In Python, the “Pandas Vlookup” is the process of merging two different data tables according to the common attribute or column. This process is similar to the Vlookup function in Microsoft Excel. The retrieved table in Pandas Vlookup contains all the data from both input tables for which the data is matched/combined. The “pandas.merge()” and “pandas.map()” methods are utilized to perform Vlookup in Python.
This tutorial will deliver a detailed guide on how to perform the Vlookup function in Python via the below contents:
- How to Perform Vlookup in Pandas Python?
- Performing a Vlookup With “Inner” Join
- Performing a Vlookup With “left” Join
- Performing a Vlookup With “right” Join
- Performing a Vlookup With “outer” Join
- Performing a Vlookup Using “pandas.map()” Method
How to Perform Vlookup in Pandas Python?
In Python, the “pandas.merge()” method is used to perform Vlookup using various joins such as inner, outer, left, etc. The “pandas.merge()” method is similar to the JOIN operation in SQL.
Syntax
For a detailed understanding of the syntax and method check out the dedicated guide the “pandas.merge()” method.
Example 1: Performing a Vlookup With “Inner” Join Using “pandas.merge()” Method
In the below-provided code, first, we imported/initialized the “pandas” library. After that, we created two DataFrames using the “pandas.DataFrame()” method. Next, we perform the “Vlookup” by merging the two tables based on the inner join or common attribute (column):
df1 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jordan'], 'Age':[22, 15, 23, 32]})
df2 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jason'], 'Height' : [4.2, 5.3, 6.3, 4.8]})
print(df1, '\n')
print(df2, '\n')
print(pandas.merge(df1, df2, on ='Name', how ='inner'))
As you can see, the retrieved DataFrame contains only the rows where the values are common in columns between two DataFrame:

Example 2: Performing a Vlookup With “left” Join Using “pandas.merge()” Method
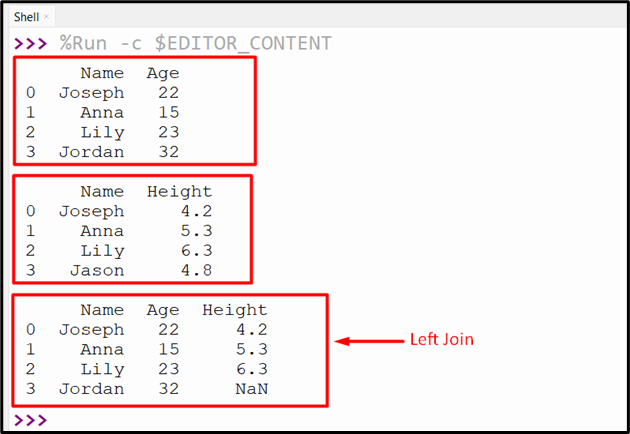
In this example, we perform a Vlookup by using the “left” join of the “pandas.merge()” method. In the left join operation, all the matching rows from the two given DataFrame are kept in return DataFrame. While the non-matching rows in the 2nd DataFrame will be replaced by Nan values:
df1 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jordan'], 'Age':[22, 15, 23, 32]})
df2 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jason'], 'Height' : [4.2, 5.3, 6.3, 4.8]})
print(df1, '\n')
print(df2, '\n')
print(pandas.merge(df1, df2, on ='Name', how ='left'))
The execution of the above code retrieved below DataFrame:
Example 3: Performing a Vlookup With “right” Join Using “pandas.merge()” Method
Here, we perform a Vlookup by using the “right” join of the “pandas.merge()” method. This joining operation is like the left join but only the non-matching rows from 1st DataFrame are reapplied with Nan. All the rows of 2nd DataFrame will be kept whether similar or not:
df1 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jordan'], 'Age':[22, 15, 23, 32]})
df2 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jason'], 'Height' : [4.2, 5.3, 6.3, 4.8]})
print(df1, '\n')
print(df2, '\n')
print(pandas.merge(df1, df2, on ='Name', how ='right'))
The following DataFrame has been retrieved to the console:

Example 4: Performing a Vlookup With “outer” Join Using “pandas.merge()” Method
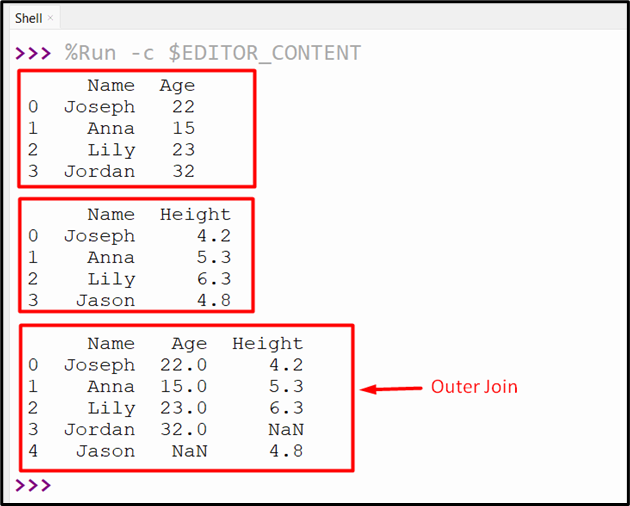
In the “outer” join operation all the DataFrame rows from the given two DataFrames are shown. The non-matching rows will be replaced by Nan values:
df1 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jordan'], 'Age':[22, 15, 23, 32]})
df2 = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jason'], 'Height' : [4.2, 5.3, 6.3, 4.8]})
print(df1, '\n')
print(df2, '\n')
print(pandas.merge(df1, df2, on ='Name', how ='outer'))
The execution of the above provided code retrieves the below output:
Performing a Vlookup Using “pandas.map()” Method
In Python, the “pandas.map()” method can be used to perform a Vlookup-like operation. This method is used to map values from one Pandas DataFrame/Series column or dictionary to another based on common attributes. Here is a code block that will display/show you how we can achieve this:
df = pandas.DataFrame({'Name':['Joseph', 'Anna', 'Lily', 'Jordan'],
'Age':[22, 15, 23, 32],
'Height': [4.2, 5.3, 6.3, 4.8],
'Gender': ['M', 'F', 'F', 'M']})
print(df, '\n')
map1 = {'M': 'Team-1','F': 'Team-2'}
df['Team'] = df['Gender'].map(map1)
print(df)
In this code, the “pandas.map()” method maps the dictionary value to the DataFrame based on the common attributes. The retrieved DataFrame will look like this:

Conclusion
In Python, the “pandas.merge()” method of the “pandas” library is used to perform the “Vlookup” function on the given Pandas object. The different merge operations, such as inner, outer, left, and right are utilized to perform Vlookup functions with different joining techniques. This write-up delivered a Pandas Vlookup guide.