Index refers to the position of the sequence element in Python, as it starts at “0” and goes on until the last element of the sequence. But in Pandas DataFrame, the “Index” refers to the row labels. This means the first row has a “0” label, and the second row has a “1” label by default. We can also create a custom index using various methods of Python and add it to the Pandas DataFrame. However, while working with Pandas DataFrame, we may encounter index duplication that causes ambiguity. To address this issue, the “Index.drop_duplicates()” method can be used in Python.
This article presents a detailed step-by-step tutorial on dropping duplicate index via the below-provided content:
- What is the Pandas “drop_duplicates()” in Python?
- Using “drop_duplicates()” Method to Drop All Duplicates Index
- Using “drop_duplicates()” Method to Drop Duplicates Index Except for the First Occurrence
What is the Pandas “Index.drop_duplicates()” in Python?
In Python, the “Index.drop_duplicates()” method removes/drops all the duplicate indexes, the first or last occurrence of the duplicate index. The syntax of the “Index.drop_duplicates()” method is shown below:
In the above syntax:
- The “keep= ‘first’” is a default parameter value utilized to drop/remove duplicate indexes except for the first occurrence.
- The “keep=False” parameter value drops/removes all the duplicate indexes.
- The “keep= ‘last’” parameter value drops/removes duplicate indexes except for the last occurrence.
Return Value
The “Index.drop_duplicates()” method retrieves the index with duplicate values removed.
Example 1: Using “Index.drop_duplicates()” Method to Drop All Duplicates Index
This example is implemented to drop all the duplicates index:
index_1 = pandas.Index([12, 12, 3, 3, 11, 3, 23, 21])
print('Original Index:\n', index_1)
print('\nAfter Removing Duplicate Index:\n',index_1.drop_duplicates(keep = False))
Here in this code:
- The “pandas” module is imported.
- The “Index()” function is used to create the specified index value.
- The “drop_duplicates()” method takes the “keep = False” parameter as an argument and retrieves the index value by removing all duplicate index values.
Output
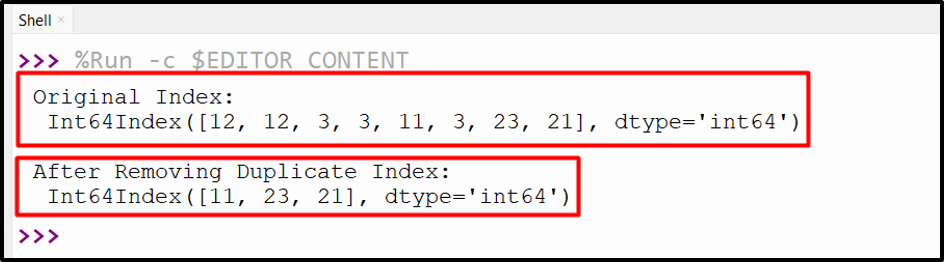
The index without any duplicate value has been returned successfully.
Example 2: Using “Index.drop_duplicates()” Method to Drop/Removes Duplicates Index Except for the First Occurrence
This example drops the duplicate index except for the first occurrence:
index_1 = pandas.Index([12, 12, 3, 3, 11, 3, 23, 21])
print('Original Index:\n', index_1)
print('\nAfter Removing Duplicate Index:\n',index_1.drop_duplicates(keep = 'first'))
In the above code:
- The “pandas” module is imported.
- The “drop_duplicates()” method takes the “keep = ‘first’” parameter value as an argument and retrieves the index except for the first occurrence.
Output
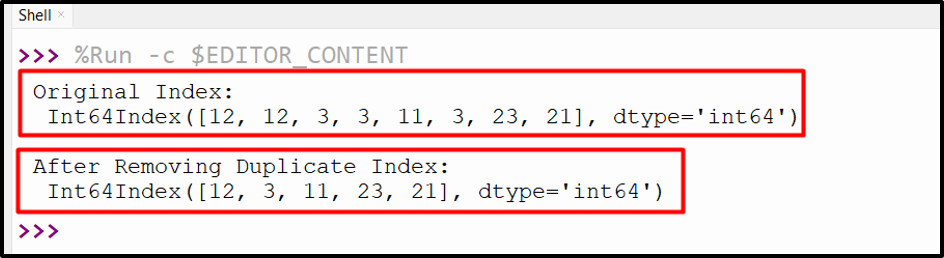
The input index and after removing the duplicate index have been shown in the above output.
Note: Similarly, the “keep=last” parameter value is used for dropping duplicate indexes except for the last occurrence.
Conclusion
The “Index.drop_duplicates()” method in Python is used to remove the duplicate indexes by taking the specified “keep” parameter value. The “keep=False” parameter value removes all the duplicate indexes. While the “keep= first” or “keep = last” removes all the indexes except the first occurrence or last occurrence, respectively. This guide presented an extensive overview of how to drop Pandas duplicate index via numerous examples.