“Variance” is an estimation of how broadly the values in a data set are different from the mean. The greater the variance, the more dispersed the data is. While working with Pandas DataFrame in Python, we need to calculate the variance of the DataFrame columns. The “DataFrame.var()” method is used to determine the variance of DataFrame columns in Python.
This tutorial delivered a thorough guide on Pandas variance utilizing several examples and via the below content:
- How to Determine the Pandas Variance in Python?
- Determining the Variance of Single DataFrame Column
- Determining the Variance of Multiple DataFrame Columns
- Determining the Variance of the Entire DataFrame Column
- Determining the Variance of DataFrame Column with Missing Data
- Determining the Variance Using “groupby()” and “agg()” Method
How to Determine the Pandas Variance in Python?
In Python, the “DataFrame.var()” method is used to determine the variance of each column or row in a Pandas DataFrame object.
Syntax
Parameters
In the above syntax:
- The “axis” parameter specifies which axis (index or columns) to check or determine (by default 0).
- The “skipna” parameter is the boolean value that is utilized to exclude/eliminate NA/null values.
- The “ddof” parameter specifies the delta degrees of freedom (by default 1).
- The “numeric_only” parameter indicates whether to only check numeric values or not (by default None).
Return Value
The retrieved value of the “var()” is Series or DataFrame according to the particular level.
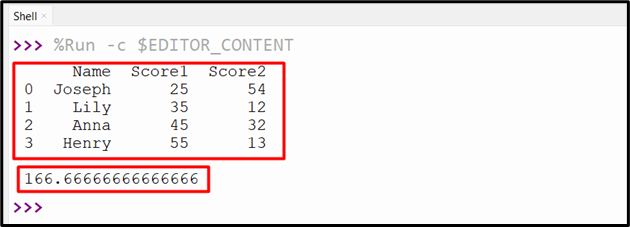
Example 1: Determining the Variance of Single DataFrame Column
In the below code, we first create a DataFrame using the “DataFrame()” method. Next, the “df.var()” method is used to determine the variance of a single DataFrame column:
data = pandas.DataFrame({'Name': ['Joseph', 'Lily', 'Anna', 'Henry'],
'Score1': [25, 35, 45, 55],'Score2': [54, 12, 32, 13]})
print(data, '\n')
print(data['Score1'].var())
The variance of the specified DataFrame column has been determined:
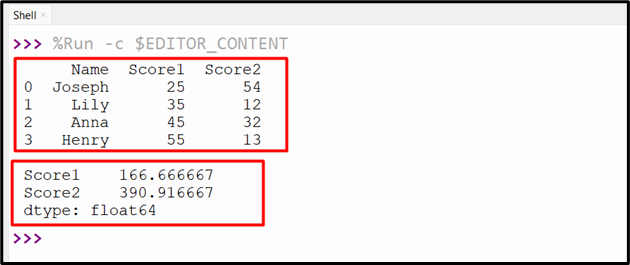
Example 2: Determining the Variance of Multiple DataFrame Columns
We can also determine the variance of multiple DataFrame columns using the “df.var()” method. In the below code, the “df.var()” finds the variance of the “Score1” and “Score2” columns:
data = pandas.DataFrame({'Name': ['Joseph', 'Lily', 'Anna', 'Henry'],
'Score1': [25, 35, 45, 55],'Score2': [54, 12, 32, 13]})
print(data, '\n')
print(data[['Score1', 'Score2']].var())
The variance value of the specified DataFrame columns have been determined:
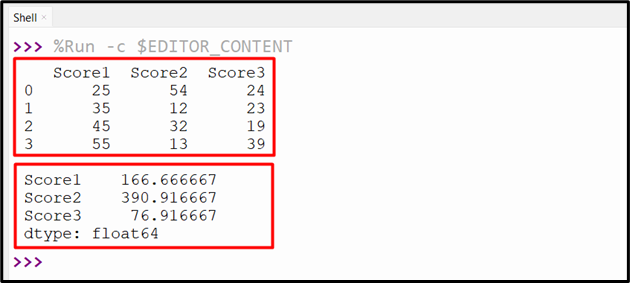
Example 3: Determining the Variance of Entire DataFrame Column
This example calculates the variance of the entire DataFrame column using the “df.var()” method:
data = pandas.DataFrame({'Score1': [25, 35, 45, 55],'Score2': [54, 12, 32, 13], 'Score3': [24, 23, 19, 39]})
print(data, '\n')
print(data.var())
The following snippet shows the Pandas variance of the entire DataFrame:
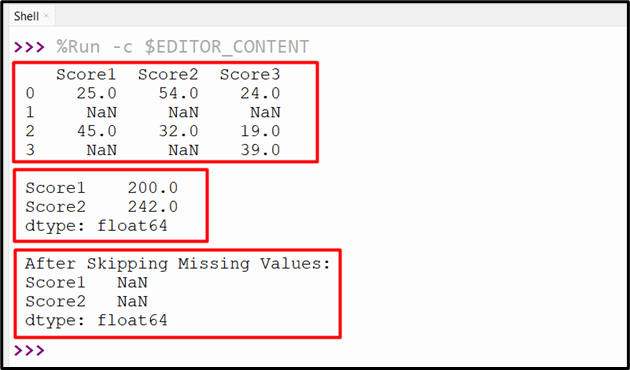
Example 4: Determining the Variance of DataFrame Column with Missing Data
From the syntax, we know that the “skipna=” parameter default value is “True”. This means that the missing value will be skipped while determining the variance of the DataFrame columns. But here in the below code, we determine the variance by including the missing data which will retrieve the NaN value:
data = pandas.DataFrame({'Score1': [25, None, 45, None],'Score2': [54, None, 32, None], 'Score3': [24, None, 19, 39]})
print(data, '\n')
print(data[['Score1', 'Score2']].var())
print('\nAfter Skipping Missing Values:')
print(data[['Score1', 'Score2']].var(skipna=False))
The below output verified that the missing data is included and retrieved NaN value:
Example 5: Determining the Variance Using “groupby()” and “agg()” Method
Here, the “groupby()” method is used along with the “agg()”‘ method to group the data and determine the variance of the grouped data. Take the following code that determines the variance of the grouped data of the “Name” column:
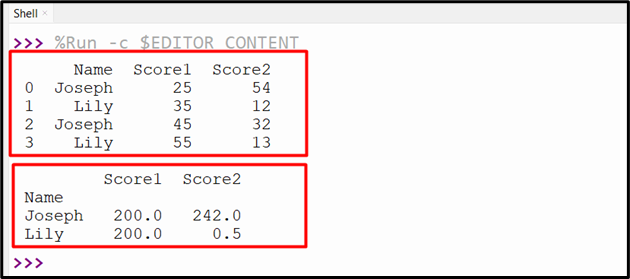
data = pandas.DataFrame({'Name': ['Joseph', 'Lily', 'Joseph', 'Lily'],
'Score1': [25, 35, 45, 55],'Score2': [54, 12, 32, 13]})
print(data, '\n')
print(data.groupby('Name').agg('var'))
The variance of the grouped data has been determined successfully:
Conclusion
The “DataFrame.var()” method is utilized in Python to determine the variance of single, multiple DataFrame objects of Pandas. We can also determine the variance of the DataFrame columns with and without missing values. The “groupby()” and “agg()” method is used to group the data as well as determine the variance of the DataFrame. This article illustrated Panda’s variance using numerous examples.