Syntax:
Let’s see the syntax and parameters that are passed to this function:
- As we already discussed, the data is the necessary parameter to create a DataFrame. It can be a list of tuples or structured array (example: NumPy array) or other DataFrame or list of dictionaries.
- It is possible to set the row indices for creating the DataFrame using the “index” parameter (by default = None). It takes a list of index labels. If it is not specified, the DataFrame is created with default row indices [0, 1, 2,..n-1].
- We can exclude the existing columns from the data while creating the DataFrame using the “exclude” parameter (by default = None). It takes a list of column labels to be removed.
- While creating the DataFrame, we can specify the column labels using the “columns” parameter (By default = None). If the existing data holds the column labels already, they are replaced with the specified column names if it is specified.
- The “coerce_float” parameter (by default = False) is set to “True” if you want to convert the decimal type columns to float.
- The “nrows” parameter (by default = None) reads a specific number of rows into the DataFrame if the data is an iterator. It reads all the rows if the parameter is not specified. It takes an integer that specifies the number of rows.
1. Create a DataFrame
Let’s see how to create a DataFrame from the list of types, list of dictionaries, and structured array with separated examples.
Example 1: From a List of Tuples
Let’s create a “Products” DataFrame from a list of tuples. There are five tuples in the list and each tuple holds two elements. The first element is the integer and the second element is the string.
list_of_tuples = [(101, 'Furniture'), (102, 'Paints'), (103, 'Steel/Iron'), (104, 'Plastic'), (105, 'Cement & sand')]
# Create DataFrame from list of tuples using from_records()
Products = pandas.DataFrame.from_records(list_of_tuples)
print(Products)
Output:

The “Products” DataFrame is created with five rows. The first column holds the integer values and the second column holds the strings from the tuples. The columns and indices of the DataFrame start with 0 by default.
Example 2: From a List of Dictionaries
Let’s create a “Products” DataFrame from a list of dictionaries. There are five dictionaries in the list such that each dictionary holds the “P_id” as the key and the “P_name” as the value.
list_of_dictionaries = [{'P_id': 101, 'P_name': 'Furniture'},
{'P_id': 102, 'P_name': 'Paints'},
{'P_id': 103, 'P_name': 'Steel/Iron'},
{'P_id': 104, 'P_name': 'Plastic'},
{'P_id': 105, 'P_name': 'Cement & sand'}]
# Create DataFrame from list of dictionaries using from_records()
Products = pandas.DataFrame.from_records(list_of_dictionaries)
print(Products)
Output:

The “Products” DataFrame is created with five rows along with the column labels (from the dictionary key). The first column holds the integer values and the second column holds the strings from the tuples.
Example 3: From a Structured Array
Let’s create a “Products” DataFrame from the NumPy array. The NumPy array is created with five tuples with two elements each. While creating the array, we also specify the data type with labels. The first element in each tuple is the “i” integer and the data type of the second element in each tuple is U16 (16-character string).
import numpy
array = numpy.array([(101, 'Furniture'), (102, 'Paints'), (103, 'Steel/Iron'), (104, 'Plastic'), (105, 'Cement & sand')],dtype=[('P_id', 'i'), ('P_name', 'U16')])
# Create DataFrame from the structured ndarray using from_records()
Products = pandas.DataFrame.from_records(array)
print(Products)
Output:
The “Products” DataFrame is created with five rows along with the column labels (from dtype).
2. With the Columns Parameter
Let’s see how to create a DataFrame by passing the “columns” parameter to the function.
Example 1:
Let’s create a “Products” DataFrame from a list of dictionaries. There are five dictionaries with key:value pairs.
- First, we create a DataFrame with the existing columns that are present in the dictionary.
- Now, we pass the “columns” parameter with the columns in order [“Price”, “P_id”, “P_name”].
list_of_dictionaries = [{'P_id': 101, 'P_name': 'Furniture','Price':34000},
{'P_id': 102, 'P_name': 'Paints','Price':45000},
{'P_id': 103, 'P_name': 'Steel/Iron','Price':50000},
{'P_id': 104, 'P_name': 'Plastic','Price':12000},
{'P_id': 105, 'P_name': 'Cement & sand','Price':22000}]
# Without columns parameter
Products = pandas.DataFrame.from_records(list_of_dictionaries)
print(Products,"\n")
# With columns parameter
Products = pandas.DataFrame.from_records(list_of_dictionaries,columns=['Price','P_id','P_name'])
print(Products)
Output:
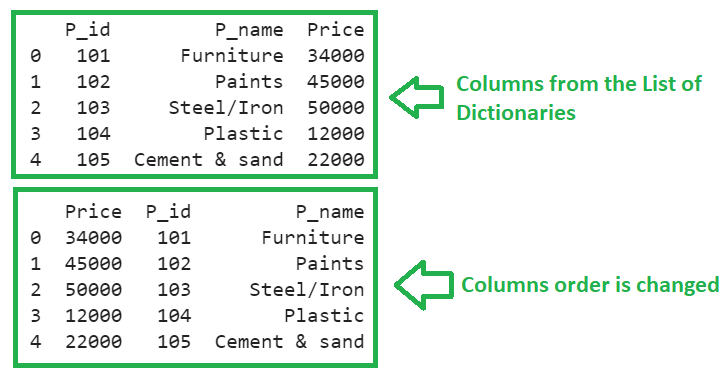
In the first output, the DataFrame is created from the list of dictionaries. In the second output, we specify the columns in different order. So, the columns are interchanged.
Example 2:
Let’s create a “Products” DataFrame from a list of tuples. There are five tuples with two elements each. Create a DataFrame from a list of tuples by specifying the columns [“P_id”, “P_name”].
list_of_tuples = [(101, 'Furniture'), (102, 'Paints'), (103, 'Steel/Iron'), (104, 'Plastic'), (105, 'Cement & sand')]
Products = pandas.DataFrame.from_records(list_of_tuples,columns=['P_id','P_name'])
print(Products,"\n")
Output:

The DataFrame is created with column labels.
3. With the Index Parameter
Let’s see how to create a DataFrame by including the custom row indices.
Example:
Let’s create a “Products” DataFrame from a list of dictionaries by specifying the row indices as [“product-1”, “product-2”, “product-3”, “product-4”, “product-5”].
list_of_dictionaries = [{'P_id': 101, 'P_name': 'Furniture'},
{'P_id': 102, 'P_name': 'Paints'},
{'P_id': 103, 'P_name': 'Steel/Iron'},
{'P_id': 104, 'P_name': 'Plastic'},
{'P_id': 105, 'P_name': 'Cement & sand'}]
# Specify the Index
Products = pandas.DataFrame.from_records(list_of_dictionaries,index=['product-1','product-2','product-3','product-4','product-5'])
print(Products,"\n")
Output:
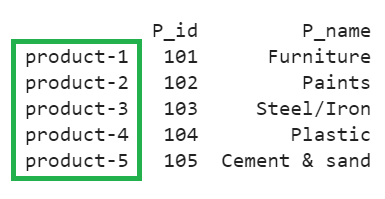
The DataFrame is created from a list of dictionaries with the specified row indices.
4. With the Exclude Parameter
Let’s see how to create a DataFrame by excluding the columns.
- Create a “Products” DataFrame from a list of dictionaries with columns.
- Create the same DataFrame by excluding single column (“Price”).
- Create the same DataFrame by excluding multiple columns (“Price”, “P_id”, “P_name”).
list_of_dictionaries = [{'P_id': 101, 'P_name': 'Furniture','Price':34000},
{'P_id': 102, 'P_name': 'Paints','Price':45000},
{'P_id': 103, 'P_name': 'Steel/Iron','Price':50000},
{'P_id': 104, 'P_name': 'Plastic','Price':12000},
{'P_id': 105, 'P_name': 'Cement & sand','Price':22000}]
Products = pandas.DataFrame.from_records(list_of_dictionaries)
print(Products,"\n")
# exclude single columns
Products = pandas.DataFrame.from_records(list_of_dictionaries,exclude=['Price'])
print(Products,"\n")
# exclude all columns
Products = pandas.DataFrame.from_records(list_of_dictionaries,exclude=['Price','P_id','P_name'])
print(Products)
Output:
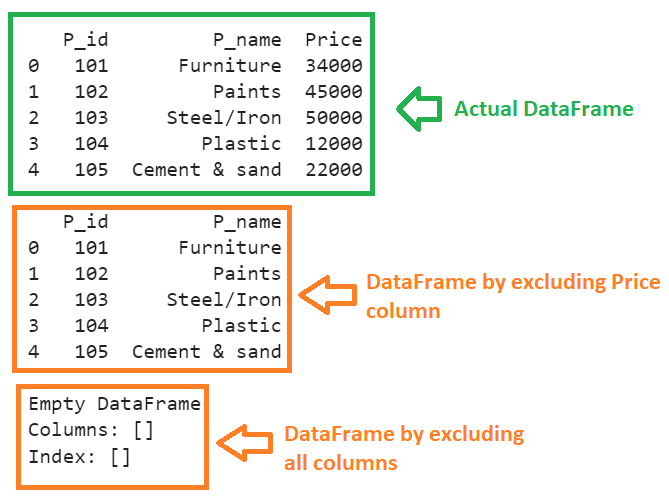
- The DataFrame is created by excluding the “Price” column in the second output.
- In the last output, the DataFrame is created by excluding all the columns. So, the DataFrame is empty.
5. With the Nrows Parameter
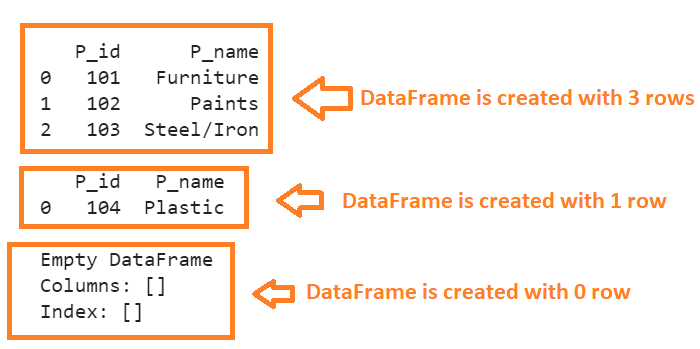
- Create a “Products” DataFrame from a list of tuples with three rows (nrows = 3).
- Create the same DataFrame with one row (nrows = 1).
- Create the same DataFrame with 0 rows (nrows = 0).
list_of_tuples = iter([(101, 'Furniture'), (102, 'Paints'), (103, 'Steel/Iron'), (104, 'Plastic'), (105, 'Cement & sand')])
# Read 3 rows
Products = pandas.DataFrame.from_records(list_of_tuples,columns=['P_id','P_name'],nrows=3)
print(Products,"\n")
# Read 1 row
Products = pandas.DataFrame.from_records(list_of_tuples,columns=['P_id','P_name'],nrows=1)
print(Products,"\n")
# Read 0 row
Products = pandas.DataFrame.from_records(list_of_tuples,columns=['P_id','P_name'],nrows=0)
print(Products)
Output:
Conclusion
Now, you can create the Pandas DataFrame from the array, list of tuples, and list of dictionaries using the pandas.DataFrame.from_records() function. Under the first scenario, we learned the DataFrame creation from the given data. A single or multiple columns can be excluded from the DataFrame while creation by specifying the “exclude” parameter. Lastly, we learned how to create a DataFrame with a specific number of rows by passing the “nrows” parameter.