The “pandas” module is used to work with “DataFrames”, which are tabular structures that can store various Data types. This module provides different methods to work with DataFrame. While working with DataFrame, we sometimes may be required to determine the largest value of the specified DataFrame columns. To do this, the “DataFrame.nlargest()” method is utilized in Python.
This blog will talk about:
- What is the “DataFrame.nlargest()” Method in Python?
- Retrieve the Largest/Maximum Value of the Specified Columns of the CSV
- Retrieve the Largest/Maximum Value of the Specified Multiples Columns of CSV
- Retrieve the Largest/Maximum Value by Using the “keep=” Parameters
What is the “DataFrame.nlargest()” Method in Python?
The “DataFrame.nlargest()” method of the “pandas” module is used to retrieve the number of “n” specified rows ordered by columns in descending order. It is utilized to determine the specified number of largest DataFrame or Series values.
Syntax
Parameters
In the above syntax:
- The “n” parameter represents the number of rows to retrieve.
- The “columns” parameter represents the column labels to check for values.
- The “keep=” parameter specifies which value to assign if the duplicates exist. The default value is “first” which prioritizes the first occurrences. The “all” value is used when we do not drop any duplicates. The “last” value is used to prioritize the last occurrences.
Return Value
This method retrieves the DataFrame containing the number of rows arranged by the specified columns in descending order.
Example 1: Retrieve the Largest/Maximum Value of the Specified Columns of the CSV
In the below code, the “pandas.read_csv()” method reads the Comma Separated Value file and retrieves the DataFrame. Next, the “df.nlargest()” method takes the number of rows “5” and column labels as an argument to retrieve the largest value in the form of descending order:
df = pandas.read_csv("new.csv")
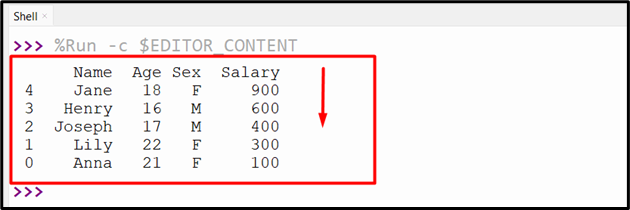
print(df.nlargest(5, "Salary"))
The above code retrieves the below DataFrame with a specified column value in descending order with the largest value at the top:
Example 2: Retrieve the Largest/Maximum Value of the Specified Multiples Columns of CSV
We can also retrieve and sort the value in descending order of the specified multiple columns of CSV using the “df.nlargest()” method. The multiple-column labels are passed to the “df.nlargest()” method as an argument and retrieve the DataFrame with a specified number of rows in descending order:
df = pandas.read_csv("new.csv")
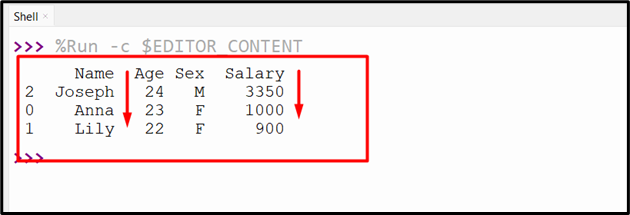
print(df.nlargest(3, ['Salary', 'Age']))
The specified multiple columns of CSV have been extracted into the new DataFrame in order from largest to smallest:
Example 3: Retrieve the Largest/Maximum Value by Using the “keep=” Parameters
The “keep=” parameter is useful when we have the same multiple values in the specified columns of the Pandas DataFrame. The “keep=last” is used when we want only the last occurrences from the same values. The “keep=all” is used when we want all the same multiple values to the output. Here is an example code that retrieved a specified number of rows in descending order based on the “keep=” parameter value:
df = pandas.read_csv("new.csv")
print(df.nlargest(3, "Salary", keep='last'), '\n')
print(df.nlargest(3, "Salary", keep='all'))
The below snippet shows the DataFrame columns values in descending order by keeping the last occurrence of multiple same occurrences and retrieving all the occurrences:

Conclusion
The “DataFrame.nlargest()” method retrieves the particular “n” rows in reverse/descending order, with the largest value first. We can also pass the column names as a list to the “DataFrame.nlargest()” method to retrieve the multiple column values in the largest to smallest sorting order. This tutorial delivered a detailed guide on the “DataFrame.nlargest()” method using several examples.