“Pandas” provides several methods to perform data analysis and manipulation operations on data. In Python, while working with a Pandas DataFrame, we often need to extract unique or distinct values from a specific column. To accomplish this, various methods are used in Python.
This write-up will provide a comprehensive guide on selecting Pandas distinct from the Pandas DataFrame column using numerous examples.
How to Get/Determine Distinct Values From Pandas DataFrame Column?
To get distinct values from the Pandas DataFrame column, the following methods are used in Python:
- Using “pandas.unique()” Function
- Using “Series.unique()” Function
- Using “Numpy.unique()” Function
- Using “pandas.concat()” Method
Method 1: Get Distinct Values From Pandas DataFrame Column Using “pandas.unique()” Function
The “pandas.unique()” function is utilized to get distinct unique values from the Pandas DataFrame column. Here is an example code:
data1 = {'Name':["Anna","Joseph","Lily","Henry","Lily","Anna","Henry"],'Age' :[18,22,33,13,33,18,13],'Height':[5.7,3.7,4.9,5.5,3.7,5.7,5.5],'Salary':['$100','$300','$500','$700','$300','$100','$700']}
df = pandas.DataFrame(data1)
print(df, '\n')
df1 = pandas.unique(df[['Name']].values.ravel())
print(df1)
In the above example:
- The “pandas” module is imported.
- The “pd.DataFrame()” function takes/accepts the dictionary as an argument and constructs a DataFrame.
- The “pandas.unique()” function is utilized to determine the unique value in the “Name” column of Pandas DataFrame.
- The “ravel()” method is used along with the “pandas.unique()” function to flatten the column into a one-dimensional array.
Output
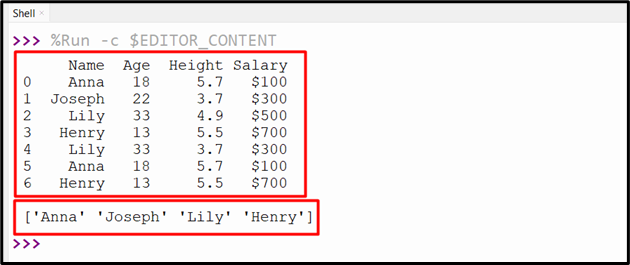
The unique value from the specified column has been returned in the output.
We can also get distinct values from the multiple columns of Pandas DataFrame. Here is an example code:
data1 = {'Name':["Anna","Joseph","Lily","Henry","Lily","Anna","Henry"],'Age' :[18,22,33,13,33,18,13],'Height':[5.7,3.7,4.9,5.5,3.7,5.7,5.5],'Salary':['$100','$300','$500','$700','$300','$100','$700']}
df = pandas.DataFrame(data1)
print(df, '\n')
df1 = pandas.unique(df[['Name', 'Age']].values.ravel())
print(df1)
Here in this code:
The “pandas.unique()” function gets the distinct values from the more than one column of Pandas DataFrame.
Output
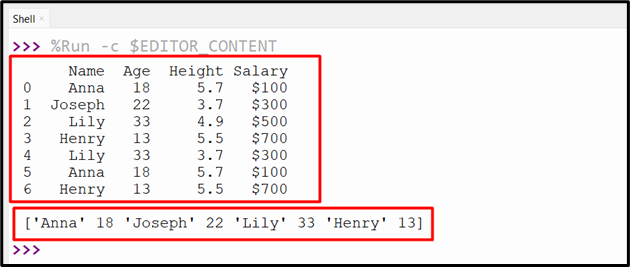
The distinct values of multiple columns have been returned.
Method 2: Get Distinct Values From Pandas DataFrame Column Using “Series.unique()” Function
The “Series.unique()” function can also be used to get distinct or unique values from the Pandas DataFrame column. Let’s overview the below code:
data1 = {'Name':["Anna","Joseph","Lily","Henry","Lily","Anna","Henry"],'Age' :[18,22,33,13,33,18,13],'Height':[5.7,3.7,4.9,5.5,3.7,5.7,5.5],'Salary':['$100','$300','$500','$700','$300','$100','$700']}
df = pandas.DataFrame(data1)
print(df, '\n')
print(df['Name'].unique())
Here in this code:
The “Series.unique()” method is applied to the column “Name” to get the distinct values from the Pandas DataFrame column.
Output
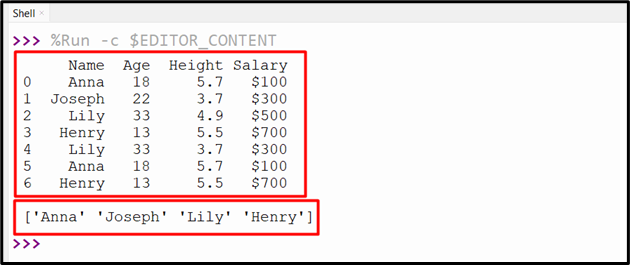
The distinct value of the specified column has been returned in the output.
Method 3: Get Distinct Values From Pandas DataFrame Column Using “Numpy.unique()” Function
The “numpy.unique()” function can also be used to get the distinct values from the Pandas DataFrame column. Here is an example:
import numpy
data1 = {'Name':["Anna","Joseph","Lily","Henry","Lily","Anna","Henry"],'Age' :[18,22,33,13,33,18,13],'Height':[5.7,3.7,4.9,5.5,3.7,5.7,5.5],'Salary':['$100','$300','$500','$700','$300','$100','$700']}
df = pandas.DataFrame(data1)
print(df, '\n')
df1 = numpy.unique(df[['Name', 'Salary']].values)
print(df1)
In the above code:
The “numpy.unique()” function of the “numpy” module is applied to the multiple columns named “Name” and “Salary” and returns the distinct value by removing the duplicate value.
Output
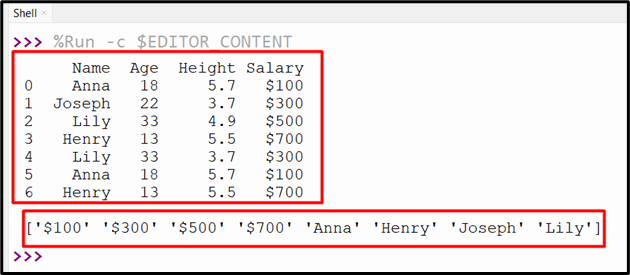
The distinct value of the multiple columns has been returned.
Method 4: Get Distinct Values From Pandas DataFrame Column Using “pandas.concat()” Method
The “pandas.concat()” method is used along with the “unique()” function to get the distinct values from Pandas DataFrame. Let’s examine this method via the following code:
data1 = {'Name':["Anna","Joseph","Lily","Henry","Lily","Anna","Henry"],'Age' :[18,22,33,13,33,18,13],'Height':[5.7,3.7,4.9,5.5,3.7,5.7,5.5],'Salary':['$100','$300','$500','$700','$300','$100','$700']}
df = pandas.DataFrame(data1)
print(df, '\n')
df1 = pandas.concat([df['Name'],df['Age']]).unique()
print(df1)
In this code block:
- The “pandas.concat()” and “unique()” methods are applied on the multiple Pandas DataFame columns “Name” and “Age” to get the unique/distinct value.
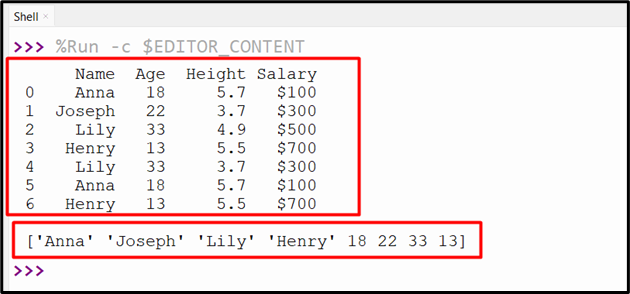
The unique value of the specified column has been returned by removing the duplicate value.
Conclusion
The “pandas.unique()”, “Series.unique()”, “Numpy.unique()”, and “pandas.concat()” methods are used to get distinct values of the Pandas DataFrame column. The “Pandas.unique()” function is used to get the distinct or unique value of a single or multiple DataFrame column by removing the duplicate item. This guide has presented various methods to get distinct values of Pandas DataFrame columns using numerous examples.