In this post, we will learn how to query the data from a given Pinecone index using the Python client for Pinecone DB.
Requirements:
To follow along with this tutorial, ensure that you have the following:
- Installed Python 3.10 and above
- Basic Python programming knowledge
Installing the Pinecone Client
Before interacting with the Pinecone server using Python, we need to install the Pinecone client on our machine. Luckily, we can do this with a simple “pip” command as follows:
The previous command should download the latest stable version of the Pinecone client and install it in your project.
Creating an Index and Upsert
Once we install the Pinecone client, we can create an index to store the vector data.
We can do this using the create_index() method as shown in the following example code:
import pinecone
pinecone.init(api_key="0f57b6af-ea59-4fd3-a0ce-3c7f0c1d419f", environment="us-west1-gcp-free")
pinecone.create_index("sample-index", dimension=8)
# Create two sets of 8-dimensional vectors
vectors_a = np.random.rand(15, 8).tolist()
vectors_b = np.random.rand(20, 8).tolist()
index = pinecone.Index("sample-index")
# Create ids
ids_a = map(str, np.arange(15).tolist())
ids_b = map(str, np.arange(20).tolist())
# Insert into separate namespaces
index.upsert(vectors=zip(ids_a,vectors_a),namespace='namespace_a')
index.upsert(vectors=zip(ids_b,vectors_b),namespace='namespace_b')
The previous code starts by initializing Pinecone. It then creates a basic index named “sample-index” with specified parameters and establishes a connection to the index.
Next, we generate two sets of 8-dimensional vectors and the corresponding IDs.
Next, we create the IDs for the vector pairs which we use to identify the vectors.
Finally, it inserts the vectors into the “namespace_a” and “namespace_b.”
The previous code should add the vectors into their corresponding namespaces as specified in the upsert() function.
Pinecone Query by Namespace
Once the data is stored in the index, we can use the query() method to search a namespace using a query vector. The method retrieves the IDs of the most similar items in a namespace and their similarity scores.
The function syntax is as follows:
The function accepts the following parameters:
- Namespace – It sets the namespace to query.
- Top_k – It sets the number of results to return for each query.
- Filter – It defines the filter to apply to the vectors. Check our tutorial on vector metadata to learn more.
- include_values – It denotes whether the vector values are included in the response.
- Include_metadata – It denotes whether the metadata is included in the response and the IDs.
- Vector – It specifies the query vector.
- Sparse_vector – It specifies the sparse query vector.
- Id – It specifies the unique ID of the vector to be used as a query vector.
Pinecone Index.query() Usage
The following shows how to use the query() function to return the top 10 matching vectors from namespace_b:
namespace='namespace_b',
top_k=10,
include_values=True,
include_metadata=True,
vector=[0.02, 0.99, 0.80, 0.54, 0.20, 0.12, 0.84, 0.56]
)
print(query_response)
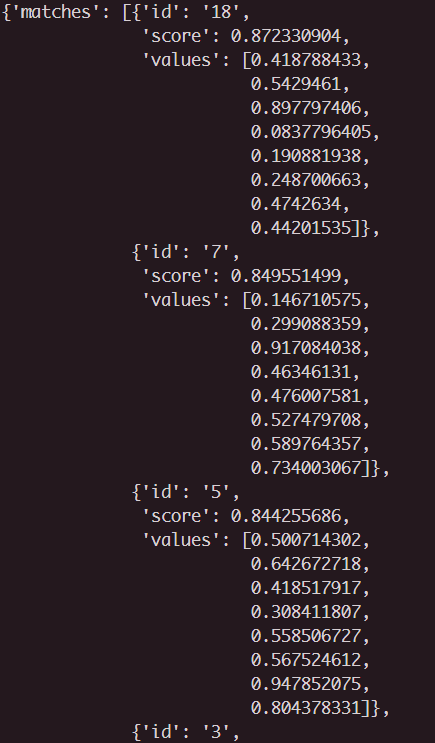
As you can guess, this query should return the top 10 matching vectors from the specified namespace.
An example output is as follows:
Conclusion
You learned how to utilize the query() method that is provided by the Pinecone client for Python to find the similarly matching vectors in a given namespace.