In mathematics, the average is determined by adding all the values/numbers and dividing them by the sum of the total numbers. While in the weighted average, the average of a data set is calculated while providing more weight or significance to some values than others. To determine the weighted average of DataFrame columns, various methods are used in Python.
This write-up provides a comprehensive tutorial on determining the weighted average of Pandas DataFrame using numerous examples.
How to Determine the Weighted Average of Pandas DataFrame in Python?
To determine the weighted average of Pandas DataFrame, the below methods are utilized in Python:
Method 1: Determine the Weighted Average Using “np.average()”
The “np.average()” method is used to determine the weighted average along the particular axis in Python.
Syntax
Here, in this syntax, the “a” parameter indicates the array that data needs to be averaged. The “axis” and “weights” parameter is used to specify the array axis along which to average the array and weights associated with the values along the array.
Let’s understand this method via the following example code:
df = pandas.DataFrame({'Id_no': [3, 2, 4, 6, 2],'Marks': [15, 35, 45, 55, 20]})
print(df, '\n')
print(numpy.average(a=df['Marks'], weights=df['Id_no']))
In the above code:
-
- The “pandas” and “numpy” modules are imported.
- The “pandas.DataFrame()” function creates the DataFrame and assigns the value to “df”.
- The “numpy.average()” method takes the dataframe column “Marks” as a first argument and “Id_no” as a second argument to determine the weighted average based on the specified weights.
Output
The weighted average has been calculated successfully:
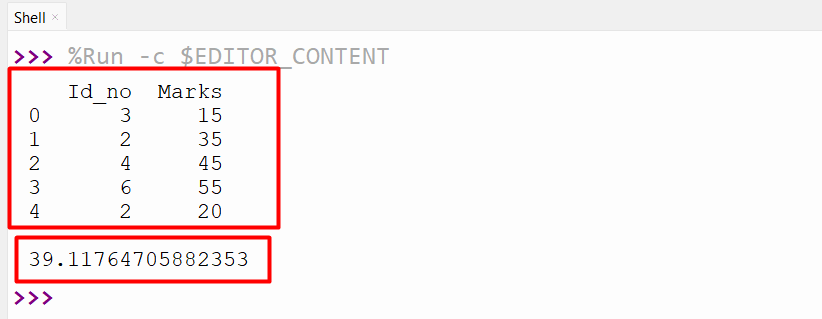
The below snippet shows how the weighted average has been calculated:

Method 2: Determine the Weighted Average Using the “User Defined” Function
This example is used to determine the weighted average by defining the custom function:
df = pandas.DataFrame({'Id_no': [3, 2, 4, 6, 2],'Marks': [15, 35, 45, 55, 20]})
print(df, '\n')
def w_average(df, x, w):
return sum(df[w] * df[x]) / df[w].sum()
print(w_average(df, 'Marks', 'Id_no'))
In the above code:
-
- The user-defined function named “w_average” is defined with three parameters.
- The function retrieves the weighted average of the specified DataFrame columns. Here the weight values are multiplied by the actual data values and divided by the sum of the weights.
- The “w_average()” function is called on the specified columns and determines the weighted average.
Output
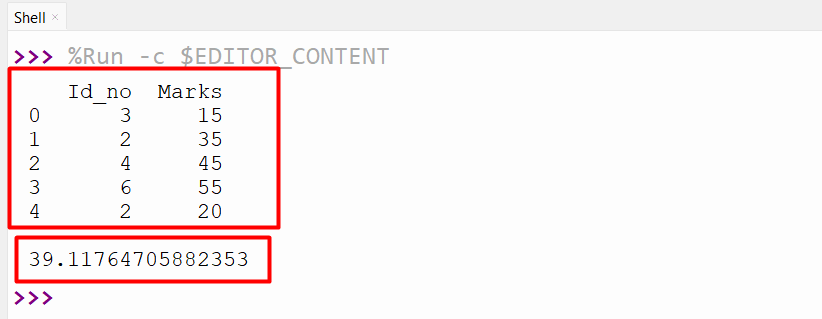
The weighted average of the Pandas DataFrame column has been determined.
Method 3: Determine the Weighted Average Using the “groupby”
We can also group the DataFrame data and determine each group’s weighted average. Here is an example code:
df = pandas.DataFrame({'Name': ['Joseph', 'Lily', 'Joseph','Lily','Joseph'],'Id_no': [3, 2, 4, 6, 2],'Marks': [15, 35, 45, 55, 20]})
print(df, '\n')
def w_average(df, x, w):
return sum(df[w] * df[x]) / df[w].sum()
print(df.groupby('Name').apply(w_average, 'Marks', 'Id_no'))
In this code:
-
- The “w_average()” custom function is defined with three parameters: “array data”, “values”, and “weights”.
- The “df.groupby()” method groups the DataFrame data based on the specified columns.
- After grouping data, the “apply()” function executes the custom-defined function to the particular columns of DataFrame to retrieve the weighted average.
Output
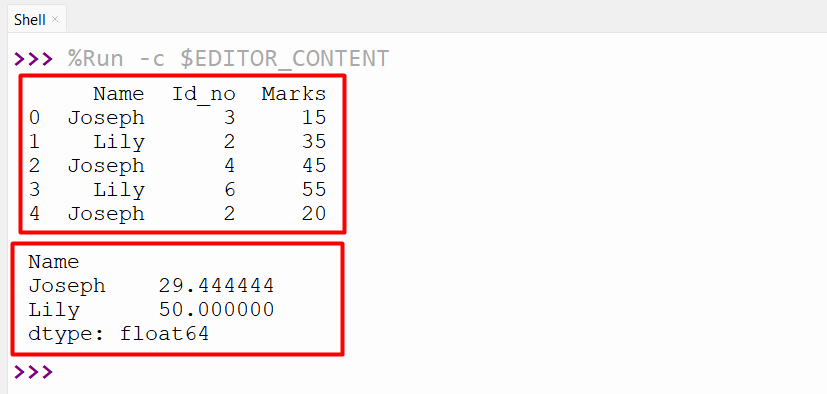
The weighted average of the specified DataFrame columns based on the group has been calculated.
Conclusion
The “np.average()” method, the “User Defined” function, and the “groupby” method are used to determine the weighted average of the Pandas DataFrame. These methods can determine the weighted average of the specified DataFrame columns. This write-up delivered a comprehensive tutorial on the Pandas weighted average using numerous examples.