Topic of Contents
1. pandas.Series.value_counts
The pandas.Series.value_counts() function returns a Series that includes the count of unique values. The most frequently occurring element is placed first in descending order.
Syntax
Let’s see the syntax of pandas.Series.value_counts() function and parameters passed to it.
Parameters
- If the normalize parameter (Default = False) is set to True, the result holds the relative frequencies of the unique values.
- The sort parameter (Default = True) is used to sort the elements in descending order based on frequency (occurrence). If you don’t want to sort, set this parameter to False.
- You can sort the elements based on frequency in ascending order using the ascending parameter (Default = False) by setting it to True.
- You can create bins from the existing Series using the bins parameter. It accepts an integer value. The result contains the total values present in each bin.
- The dropna parameter (Default = True) is used to deal with missing values that exist in the given Series. By default, it won’t include the missing values. Missing values are considered, if you set this parameter to False.
Example 1: No Parameter
Let’s create a Series named student_scores that holds 10 integers. We will return a Series that counts all the unique values using the value_counts function. Here, no parameter is passed to this function.
# Create Series named student_scores
student_scores = pandas.Series([67,90,90,90,90,80,67,90,80,100])
print(student_scores,"\n")
# value_counts with no parameters
student_scores.value_counts()
Output
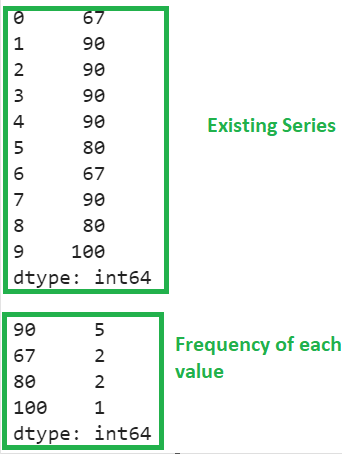
There are four unique values – 90, 67, 80 and 100 with frequencies 5, 2, 2, and 1.
Example 2: Bins Parameter
Let’s return the count of unique values for each bin by specifying the ‘bins’ parameter.
- Set bins to 3 and return the count of values present in each bin.
- Set bins to 2 and return the count of values present in each bin.
- Set bins to 5 and return the count of values present in each bin.
student_scores = pandas.Series([67,90,90,90,90,80,67,90,80,100])
# value_counts with bins parameter
print(student_scores.value_counts(bins=3),"\n")
print(student_scores.value_counts(bins=2),"\n")
print(student_scores.value_counts(bins=5))
Output
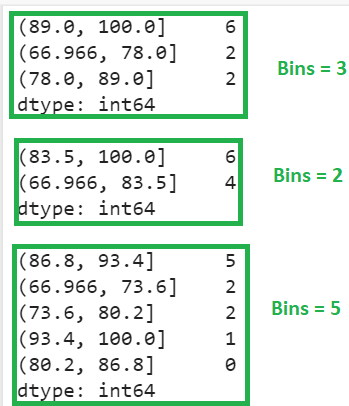
- The first bin holds six values, the second and third bin hold two values each.
- The first bin holds six values and the second bin holds two values.
- The first bin holds five values, the second and third bin hold two values each, fourth bin holds one value. Last bin is empty.
Example 3: Normalize Parameter
Using the same Series, return the relative frequencies of unique values. We will see the output when this parameter is set to True and False separately.
student_scores = pandas.Series([67,90,90,90,90,80,67,90,80,100])
# value_counts with norm parameter set to True
print(student_scores.value_counts(normalize=True),"\n")
# value_counts with norm parameter set to False
print(student_scores.value_counts(normalize=False))
Output
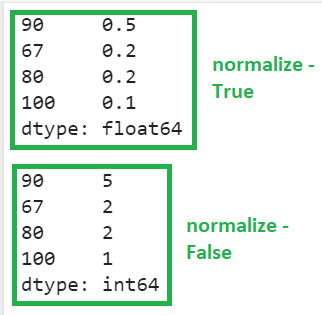
When ‘normalize’ is set to True, the total number of values present in the Series is 10.
- 90 occurs five times, so the relative frequency is 5/10, which equals 0.5.
- 67 occurs two times, so the relative frequency is 2/10, which equals 0.2.
- 80 occurs 2 times, so the relative frequency is 2/10, which equals 0.2.
- 100 occurs only 1 time, so the relative frequency is 1/10, which equals 0.1.
Example 4: Sort Parameter
Utilize the same Series and return the count of all unique values, both sorted and unsorted based on the frequencies, by specifying the sort parameter.
student_scores = pandas.Series([67,90,90,90,90,80,67,90,80,100])
# value_counts with sort parameter set to True
print(student_scores.value_counts(sort=True),"\n")
# value_counts with sort parameter set to False
print(student_scores.value_counts(sort=False))
Output
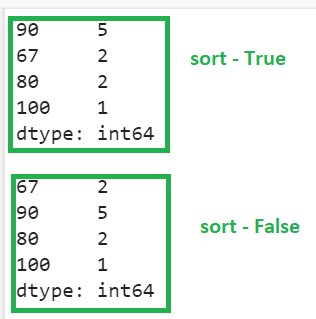
In the first output, Series is sorted based on the frequency count as the parameter is set to True and in the second output, the Series is not sorted.
Example 5: Ascending Parameter
Utilize the same Series, return the count of all unique values by setting the ‘ascending’ parameter to True and False.
student_scores = pandas.Series([67,90,90,90,90,80,67,90,80,100])
# value_counts with ascending parameter set to True
print(student_scores.value_counts(ascending=True),"\n")
# value_counts with ascending parameter set to False
print(student_scores.value_counts(ascending=False))
Output
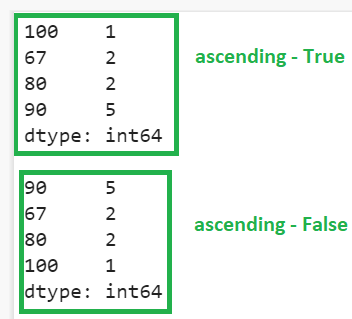
The result is returned in ascending order based on the frequency in the first output.
Example 6: dropna Parameter
Create a Series with some missing values (None) and obtain the count of all unique values by excluding and including the missing values.
student_scores = pandas.Series([None,None,90,90,90,90,80,None,None])
# value_counts with dropna parameter set to True
print(student_scores.value_counts(dropna=True),"\n")
# value_counts with dropna parameter set to False
print(student_scores.value_counts(dropna=False))
Output
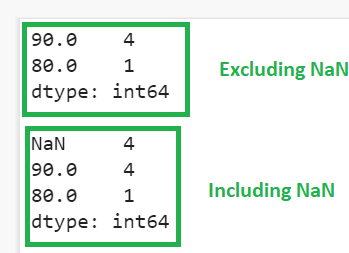
Missing values are excluded in the first output and included in the second output (4 missing exists in the second output).
2. pandas.Index.value_counts
The pandas.Index.value_counts() function will return a Series that includes the count of unique values. In this result, the most frequently occurring element will be placed first in descending order. It will work similarly to the pandas.Series.value_counts() function.
Syntax
Let’s see the syntax of the pandas.Index.value_counts() function and the parameters passed to it.
Parameters:
- If the normalize parameter (Default = False) is set to True, the result holds the relative frequencies of the unique values.
- The sort parameter (Default = True) is used to sort the elements in descending order based on frequency (occurrence). If you don’t want to sort, set this parameter to False.
- We can sort the elements based on the frequency in ascending order using the ascending parameter (Default = False) by setting it to True.
- It can be possible to create bins from the existing Index using the bins parameter. It will accept an integer value. The result contains total values present in each bin.
- The dropna parameter (Default = True) is used to deal with missing values that exist in the given Index. By default, it won’t include the missing values. Missing values are considered if you set this parameter to False.
Example
We will discuss only one example for Index data. You can utilize the examples explained under Series Data.
Let’s create an Index data named student_scores that hold 10 integers. Count all the unique values using the value_counts function. Here, no parameter is passed to this function.
student_index = pandas.Index([None,None,1,None,3,5,6,5,2,3])
print(student_index.value_counts())
Output

3. pandas.DataFrame.value_counts
The pandas.DataFrame.value_counts() function will return a Series containing counts of unique rows in the pandas DataFrame.
Syntax
Let’s see the syntax of pandas.DataFrame.value_counts() function and parameters passed to it.
Parameters
All the parameters that we discussed under the Series are the same in the DataFrame also. But in the Series, there is no subset parameter. Here, we have this parameter, and the bins parameter is not supported in the DataFrame. The subset parameter will take the column or list of columns that are used when counting the unique combinations. By default, it is None.
Example 1: No Parameters
Let’s create a DataFrame named mechanic_cases with three columns and ten rows. Let’s return the count of all unique records present in this DataFrame using the value_counts() function without passing the parameters.
# Create DataFrame with 3 columns that holds 10 records
mechanic_cases = pandas.DataFrame({'Case_Id': [None,2,3,4,4,2,4,2,None,1],
'Source': [None,'Email',None,'Email','Web','Phone','Web','Email',None,'Phone'],
'Priority':['Low','Medium','Medium','High','Medium','Medium','Medium','Medium','Low','High']})
print(mechanic_cases,"\n")
# value_counts with no parameters
mechanic_cases.value_counts()
Output
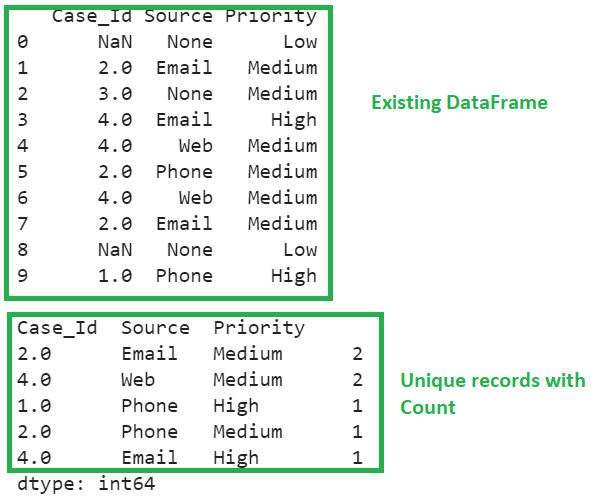
Among the ten records, there are five unique records. Three records with missing values are not considered.
Example 2: Subset Parameter
- Get the frequency of values present in the ‘Source’ column
- Get the frequency of values present in ‘Source,’ ‘Priority’ columns.
print(mechanic_cases.value_counts(subset=['Source']),"\n")
print(mechanic_cases.value_counts(subset=['Source','Priority']),"\n")
Output

Example 3: Normalize Parameter
- value_counts with the normalize parameter set to False.
- value_counts with the normalize parameter set to True.
print(mechanic_cases.value_counts(normalize=False),"\n")
# value_counts with normalize parameter set to True
print(mechanic_cases.value_counts(normalize=True))
Output
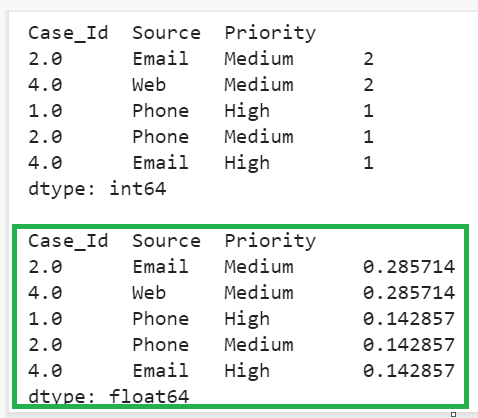
- Row-1: Frequency is 2, so 2/7 => 0.285714
- Row-2: Frequency is 2, so 2/7 => 0.285714
- Row-3: Frequency is 1, so 1/7 => 0.142857
- Row-4: Frequency is 1, so 1/7 => 0.142857
- Row-5: Frequency is 1, so 1/7 => 0.142857
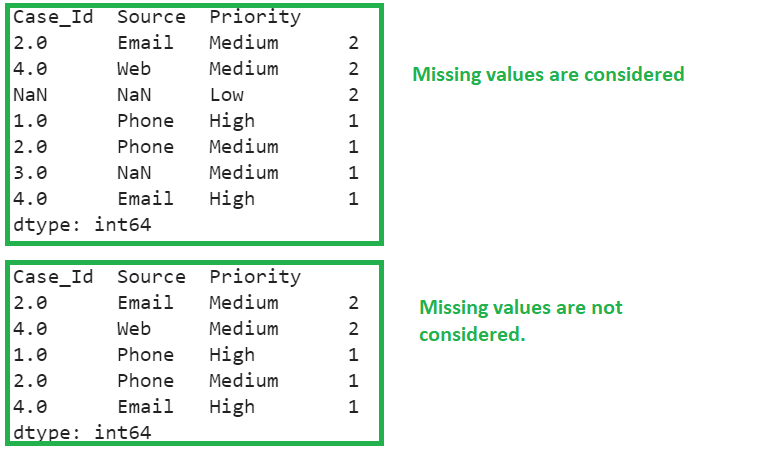
Example 4: dropna Parameter
- value_counts with the dropna parameter set to False.
- value_counts with the dropna parameter set to True.
print(mechanic_cases.value_counts(dropna=False),"\n")
# value_counts with dropna parameter set to True
print(mechanic_cases.value_counts(dropna=True))
Output
Conclusion
We saw how to apply the value_counts() function to the pandas Series, Index and DataFrame. For each Data Structure, all the parameters are explained along with the syntax. pandas.Index.value_counts() will work similarly to the pandas.Series.value_counts() function. In pandas.DataFrame.value_counts(, the subset parameter will take the column or list of columns that are used when counting the unique combinations.