The pandas.read_sql() reads the SQL query or a table from the database into the Pandas DataFrame. It supports only two databases: SQLAlchemy and sqlite3. All the examples that we discuss in this guide are sqlite3.
Syntax:
Let’s see the syntax and the parameters that are passed to this function:
- The sql is the SQL query or table name. Example: SELECT columns from table.
- index_col (by default = None) – The existing column/s are utilized as index for the DataFrame. If not, Index column is None and the row indices are assigned starting from 0.
- parse_dates (by default = None) – If the sql query/table holds the date type columns, we can parse the columns with specific format by specifying this parameter. It takes a dictionary such that the key is the column and the value takes the format. Example: {“Column”: {“format”: “%d/%m/%y”},…}.
- chunksize (by default = None) – It specifies the number of rows to include in each chunk.
Example 1: To_Sql() Function
In this example, we create a DataFrame with five records and store the records in the “Campaign” table by establishing the connection to an in−memory SQLite database using the to_sql() function.
Finally, we read the SQL query that holds all the columns from the “Campaign” table into the “result” DataFrame. Here, connect(‘:memory:’) is the in−memory SQLite database.
import pandas
camps_data = pandas.DataFrame(data=[[1, 'Webinar', 'Planned'],
[2, 'Conference', 'Aborted'],
[3, 'Trade Show', 'In Progress'],
[4, 'Public Relations', 'Aborted'],
[5, 'Conference', 'Completed']],columns=['Id', 'Type','Status'])
# Store the records of the DataFrame in the Campaign table
# by establishing the connection to an in−memory SQLite database.
conn=connect(':memory:')
camps_data.to_sql('Campaign', conn)
# Read SQL query that hold all the columns from the Campaign table into the DataFrame - result
result= pandas.read_sql('SELECT * from Campaign', conn)
print(result)
Output:

Now, the “result” DataFrame holds all the columns since we selected all the columns (*). The “Index” column is created for the DataFrame and the row index starts from 0.
Example 2: Parse_Dates Parameter
Create a DataFrame with five records that are related to Campaign. The “StartDate” and “EndDate” are the two columns that we need to parse as date in the DataFrame. Pass the parse_dates parameter to the read_sql() function and assign the “%d/%m/%y” format to it.
from sqlite3 import *
import pandas
# Create DataFrame with 5 records related to Campaign
camps_data = pandas.DataFrame(data=[[1, 'Webinar', 'Planned', '25/05/23','27/05/23'],
[2, 'Conference', 'Aborted', '01/01/23','03/03/23'],
[3, 'Trade Show', 'In Progress', '22/01/22','22/02/22'],
[4, 'Public Relations', 'Aborted', '22/01/22','22/02/22'],
[5, 'Conference', 'Completed', '11/06/23','17/06/23']],columns=['Id', 'Type','Status', 'StartDate', 'EndDate'])
conn=connect(':memory:')
camps_data.to_sql('Campaign', conn)
# Read SQL query into the DataFrame - result by parsing StartDate and EndDate columns
result= pandas.read_sql('SELECT StartDate, EndDate from Campaign', conn,parse_dates={"StartDate": {"format": "%d/%m/%y"},"EndDate": {"format": "%d/%m/%y"}})
print(result)
Output:
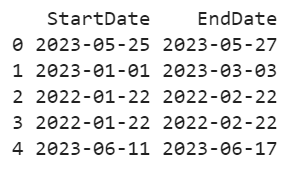
You can see that the values in these two columns are in the “YYYY-MM-DD” format. Here, “25/05/23” is considered as date/month/year.
Example 3: Index_Col Parameter
Let’s set the “Id” column as index to the DataFrame. Set the index_col to “Id”.
import pandas
camps_data = pandas.DataFrame(data=[[1, 'Webinar', 'Planned'],
[2, 'Conference', 'Aborted'],
[3, 'Trade Show', 'In Progress'],
[4, 'Public Relations', 'Aborted'],
[5, 'Conference', 'Completed']],columns=['Id', 'Type','Status'])
conn=connect(':memory:')
camps_data.to_sql('Campaign', conn)
# Set Id column as Index
result= pandas.read_sql('SELECT * from Campaign', conn,index_col='Id')
print(result)
Output:

For the previous DataFrame, the “Id” column is the index.
Example 4: Columns Parameter
- Create a “Case_Detail” database in sqlite3 and create a cursor object.
- Create the “Cases” table in the previous database with three columns and execute it using the cursor object.
- Insert five records into the table.
- Read the query by specifying the connection.
- Get the data into the DataFrame with the “Case_Type” and “Status” columns.
import pandas
# Create database - Case_Detail in sqlite3 and create cursor
conn = sqlite3.connect('Case_Detail.db')
cursor = conn.cursor()
# Create table - Cases in the above database with three columns and execute it using the cursor object.
create_table_query ="""CREATE TABLE Cases(Case_Type VARCHAR(255), Source VARCHAR(255),Status VARCHAR(255));"""
cursor.execute(create_table_query)
# Insert 5 records into the table
cursor.execute('''INSERT INTO Cases VALUES ('Computer', 'Phone', 'Closed')''')
cursor.execute('''INSERT INTO Cases VALUES ('Mechanic', 'Web', 'Open')''')
cursor.execute('''INSERT INTO Cases VALUES ('Electrical', 'Phone', 'Open')''')
cursor.execute('''INSERT INTO Cases VALUES ('Mechanic', 'Web', 'Closed')''')
cursor.execute('''INSERT INTO Cases VALUES ('Others', 'Email', 'Closed')''')
# Read the query by specifying the connection
query = pandas.read_sql('SELECT * FROM cases',conn)
# Get the data into the DataFrame with 'Case_Type','Status' columns.
result=pandas.DataFrame(query,columns=['Case_Type','Status'])
print(result)
Output:

The DataFrame holds only two columns.
Conclusion
The pandas.read_sql() reads the SQL query or a table from the database into the Pandas DataFrame. In this guide, we learned the four examples by considering different parameters that are passed to this function. The n−memory SQLite database is used in the first three examples. In the last example, we created the database with the table inside it.