In mathematics, the “Standard Deviation” is a statistical calculation that quantifies the amount of variation or dispersion in a dataset. In Python, we can compute the standard deviation using various modules, such as statistics, NumPy, or Pandas. To calculate/determine the standard deviation for the DataFrame column values, the “DataFrame.std()” method is used in Python.
This write-up will cover:
- What is the “DataFrame.std()” Method in Python?
- Single DataFrame Column
- Multiple DataFrame Column
- Entire DataFrame Column
- Skipping NaN Values
- Utilizing the “ddof” Parameter
What is the “DataFrame.std()” Method in Python?
The “DataFrame.std()” method of the “pandas” module is utilized to retrieve the standard deviation of the given DataFame over the requested axis. The syntax of the “DataFrame.std()” method is shown below:
In the above syntax:
- The “axis” parameter specifies the axis that needs to be checked, such as “0” for the index and “1” for columns.
- The “skipna” parameter default value is set/assigned to “True”. The parameter value excludes the NaN or Null values while determining the standard deviation.
- The “ddof” parameter indicates the delta degree of freedom.
- The “numeric_only” parameter is used to include only the int, float, or Boolean columns.
Return Type
This “DataFrame.std()” method retrieves the DataFrame or Series based on the particular level.
Example 1: Determining the Standard Deviation of the Single DataFrame Column
The following example is used to determine the standard deviation of the single DataFrame column. The “df.std()” computes the standard deviation of the single column “score_1”. Here is a code:
import numpy
df = pandas.DataFrame({'score_1': [22, 29, 10, 38, 10, 23],'score_2': [12, 19, 15, 18, 19, numpy.nan],'score_3': [19, 17, 13, 18, numpy.nan, 10]})
print(df, '\n')
print(df['score_1'].std())
This code retrieves the following output to the console:

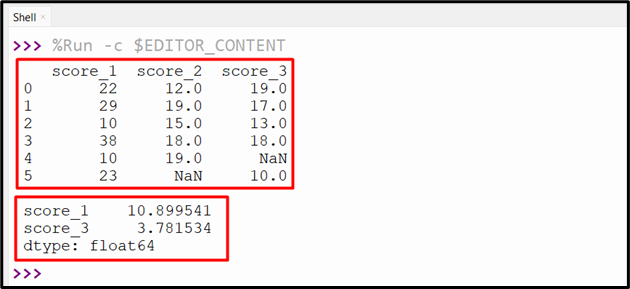
Example 2: Determining the Standard Deviation of the Multiple DataFrame Column
The below code is used to retrieve the standard deviation of the multiple columns of Pandas DataFrame. In this code, the “df.std()” method computes the standard deviation of the multiple columns “score_1” and “score_3”.
import numpy
df = pandas.DataFrame({'score_1': [22, 29, 10, 38, 10, 23],'score_2': [12, 19, 15, 18, 19, numpy.nan],'score_3': [19, 17, 13, 18, numpy.nan, 10]})
print(df, '\n')
print(df[['score_1', 'score_3']].std())
After executing the above-provided code, the following output will show on the console:
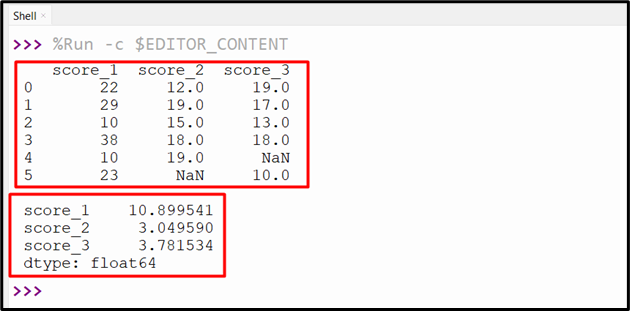
Example 3: Determining the Standard Deviation of the Entire DataFrame Column
To determine the standard deviation of the entire DataFrame columns, the “df.std()” method is used directly without specifying any column labels. Take the following code to determine the standard deviation:
import numpy
df = pandas.DataFrame({'score_1': [22, 29, 10, 38, 10, 23],'score_2': [12, 19, 15, 18, 19, numpy.nan],'score_3': [19, 17, 13, 18, numpy.nan, 10]})
print(df, '\n')
print(df.std())
The above-given code generates the following output:
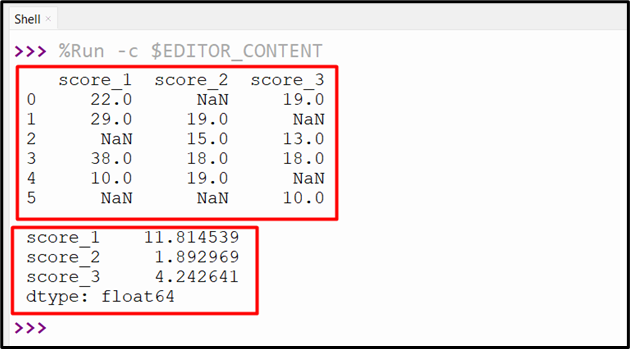
Example 4: Determining the Standard Deviation of the DataFrame by Skipping NaN Values
We can skip the “None” values of DataFrame columns using the “skipna=True” parameter. This parameter is passed to the “df.std()” method to determine the standard deviation by ignoring the NaN values. Here is an example code:
import numpy
df = pandas.DataFrame({'score_1': [22, 29, numpy.nan, 38, 10, numpy.nan],'score_2': [numpy.nan, 19, 15, 18, 19, numpy.nan],'score_3': [19, numpy.nan, 13, 18, numpy.nan, 10]})
print(df, '\n')
print(df.std(skipna=True))
Here is the output of the above-stated code after execution:
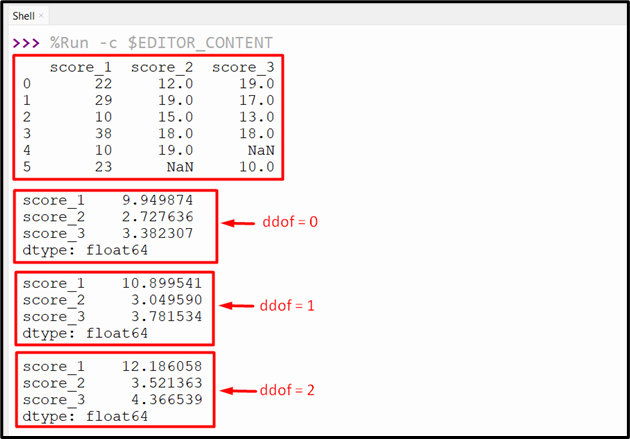
Example 5: Determining the Standard Deviation of the DataFrame Utilizing the “ddof” Parameter
The “ddof” parameter is used to specify the number of elements to be used while determining the standard deviation. To calculate the standard deviation using all the column values, the default value “0” is used, while the “1” value is used to calculate the standard deviation for all the values columns except the last value. Here is an example code:
import numpy
df = pandas.DataFrame({'score_1': [22, 29, 10, 38, 10, 23],'score_2': [12, 19, 15, 18, 19, numpy.nan],'score_3': [19, 17, 13, 18, numpy.nan, 10]})
print(df, '\n')
print(df.std(ddof=0), '\n')
print(df.std(ddof=1), '\n')
print(df.std(ddof=2), '\n')
The above code will show the following output after execution:
Conclusion
The “DataFrame.std()” method of the “pandas” module is used to compute the standard deviation of the specified DataFame over the requested axis. The “df.std()” method is used to calculate the standard deviation for single, multiple, or entire DataFrame columns. We can also skip None values and specify the delta number of freedoms using the parameter value. This tutorial presented an in-depth guide on determining the standard deviation using numerous examples.