtered by the values of particular metrics using the metrics field in the MLflow search API. A collection of metric names separated by commas appears in the metrics field. For instance, the following filter string locates all runs with a value of accuracy greater than 0.9:
The complete list of metrics available for usage in the metrics field is given as follows:
- accuracy
- auc
- f1
- precision
- recall
- mape
- logloss
- classification_error
- multi_class_logloss
Additionally, the users can filter the runs by a metric’s range of values using the metrics field. For instance, the next filter string locates all runs that have an accuracy measure with a value between 0.4 and 0.8:
In the metrics field, the AND and OR operators combine the metrics to find the runs with metrics accuracy and f1 values above 0.3 and 0.8:
2. Search by Parameter Value
Make use of the params field in the MLflow search API to perform a search by a parameter value. The parameter names and values are listed in the params field using commas. In this example, the aforementioned filter string locates all runs with the num_boost_round parameter that have the value of 100:
Some more examples of search strings for parameter values:
- params.num_boost_round = 900
- params.learning_rate BETWEEN 0.001 AND 0.01
- params.num_boost_round=’70’ AND params.learning_rate=’0.01′
3. Search by Tags
Here is an example of a search employing tags:
Example of the Matric and Parameter Values to Perform the Mlflow.search_runs() Function
Let’s work through an example of setting up an MLflow experiment, logging runs, and then using the mlflow.search_runs() to initiate a search. To completely understand the code, follow these steps:
Step 1: Create an MLflow Experiment
We start by setting up an MLflow experiment. It fetches the existing experiment if the experiment already exists. If not, it creates a new one.
Code Explanation:
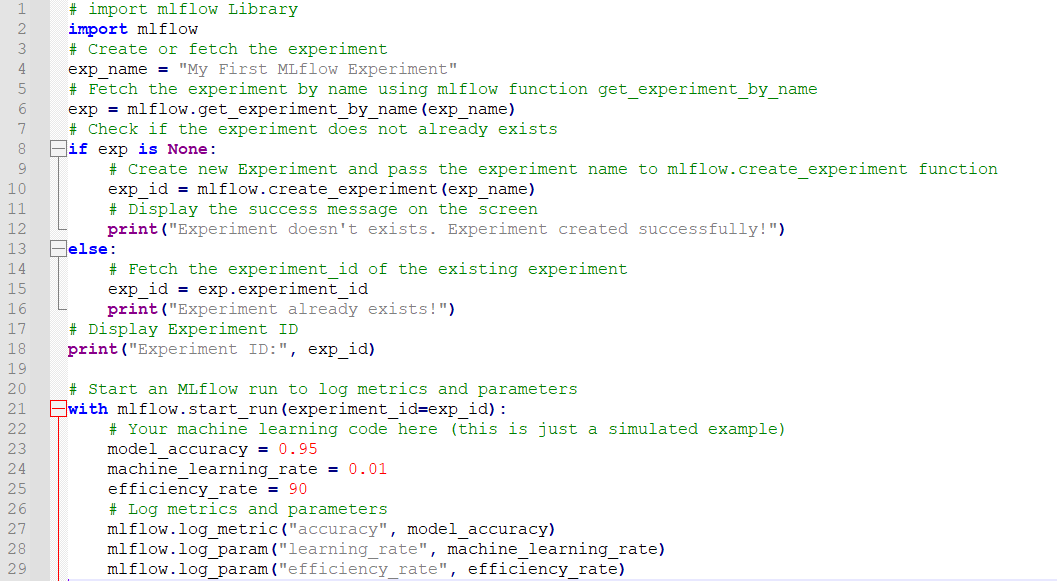
The MLflow library is imported in the first line of the code, and the experiment_name is set to “My First MLflow Experiment” in the next line. When the experiment_name is passed to the “mlflow.get_experiment_by_name” function, that function returns “None” if the experiment doesn’t exist and an object of the experiment otherwise.
Check for the existence of the experiment in the conditional statement. If the experiment already exists, set the experiment_id. Otherwise, use the “mlflow.create_experiment” to create a new experiment. The experiment ID is returned by this function. Display the experiment ID on the console or terminal screen at the end of the experiment. Copy the following code in the notepad and save the file with the desired name and with “.py” extension:
import mlflow
# Create or fetch the experiment
exp_name = "My First MLflow Experiment"
# Fetch the experiment by name using mlflow function get_experiment_by_name
exp = mlflow.get_experiment_by_name(exp_name)
# Check if the experiment does not already exists
if exp is None:
# Create new Experiment and pass the experiment name to mlflow.create_experiment function
exp_id = mlflow.create_experiment(exp_name)
# Display the success message on the screen
print("Experiment doesn't exists. Experiment created successfully!")
else:
# Fetch the experiment_id of the existing experiment
exp_id = exp.experiment_id
print("Experiment already exists!")
# Display Experiment ID
print("Experiment ID:", exp_id)
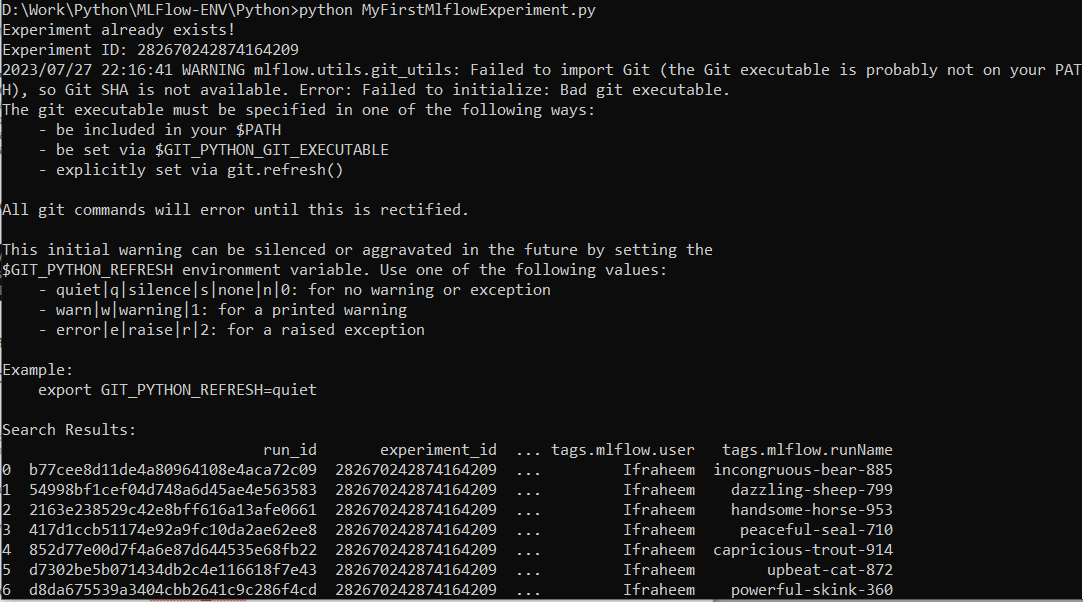
Now, launch the program in the command prompt or terminal window using the Python compiler and type “Python” and then the filename which, in this case, is “MyFirstMlflowExperiment.py”. When the experiment is first run, it does not yet exist. Thus, MLFlow creates one and prints the experiment ID on the console screen:

Re-run the code to verify that it isn’t creating new experiments and to display the ID of the ones that already exist. The following screenshot shows that the experiment already exists:

Step 2: Log the Runs with Metrics and Parameters
Let’s now attempt to log some runs with the metrics and parameters for the just-established experiment. In a real-world scenario, we develop the machine learning models and record the relevant information, such as metrics and parameters, at the end of each run. Here, accuracy is used as a matric value, and it is 0.95 in this case. The parameter values for learning and efficiency rate are 0.01 and 90, respectively. Here is the code:
with mlflow.start_run(experiment_id=exp_id):
# Your machine learning code here (this is just a simulated example)
model_accuracy = 0.95
machine_learning_rate = 0.01
efficiency_rate = 90
# Log metrics and parameters
mlflow.log_metric("accuracy", model_accuracy)
mlflow.log_param("learning_rate", machine_learning_rate)
mlflow.log_param("efficiency_rate", efficiency_rate)
The result, when the aforementioned code is executed, is seen here. The result is the same as before:

Step 3: Perform a Search Using Mlflow.search_runs()
Finally, we run a search on the runs that have been logged using a few parameters and show the results on the terminal screen:
define_search_criteria = "metrics.accuracy > 0.8 AND params.learning_rate = '0.01' AND params.efficiency_rate = '90'"
# Perform the search
runs = mlflow.search_runs(experiment_ids=exp_id, filter_string=define_search_criteria)
# Display the results
print("Search Results:")
print(runs)
A warning that pertains to the Git tool is produced by the search_runs function’s execution:
Add some code at the top of the Python file to disable this warning. Here is the short section of the code:
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"

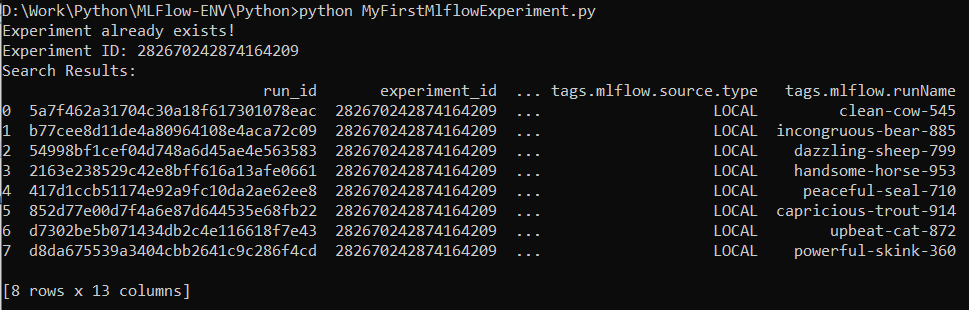
The “mlflow.search_runs” function is successfully executed once these lines of code are added:
Conclusion
The “mlflow.search_runs” function enables the users to quickly explore and evaluate the machine learning experiments, analyze many runs, and pinpoint the optimal hyperparameter variations or models that result in the desired outcomes. It is an effective tool for overseeing, planning, and analyzing the machine learning workflow.