Using for loop
In this scenario, we will iterate the DataFrame records inside a for loop and append each to a list. This list will be a nested list, such that each list holds one chunk of DataFrame record. If you want to access a specific chunk, use the index position and access the records present in a specific chunk.
Syntax:
Let’s see the syntax for splitting the Dataframe into chunks using the for loop.
list1=[]
for records in range(0,len(DataFrame),chunks):
list1.append(DataFrame[records:records+chunks])
Here,
- The total number of rows that have to be present in each chunk is defined by the chunks variable.
- Declare an empty list.
- Iterate the DataFrame records by passing chunks to the step parameter in the for loop.
- Inside the for loop, use the append() method to store each chunk as a list.
DataFrame
Let’s create two DataFrame – Cases with three columns and eight rows. This will be split this DataFrame into chunks using a for loop and store them in a list. Before implementing the examples, first run the below code that will create DataFrame. Otherwise, you will get an error.
# Create DataFrame - cases with 3 columns
cases = pandas.DataFrame({'Related':["Computer","Mobile","Electronic","Electrical","Mechanical","Electronic","Electrical","Mechanical"],
'Source' :["Web","Email","Phone","Web","Email","Phone","Web","Email"],
'Priority':['High','High','Low','Medium','High','Low','Low','Medium']})
print(cases)
Output

Example 1
Split the above DataFrame into two chunks. Store them in a ‘list1’ variable and access each chunk using the index position. Indexing in the list starts with 0. Before that, get the total number of chunks created using the len() function.
list1=[]
for records in range(0,len(cases),chunks):
list1.append(cases[records:records+chunks])
# Get number of chunks
print(len(list1),"\n")
# Return the first chunk of records
print(list1[0],"\n")
# Return the second chunk of records
print(list1[1],"\n")
Output
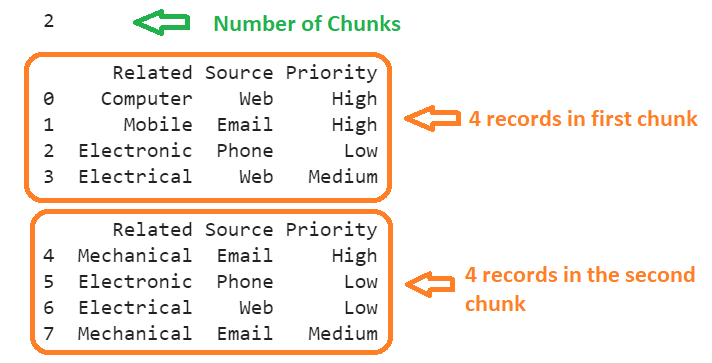
There are eight records on the List. We specified two chunks. So, two chunks are created in the List. The first chunk holds four records, and the second chunk also holds four records.
Example 2
Now, split the DataFrame into three chunks.
list1=[]
for records in range(0,len(cases),chunks):
list1.append(cases[records:records+chunks])
# Get number of chunks
print(len(list1),"\n")
# Return the first chunk of records
print(list1[0],"\n")
# Return the second chunk of records
print(list1[1],"\n")
# Return the third chunk of records
print(list1[2],"\n")
Output

The first chunk holds three records, the second chunk holds three records, and the last chunk holds two records.
1. Using List Comprehension
It is similar to the above scenario. Instead of appending, we will create List Comprehension, and specify the for loop within the List Comprehension, and store the chunks.
Syntax
Let’s see the syntax of splitting the Dataframe into chunks using the List Comprehension.
Example
Use the DataFrame created in the first scenario. Split the above DataFrame into two chunks.
list1 = [cases[records:records+chunks] for records in range(0,len(cases),chunks)]
# Get number of chunks
print(len(list1),"\n")
# Return the first chunk of records
print(list1[0],"\n")
# Return the second chunk of records
print(list1[1],"\n")
Output
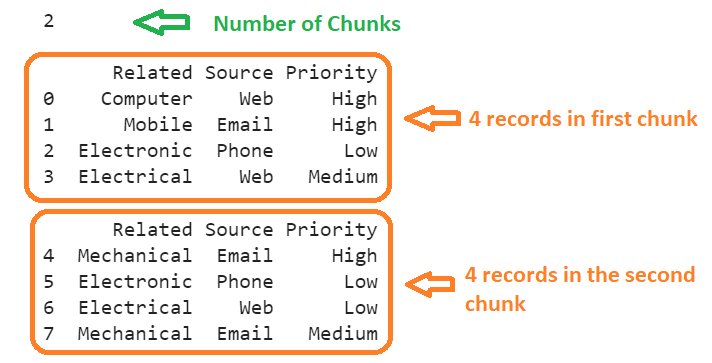
There are eight records in the List. We specified two chunks, so two chunks are created in the List. The first chunk holds four records, and the second chunk also holds four records.
2. Using numpy.array_split()
Basically, the numpy.array_split() function is used to split the given input array into multiple sub-arrays. We can utilize this function to split the pandas DataFrame into chunks.
Syntax
Let’s modify the existing syntax and specify the DataFrame instead of a numpy array.
- The first parameter is the input DataFrame which is split.
- We need to specify the number of splits (chunks).
- By default (axis = 0), it will split the DataFrame by rows. Set axis to 1 to split the pandas DataFrame by columns.
Example 1: by Rows
Create DataFrame named cases with three columns and eight records, and split it into three chunks by rows.
import numpy
# Create DataFrame - cases with 3 columns and 8 records
cases = pandas.DataFrame({'Related':["Computer","Mobile","Electronic","Electrical","Mechanical","Electronic","Electrical","Mechanical"],
'Source' :["Web","Email","Phone","Web","Email","Phone","Web","Email"],
'Priority':['High','High','Low','Medium','High','Low','Low','Medium']})
print(cases,"\n")
#Split DataFrame into 3 chunks of rows
stored_array=numpy.array_split(cases, 3)
# Get the chunks
print(stored_array[0],"\n")
print(stored_array[1],"\n")
print(stored_array[2])
Output
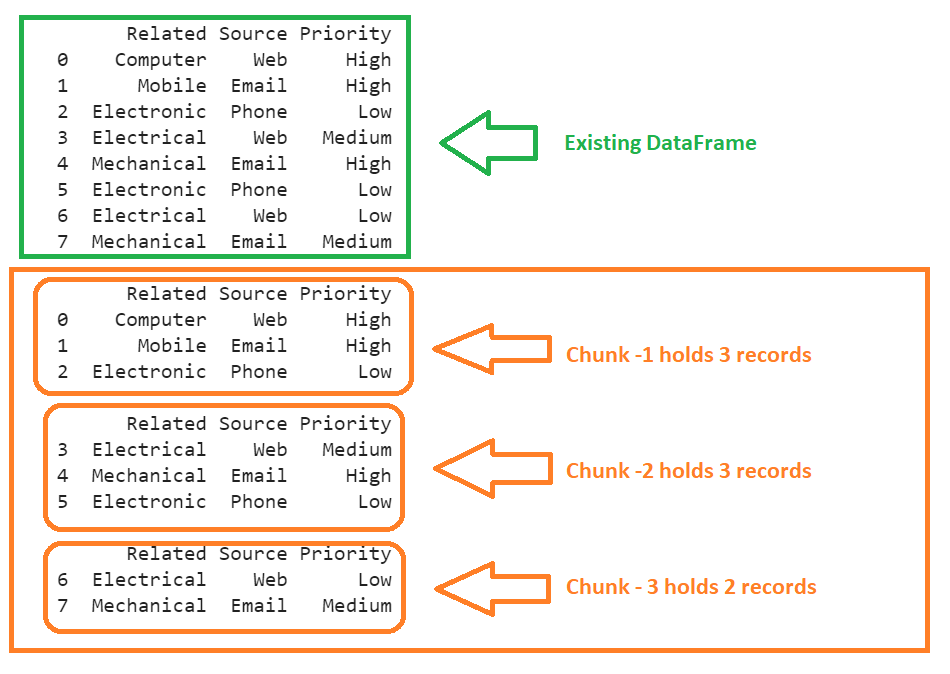
There are eight records in the DataFrame. We specified three chunks, so three sub-arrays are created. The first two sub-arrays hold three records each, and the last sub-array holds two records.
Example 2: by Columns
Create a DataFrame named ‘cases’ with five columns and two records, and split it into two chunks by columns. Get the rows from each chunk by using the index positions. Pass the axis parameter by setting it to 1.
import numpy
# Create DataFrame - cases with 5 columns and 2 records
cases = pandas.DataFrame({'Related':["Computer","Mobile"],
'Source' :["Web","Email"],
'Priority':['High','High'],
'Subject':['Battery issue','Sync issue'],
'Impact':['No','Yes']})
print(cases,"\n")
# Split DataFrame into 2 chunks
chunks=numpy.array_split(cases, 2,axis=1)
# Get the chunks
print(chunks[0],"\n")
print(chunks[1])
Output
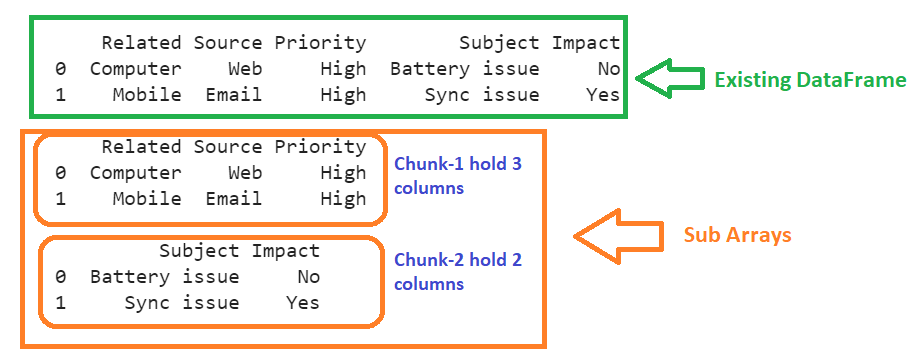
There are five columns in the DataFrame. Two sub-arrays are created as we specified chunks=2. The first sub-array holds three columns, and second sub-array holds remaining two columns.
3. Using pandas.DataFrame.loc[]
Basically, we will use the loc[] property to get the values based on the index labels. We can use this function to store the chunk of records in a variable.
Example 1: by Column
Create a DataFrame named ‘cases’ with five columns and two records and split it into two chunks by columns.
- Store the first two columns in cases1.
- Store the remaining three columns in cases1.
# Create DataFrame - cases with 5 columns and 2 records
cases = pandas.DataFrame({'Related':["Computer","Mobile"],
'Source' :["Web","Email"],
'Priority':['High','High'],
'Subject':['Battery issue','Sync issue'],
'Impact':['No','Yes']})
print(cases,"\n")
# Split the DataFrame by columns
# First chunk hold 2 columns
cases1 = cases.iloc[:,:2]
# Second chunk hold remaining columns
cases2 = cases.iloc[:,2:]
print(cases1,"\n")
print(cases2,"\n")
Output
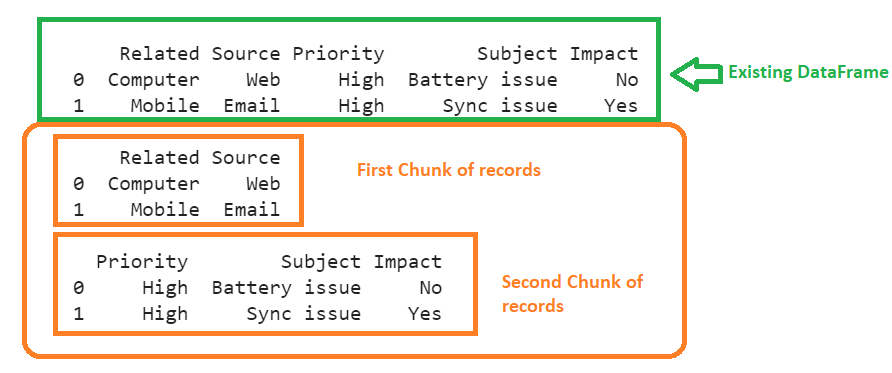
cases.iloc[:,:2] will get the first two columns, and cases.iloc[:,2:] will get the columns after the second column.
Example 2: by Row
Create DataFrame named cases with three columns and eight records and split it into three chunks by rows.
- Store the first two rows in cases1.
- Store the next two rows in cases2.
- Store the next four rows in cases3.
import numpy
# Create DataFrame - cases with 3 columns and 8 records
cases = pandas.DataFrame({'Related':["Computer","Mobile","Electronic","Electrical","Mechanical","Electronic","Electrical","Mechanical"],
'Source' :["Web","Email","Phone","Web","Email","Phone","Web","Email"],
'Priority':['High','High','Low','Medium','High','Low','Low','Medium']})
print(cases,"\n")
# Split the DataFrame by rows
# First chunk hold 2 rows
cases1 = cases.iloc[:2,:]
# Second chunk hold 2 rows
cases2 =cases.iloc[2:4,:]
# Last chunk hold remaining rows
cases3 = cases.iloc[4:,:]
print(cases1,"\n")
print(cases2,"\n")
print(cases3)
Output
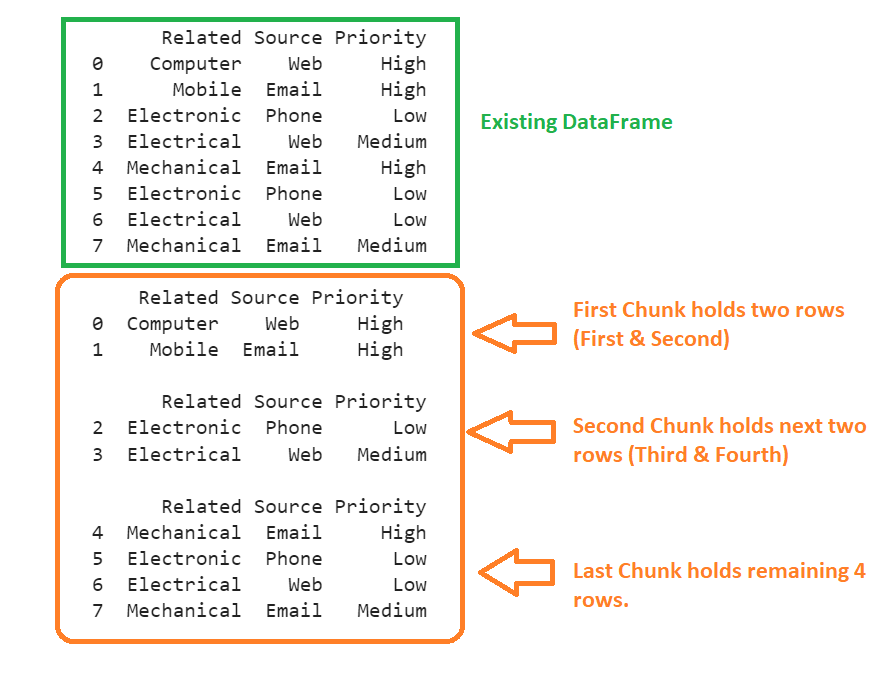
Cases.iloc[:2,:] will get the first two rows, and cases.iloc[2:4,:] will get the next two rows, and cases.iloc[4:,:] get all the remaining rows from the DataFrame.
Conclusion
Now, you are able to split the pandas DataFrame into chunks using any of the four approaches discussed in this guide. Under each approach, two examples are discussed for better understanding. Both for loop and List Comprehension approaches are the same since we are storing the chunks in a List.