Every day, people handle huge data which we called big data. In that big data, it sometimes contains column names or sometimes without the column names. The column names are there, but they contain irrelevant name or some unwanted characters like spaces, etc. So, we first need to pre-process those huge data before starting the analysis. So first of all, we require the rename of the column names.
DataFrame is row-oriented tabular data that has rows and columns. We can also say that DataFrame is a collection of different columns and each column is of different types like string, numeric, etc.
A pandas DataFrame can be created using the following constructor
Method 1: Using rename( ) function:
Syntax:
We created a Dataframe (df), which we will use to show different rename( ) methods.
In the above Dataframe, we can see that we have four columns [‘Name’, ‘Age’, ‘favorite_color’, ‘grade’].
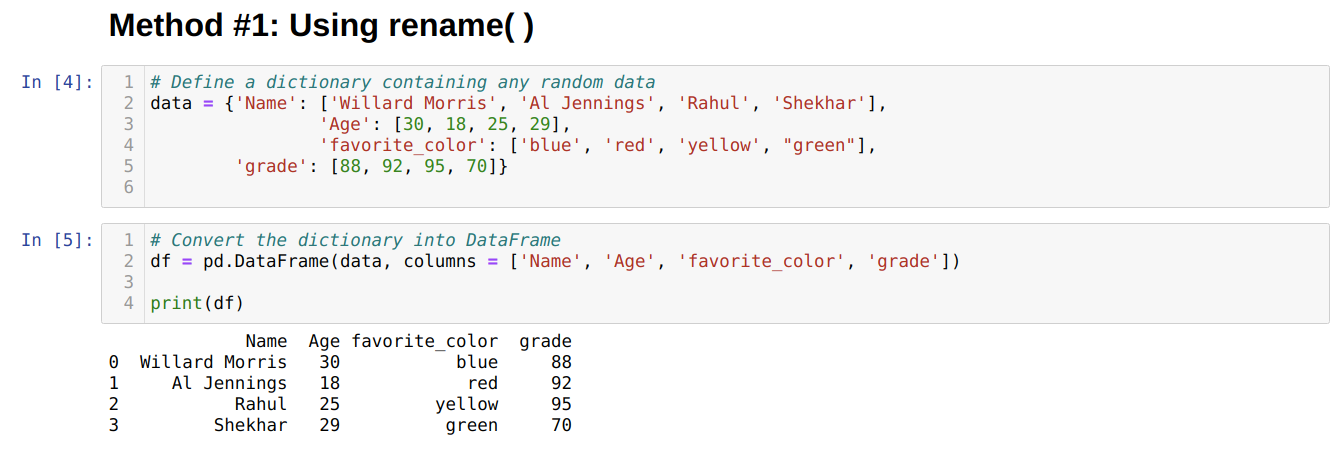
The Pandas have one in-built function called rename( ) which can change the column name instant. To use this, we have to pass a key (the original name of the column) and value (the new name of the column) form to the rename function under the column attribute. We can also use another option inplace to True which do changes directly to the existing Dataframe by default inplace is False.

From the above result, we can see that the names of the columns changed.
Method 2: Using List Method
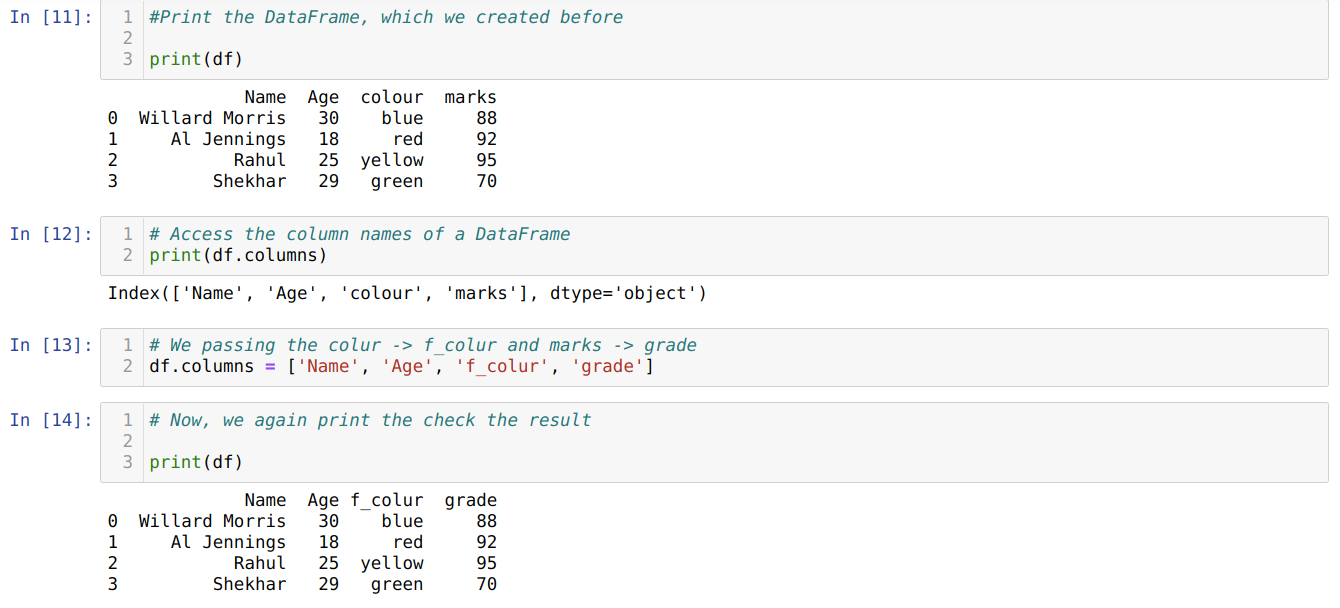
Pandas DataFrame has also given an attribute name column which helps us to access all column names of a Dataframe. So, by using this columns attribute, we can also rename the column name. We have to pass a new list of columns and assign to the columns attribute as shown below:
The main drawback to using the list method to rename a column’s name is that we have to pass all the column names even if we want to change only a few column names.
Method 3: Rename the Column Name Using the read_csv File
We can also rename the columns during the read_csv itself. For that, we have to create a list of columns and pass that list as a parameter to the names attribute while reading the csv.
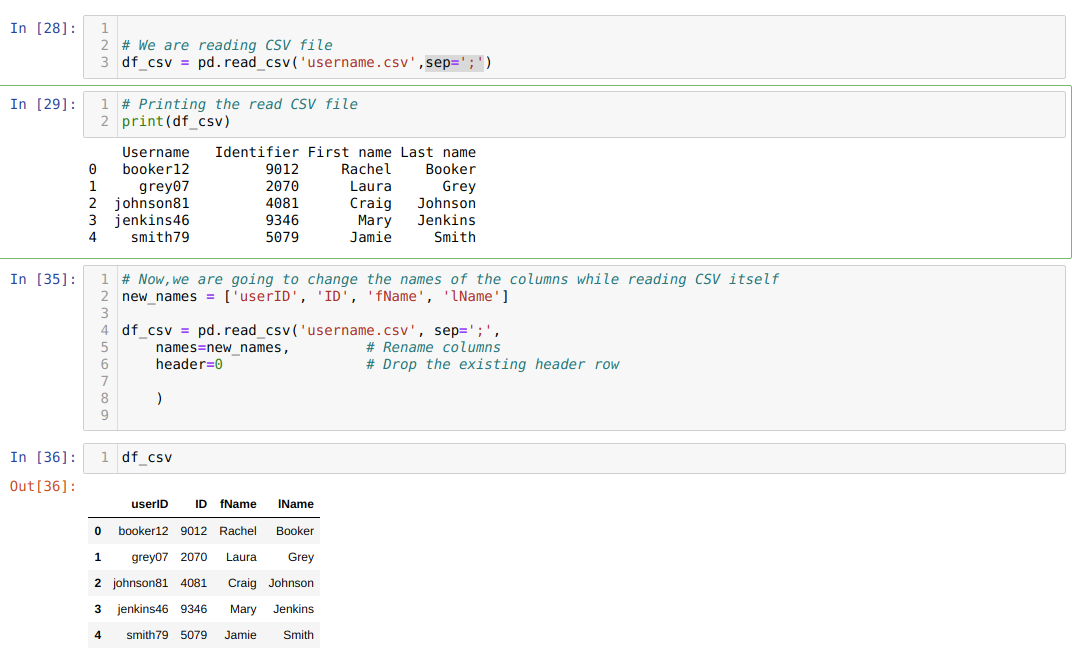
We use the one attribute header=0, which means that we override the previous columns of the .csv file with the new columns which we pass through the names attribute.
In the above .csv method, we rename the columns while using the list, and we pass all new columns inside of that list. But sometimes, we need to rename only a few columns. Then, we have to use the usecols attribute and mention the index values of those columns inside of that as shown below:
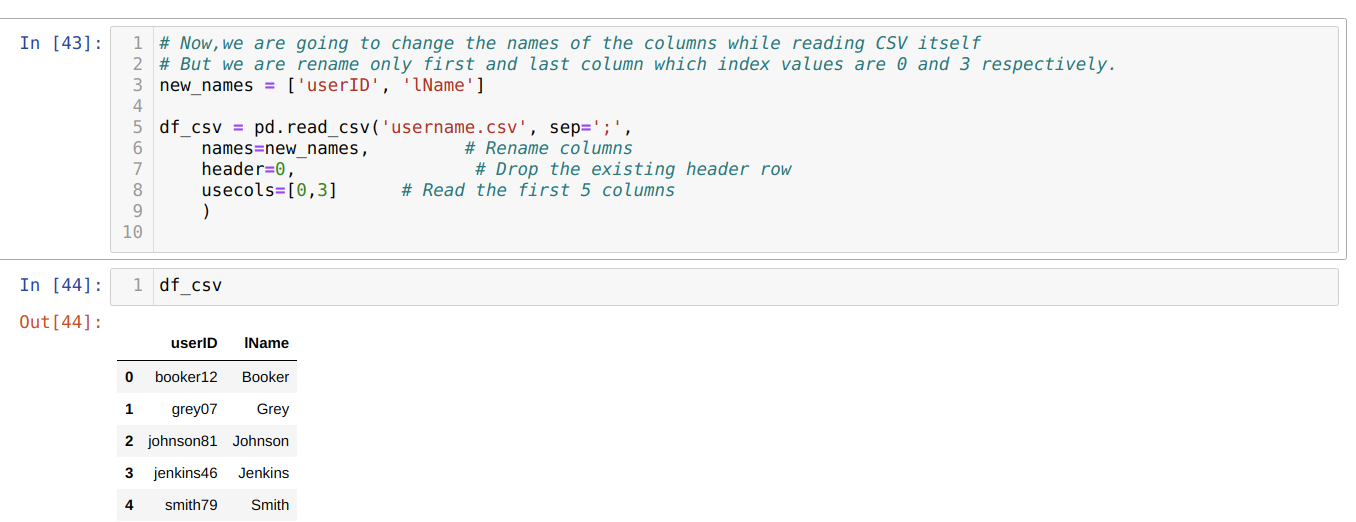
In the above, we rename only the first and last column of the csv file and for that we pass the index values of the columns (0 and 3) to the usecols attribute.
Method 4: Using the columns.str.replace()
This method is basically used when we want to change some phrases to some other phrases and not want to change the full column rename like space to underscore, etc.
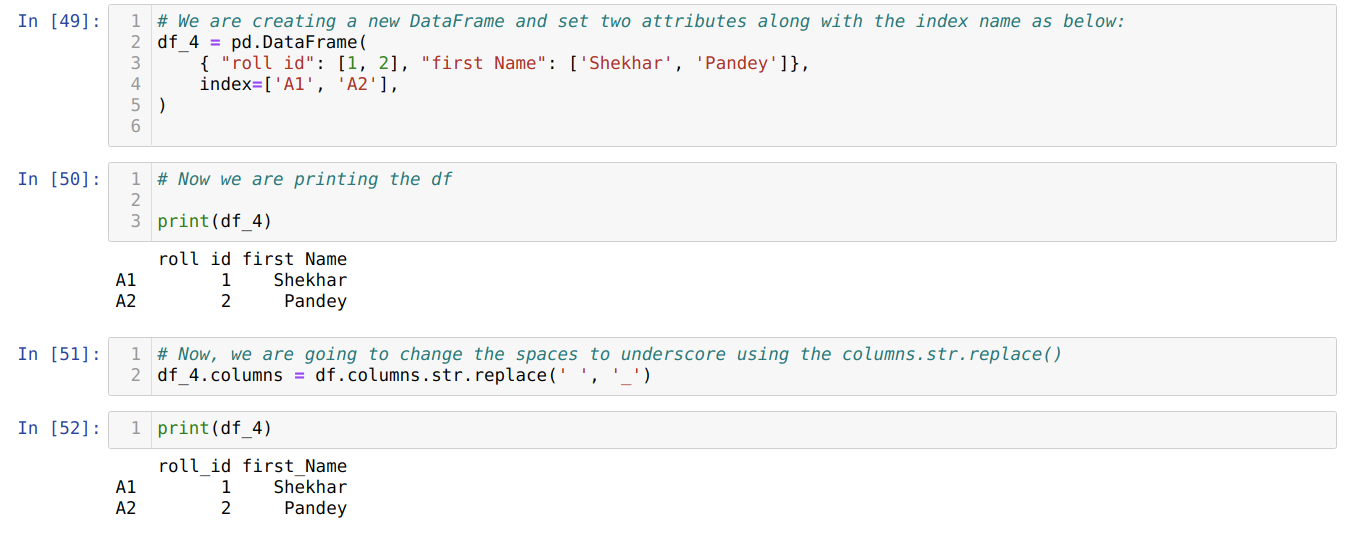
From the above result, we can see that now spaces override with the underscore.
The above method also has the facility of the index (df.index.str.replace()).
Method 5: Renaming Columns Using set_axis( )
This method is used to rename the index along with the column as shown below:
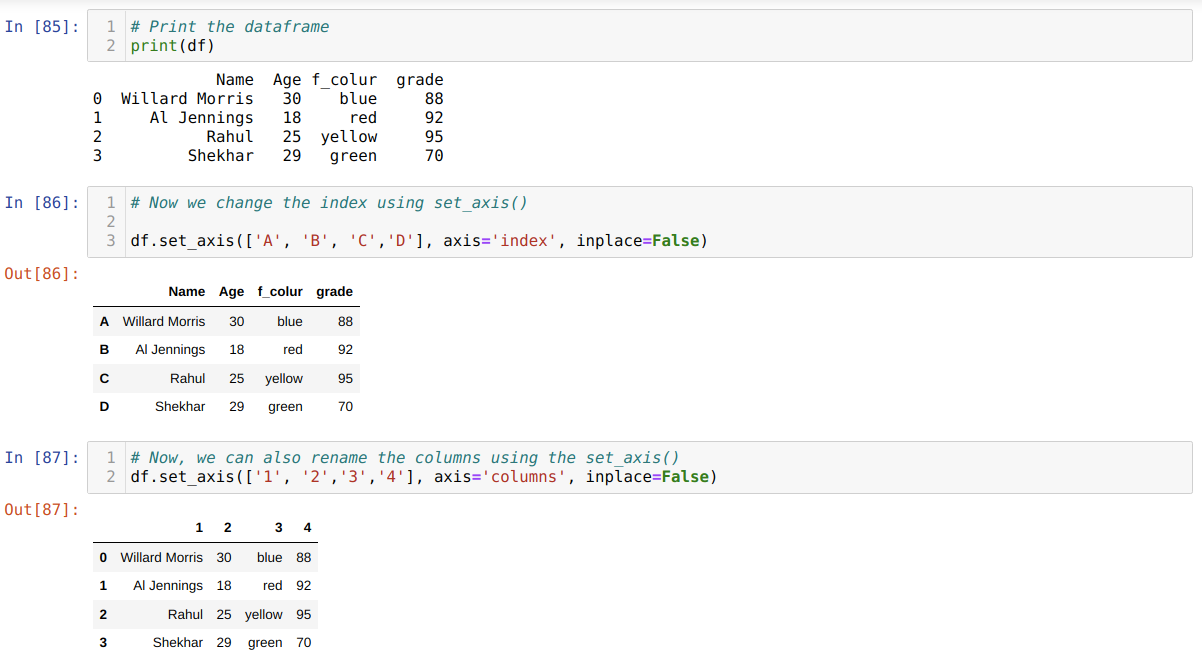
Conclusion
In this article, we show different methods on how to rename the columns. The best method which I consider is the rename() method where we have to pass only those columns which we want to rename in the dictionary (key, value) format. The columns attribute is the easiest method, but the main drawback of that is we have to pass all the columns even if we want to rename only a few columns. We can also rename columns while reading the CSV file itself, which is also a good option. The columns.str.replace() is the best option only when we want to replace some characters with other characters.