The pandas.DataFrame.groupby() function is used to group the DataFrame by a series of columns. The aggregate operations like mean, sum, min, and max are used along with this function to return the results on the grouped data.
Scenarios:
- GroupBy with Multiple Columns
- GroupBy with Multiple Columns to Aggregate a Single Column
- GroupBy with Multiple Columns along with the Aggregate() Function
- GroupBy Multiple Aggregations with Multiple Columns
- GroupBy with Multiple Columns: Different Aggregations Per Column
Example DataFrame:
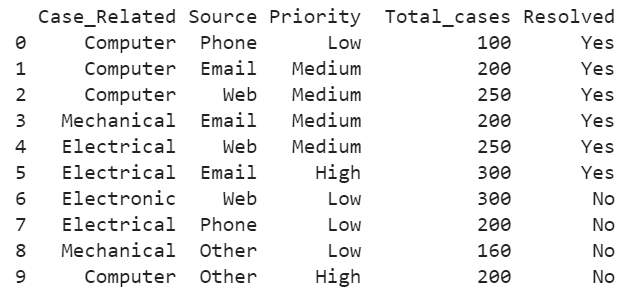
In this entire guide, we will use the following DataFrame named detail_cases with 10 records. The columns are “Case_Related”, “Source”, “Priority”, “Total_Cases”, and “Resolved”.
# Create DataFrame with 4 columns that holds 10 records
detail_cases = pandas.DataFrame({'Case_Related': ['Computer','Computer','Computer','Mechanical','Electrical',
'Electrical','Electronic','Electrical','Mechanical','Computer'],
'Source': ['Phone','Email','Web','Email','Web','Email','Web','Phone','Other','Other'],
'Priority':['Low','Medium','Medium','Medium','Medium','High','Low','Low','Low','High'],
'Total_cases':[100,200,250,200,250,300,300,200,160,200],
'Resolved':['Yes','Yes','Yes','Yes','Yes','Yes','No','No','No','No']})
print(detail_cases)
Output:
GroupBy with Multiple Columns
In this scenario, we group the multiple columns in the DataFrame. The column names are passed through a list to the groupby() function. Look at the following syntax:
Example 1:
- Group by “Source” and “Priority”, and get the average of Total_cases.
- Group by “Source” and “Priority”, and get the sum of Total_cases.
print(detail_cases.groupby(['Source','Priority']).mean(),"\n")
# Group by 'Source','Priority' and get sum of Total_cases
print(detail_cases.groupby(['Source','Priority']).sum())
Output:
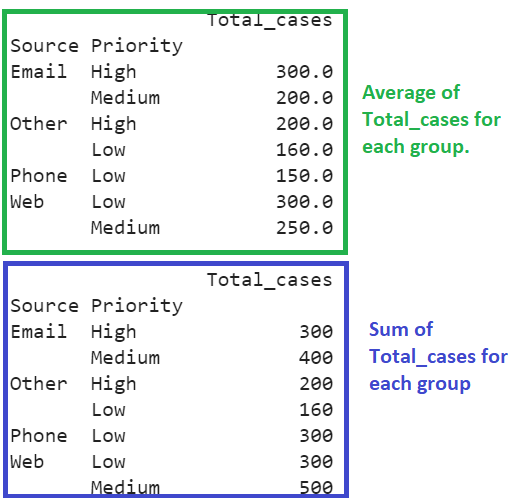
The number of grouped records that are based on the “Source” and “Priority” columns are 4.
First Output:
- The average Total_cases of “Email” with “High” priority is 300 and with “Medium” priority is 200.
- The average Total_cases of “Other” with “High” priority is 200 and with “Low” priority is 160.
- The average Total_cases of “Phone” with “Low” priority is 150.
- The average Total_cases of “Web” with “Low” priority is 300 and with “Medium” priority is 250.
Second Output:
- The sum of Total_cases of “Email” with “High” priority is 300 and with “Medium” priority is 400.
- The sum of Total_cases of “Other” with “High” priority is 200 and with “Low” priority is 160.
- The sum of Total_cases of “Phone” with “Low” priority is 300.
- The sum of Total_cases of “Web” with “Low” priority is 300 and with “Medium” priority is 500.
Example 2:
Group by “Source”, “Priority”, “Resolved”, and get the count using the count() aggregate function.
print(detail_cases.groupby(['Source','Priority','Resolved']).count())
Output:

You can see that the count aggregation is applied for the two columns (Case_Related and Total_cases). If you want to apply it on the specific column, go to the next scenario.
GroupBy with Multiple Columns to Aggregate a Single Column
If you want to aggregate on the single column for the grouped records, you need to specify the column after the groupby().
Example:
- Group by “Source” and “Priority”, and get the minimum of Total_cases.
- Group by “Source” and “Priority”, and get the maximum of Total_cases.
print(detail_cases.groupby(['Source','Priority'])['Total_cases'].min(),"\n")
# Group by 'Source','Priority' and get maximum of Total_cases
print(detail_cases.groupby(['Source','Priority'])['Total_cases'].max())
Output:
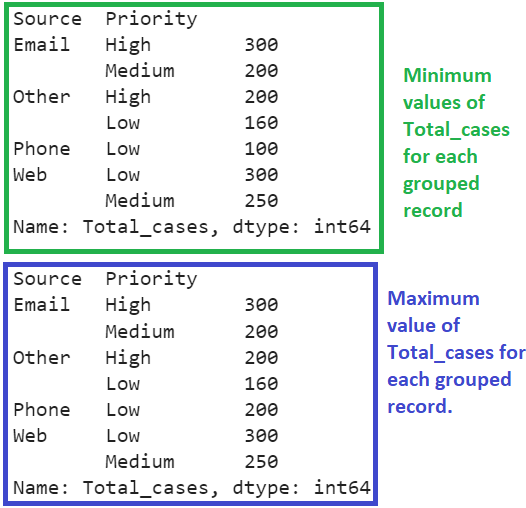
The minimum value of Total_cases is returned for each grouped record in the first output and the maximum value of Total_cases is returned for each grouped record in the second output.
GroupBy with Multiple Columns along with the Aggregate() Function
Using the aggregate function – agg()/aggregate() – we can perform the aggregation operations like mean(), min(), sum(), and max(). It takes the aggregation functions as a parameter.
Example:
- Group by “Source” and “Priority”, and get the average of Total_cases using agg() by passing the “mean” as a parameter.
- Group by “Source” and “Priority”, and get the sum of Total_cases using agg() by passing the “sum” as a parameter.
print(detail_cases.groupby(['Source','Priority']).agg('mean'),"\n")
# Group by 'Source','Priority' and get sum of Total_cases
print(detail_cases.groupby(['Source','Priority']).agg('sum'),"\n")
Output:
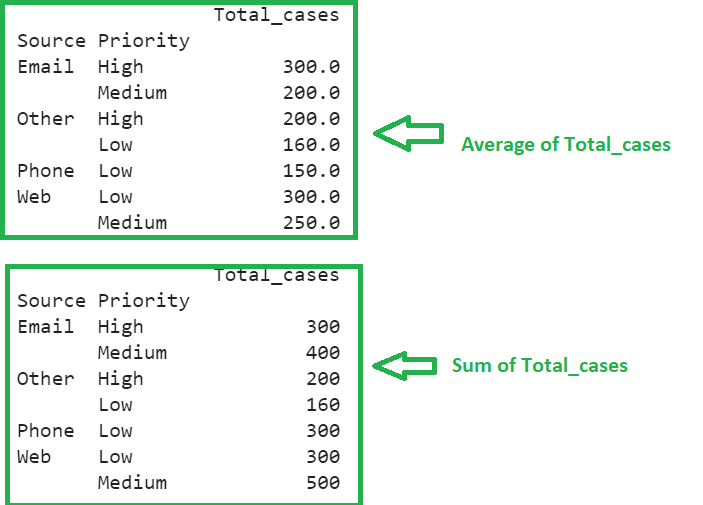
GroupBy Multiple Aggregations with Multiple Columns
At a time, we can perform multiple aggregations with multiple columns. The aggregate functions are passed through a list as a parameter to the aggregate() function. Same aggregations are performed on all the columns. Look at the following syntax:
Example:
Group by “Source” and “Priority”, and get the count and minimum values from the other two columns.
# Group by ‘Source’,’Priority’ and get count and minimum values from the other 2 columns.
Output:
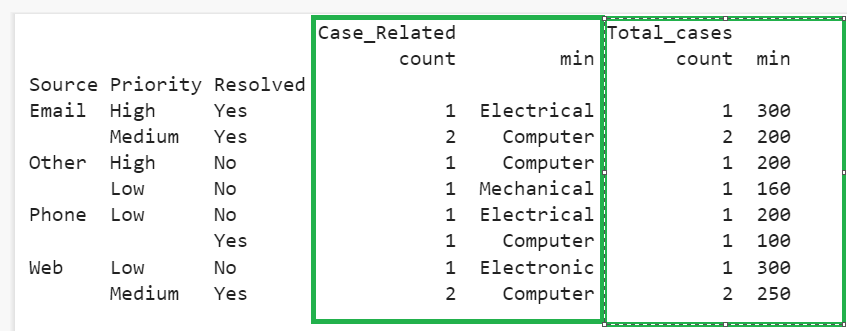
You can see the count and minimum in the Case_Related as well as in the Total_cases column in each group.
GroupBy with Multiple Columns: Different Aggregations Per Column
Now, we will see how to perform the different aggregations for each column. To achieve this, we need to pass a dictionary as a parameter with the key as a column name and the value as the aggregate function.
Example 1:
Group by “Source” and “Priority”, and perform the count() aggregation on the “Source” column and mean() aggregation on the Total_cases column.
print(detail_cases.groupby(['Resolved','Priority']).aggregate({'Source':'count','Total_cases':'mean'}))
Output:

Example 2:
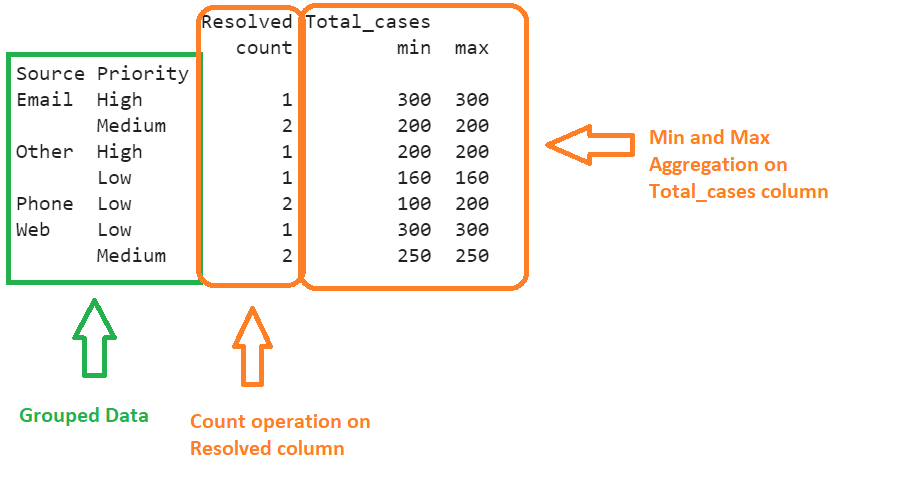
In this example, we group the “Source” and “Priority” columns and get the count of the “Resolved” column. Also, return the minimum and maximum values from the Total_cases in the grouped data.
# Also return the minimum and maximum values from the Total_cases in the grouped data.
print(detail_cases.groupby(['Source','Priority']).agg({'Resolved':'count','Total_cases':['min','max']}))
Output:
Conclusion
In this guide, we learned how to group the DataFrame by multiple columns by considering five different scenarios. The Pandas.DataFrame.groupby() function is used to group the DataFrame by a series of columns. The aggregate operations like mean, sum, min, and max are used along with this function to return the results on the grouped data. Only one DataFrame is considered in all the scenarios. Make sure that you include the DataFrame code snippet in your Python environment before implementing the examples.