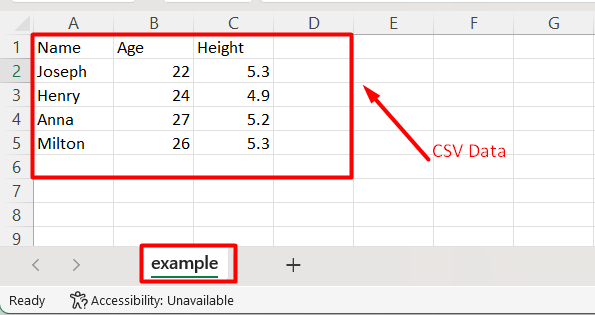
Multiprocessing is a technique of using multiple processors or cores to perform tasks in parallel. In Python, multiprocessing is implemented through the multiprocessing module. It authorizes the user to execute multiple tasks concurrently, thereby utilizing the full power of the machine’s CPU.
In this Python guide, we will present an in-depth guide on the “pandas.read_csv()” function with a multiprocessing module. The following topics will be covered:
“pandas.read_csv()” Function in Python
The “pandas.read_csv()” is a function in Python’s Pandas module that reads/takes a CSV file and retrieves a DataFrame object containing the data from the CSV.
Syntax
Example 1: Reading CSV Using “pandas.read_csv()” Function
In the below example, the “pandas.read_csv()” function is used to read the CSV data:
Code
df = pandas.read_csv('example.csv')
print(df)
In the above code snippet:
-
- The module named “pandas” is imported.
- The “pd.read_csv()” function is used to read the provided CSV file.
- The “print()” function is utilized to display/show the CSV data.
Output
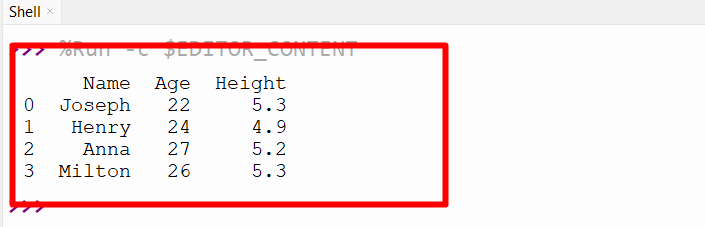
As observed, the CSV file contents have been displayed.
Example 2: Reading CSV Using “pandas.read_csv()” With Multiprocessing
The following code utilizes the “pd.read_csv()” function to read multiple CSV files in parallel using the multiprocessing library in Python:
import multiprocessing
if __name__ == '__main__':
pool = multiprocessing.Pool()
files = ['example.csv', 'example1.csv', 'example2.csv']
dataframes = pool.map(pandas.read_csv, files)
for df in dataframes:
print(df)
According to the above code:
-
- The modules named “pandas” and “multiprocessing” modules are imported.
- The “__name__” and “__main__” attributes are used with the “if” condition to ensure that the code within it executes directly from the script rather than being imported.
- Inside the condition, the “multiprocessing.Pool()” is used to create a multiprocessing pool object using the default number of processes available on the system.
- The list of filenames for the CSV files to be read is initialized and stored in a variable named “files”.
- The “pool.map()” method is used to apply the “pd.read_csv” function to each file in parallel. This means that each file is read simultaneously by a separate process, which can speed up the overall processing time.
- Finally, the “for” loop is used to iterate through each data frame.
Output
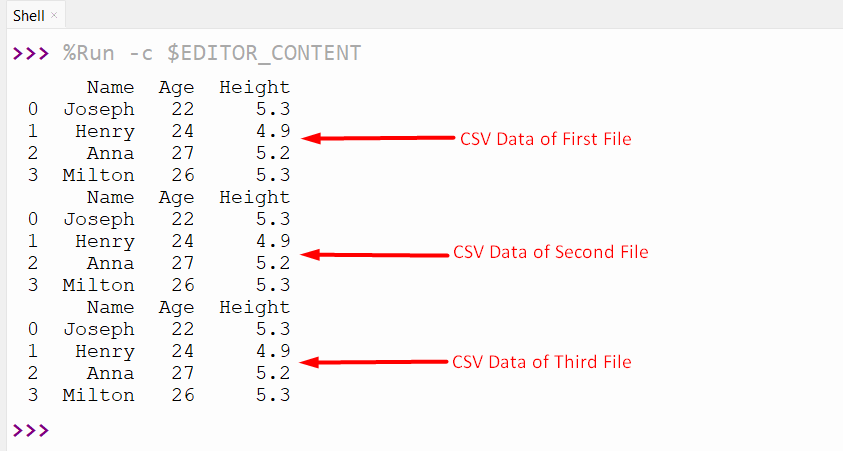
In this outcome, the “pd.read_csv()” function is used with multiprocessing to read CSV files.
Conclusion
To improve the data loading speed, including its benefits and limitations the “pd.read_csv()” function is used with the multiprocessing module. The multiprocessing model offers a way to speed up data loading by utilizing multiple CPU cores to load the data in parallel. This Python tutorial presented an in-depth guide on Python read_csv multiprocessing.