In data science or dealing with large groups of data, we often deal with missing values. The missing values occur or are placed in data due to different reasons, such as human error, sensor failures, or incomplete records. Missing values can affect the quality or accuracy of the data, so we need to handle them properly. We can represent missing values by using the “NaN”. However, NaN values can cause problems when performing calculations or applying functions to Data. To solve this problem, we replace the NaN value with zeros using different methods.
This blog will provide a thorough overview of filling NaN values with “0” using several examples.
How to Fill NaN With “0” in Python Pandas?
The following methods are used to fill NaN with zeros in Python:
- Fill NaN With “0” Using the “DataFrame.fillna()” Method
- Fill NaN With “0” Using the “DataFrame.replace()” Method
- Fill NaN With “0” Using the “DataFrame.apply()” Method
Method 1: Fill NaN With “0” Using the “DataFrame.fillna()” Method
The “DataFrame.fillna()” method is utilized to fill NA/NaN values utilizing particular methods. We can use this method to fill NaN values of the DataFrame columns with “Zeros”.
Syntax
Parameters
In the above syntax:
- The “value” parameter represents the value that is used to fill the specified values. (e.g. 0).
- The “method” parameter specifies the method that is used for filling holes in the reindexed Series.
- The “axis” parameter represents the axis along which to put missing/NaN values.
- The “inplace” parameter represents a boolean value that indicates whether to fill in place or not. If True the original object is modified otherwise a new object is retrieved.
- The “limit” parameter is an integer value that indicates the maximum number of consecutive NaN values to forward/backward fill.
- For a further detailed understanding of the syntax, you can check this guide.
Return Value
The “DataFrame.fillna()” retrieves the DataFrame/Series with missing values filled.
Example 1: Replace NaN with “0” on all Columns
In this example, the “Pandas.DataFrame()” method takes the dictionary data and creates the DataFrame with specified columns with NaN values. Next, the “DataFrame.fillna()” method takes the value “0” and fills the NaN value of the entire DataFrame columns:
import numpy
df = {'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],
'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]}
df = pandas.DataFrame(df)
print(df, '\n')
df1 = df.fillna(0)
print(df1)
The DataFrame columns with NaN values have been replaced with “Zeros”:

Example 2: Replace NaN with “0” on Single Columns
We can also replace or fill the NaN values of the single columns with “zeros” of Pandas DataFrame. Take the following code to do this:
import numpy
df = {'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],
'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]}
df = pandas.DataFrame(df)
print(df, '\n')
df["Age"] = df["Age"].fillna(0)
print(df)
The below snippet fills the NaN value of single columns with “zeros” of Pandas DataFrame:
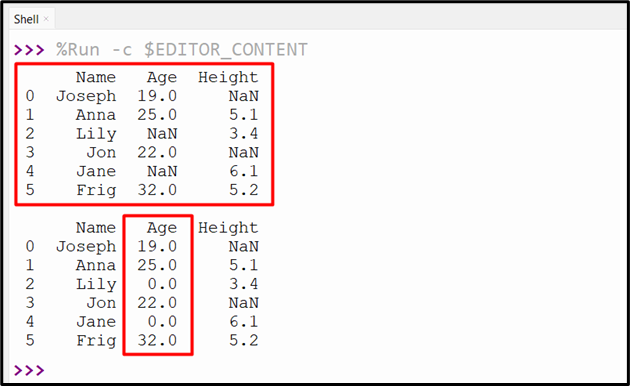
Example 3: Replace NaN with “0” on Multiple Columns
We can also fill the NaN values of the multiple columns of DataFrame with zeros in Python. The below code replaces NaN with “zeros” of multiple columns:
import numpy
df = {'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],
'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]}
df = pandas.DataFrame(df)
print(df, '\n')
df[["Age", "Height"]] = df[["Age", "Height"]].fillna(0)
print(df)
After executing the above code you will get the following output:
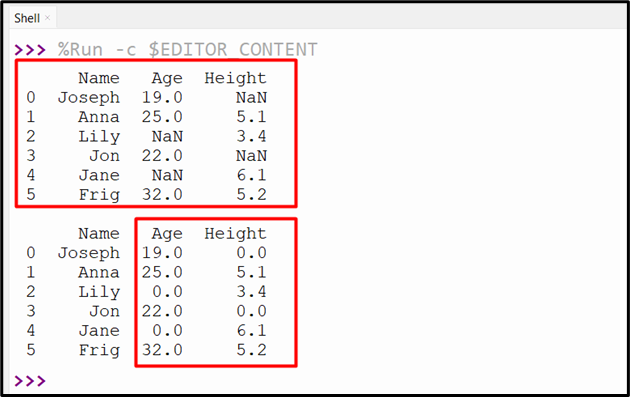
Method 2: Fill NaN With “0” Using the “DataFrame.replace()” Method
The “DataFrame.replace()” method is used to replace the specified NaN values with the “zeros”.
Syntax
For a detailed understanding of the “DataFrame.replace()” method you can go through this guide.
In this example code, we use the “replace()” method to replace the specified “NaN” values of the single DataFrame with zeros. Take the following code to do this replacement:
import numpy
df = {'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],
'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]}
df = pandas.DataFrame(df)
print(df, '\n')
df["Age"] = df["Age"].replace(numpy.nan, 0)
print(df)
The below output shows the DataFrame by replacing the NaN values with “0”:

We can also replace the NaN values present in the entire DataFrame columns using the “df.replace()” method. Use the code below to accomplish this task:
import numpy
df = {'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],
'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]}
df = pandas.DataFrame(df)
print(df, '\n')
df1 = df.replace(numpy.nan, 0)
print(df1)
The above code retrieves the below output:
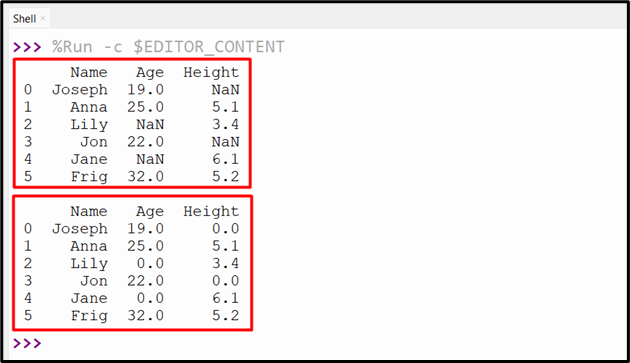
Method 3: Fill NaN With “0” Using the “DataFrame.apply()” Method
The “DataFrame.apply()” method is used to apply the specified method to the specified DataFrame columns. This method can also be utilized to replace the NaN values with the “Zeros”:
For an in-depth understanding of this method, you can check this tutorial.
Here, we define the custom function that returns the value “0” if the passed value is “NaN” otherwise the same “NaN” value is retrieved. The “df.apply()” method is used to apply the specified function to the specified DataFrame columns and fills the NaN value with “Zeros”:
def funct(value):
if pandas.isna(value):
return 0
else:
return value
df=pandas.DataFrame({'Name':["Joseph","Anna","Lily", "Jon", "Jane", "Frig"],'Age' :[19,25, numpy.nan, 22, numpy.nan, 32],
'Height':[numpy.nan, 5.1, 3.4, numpy.nan, 6.1, 5.2]})
print(df, '\n')
df["Age"]=df["Age"].apply(funct)
print(df)
The above code retrieves the below output:

Conclusion
In Python, the “df.fillna()”, “df.replace()” and the “df.apply()” methods are used to fill or replace the NA/NaN values with zeros. These methods are used to fill the NaN values of single, multiple, or entire DataFrame columns with the “zero” value. This guide delivered a comprehensive tutorial on filling NaN values with “0” utilizing numerous examples.