In Python, the “2-Dimensional” data structure in the pandas module stores the content in tabular format. CSV files are delimited text files that utilize commas as field separators. Sometimes we need to convert the CSV data into DataFrame. To do this, the “pd.read_csv()” method is utilized in Python.
This article will offer a thorough guide on creating Pandas DataFrame from the comma-separated value using several examples. To get started follow the below contents:
- How to Create/Construct Pandas DataFrame From Python CSV?
- Create DataFrame From CSV Using the “pd.read_csv()” Method
- Create DataFrame by Reading Specific Rows of CSV
- Create DataFrame by Reading Specific Columns Value of CSV
- Create DataFrame From CSV Without Header
- Creating DataFrame From CSV with Specified Index Column Value
How to Create/Construct Pandas DataFrame From Python CSV?
The “pandas.read_csv()” method of the “pandas” module is employed to construct the Pandas DataFrame by taking the “Comma Separated Volume” file.
Syntax
Parameter
In the above syntax:
- The “filepath_or_buffer” parameter specifies the file path as a string.
- The “sep” parameter indicates the separator (default= , ) that is used while reading the CSV file.
- The “header” parameter takes integers, a list of integers, and row numbers to utilize as the names of columns. The “header=None” is utilized when no names are given to the parameter and it will show the foremost column as “0”, the second as “1”, and so on.
- The “index_col” parameter indicates the columns that are used as a row label of DataFrame.
- The “usecols” parameter is utilized to retrieve the specified columns from the CSV.
- The “skiprows” and “nrows” parameters are used when we want to skip specific rows or display specified rows while creating a DataFrame.
To get a complete overview of the syntax of the “read_csv()” method you can check this official doc.
Return Value
The “pd.read_csv()” method retrieves the Pandas DataFrame with labeled axes.
Example 1: Create DataFrame From CSV Using the “pd.read_csv()” Method
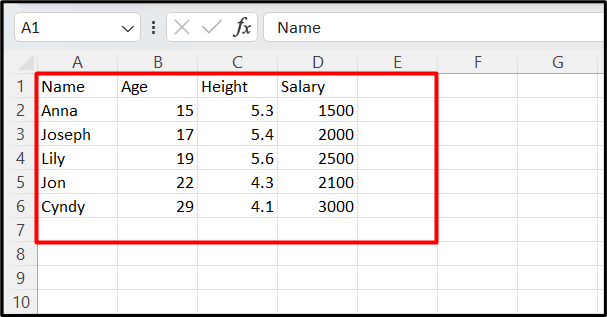
The “pd.read_csv()” method is employed in this example to construct a DataFrame from CSV. Here is the CSV file with its data that needs to be read as DataFrame:
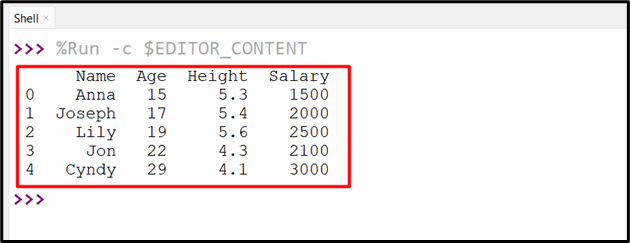
In this code, the “pandas.read_csv()” takes the CSV data and retrieves the DataFrame:
df = pandas.read_csv('new.csv')
print(df)
The DataFrame has been read from the CSV file:
Example 2: Create DataFrame by Reading Specific Rows of CSV
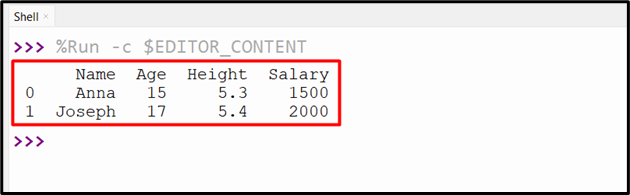
We can also create DataFrame by reading specific rows of CSV using the “df.head()” method. In the below-provided code, the “df.head()” method takes an integer number and retrieves the specified rows. This method is applied after reading the CSV file using the “read_csv()” method:
df = pandas.read_csv('new.csv')
print(df.head(2))
The specified number of rows have been read successfully from the CSV file:
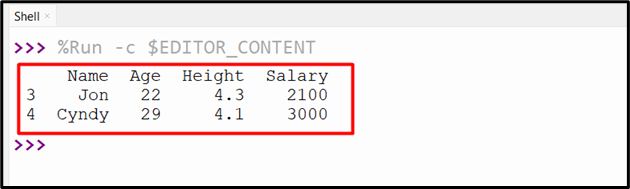
We can also read the CSV files from the bottom using the “df.tail()” method. Here in the below code, the two bottom rows have been selected and retrieved to the output:
df = pandas.read_csv('new.csv')
print(df.tail(2))
The specified number of bottom rows have been read successfully from the CSV file:
Example 3: Create DataFrame by Reading Specific Columns Value of CSV
To read the specific column value of CSV the “usecols=” parameter of the “pandas.read_csv()” method is used in Python. Here is a code that demonstrates the working of this example:
df = pandas.read_csv('new.csv', usecols=["Name", "Age"])
print(df)
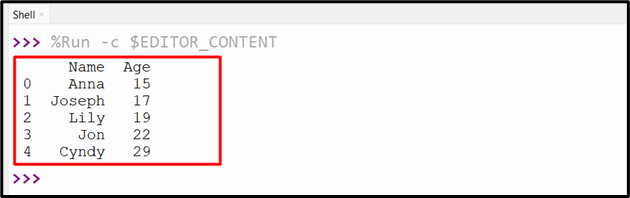
The DataFrame with the specified columns value of CSV has been retrieved successfully:
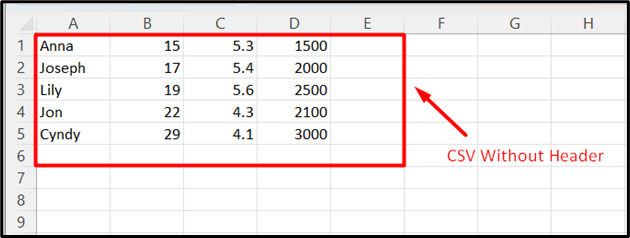
Example 4: Create DataFrame From CSV Without Header
We can create a DataFrame from CSV that does not contain any header value. For example, the following snippet shows the CSV data without any header:
To read the CSV and convert it into DataFrame the “header=None” parameter is used in Python. The “pandas.read_csv()” takes the CSV file name and header as an argument then retrieves the DataFrame:
df = pandas.read_csv('new.csv', header=None)
print(df)
The below snippet shows the DataFrame:
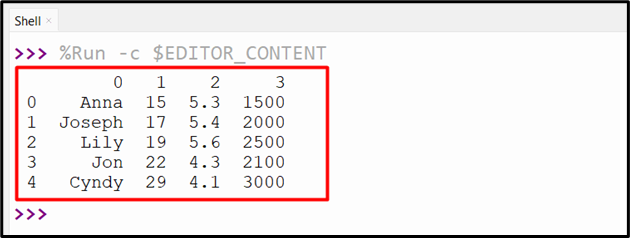
As we can see in the previous output, the header contains the pre-defined number labels. We can also specify the header to the CSV file using the “names=” parameter value of the “pandas.read_csv()” method. Here is an example code:
df = pandas.read_csv('new.csv', names=('Students', 'Age', 'Height', 'Salary'))
print(df)
The below output shows the DataFrame that has been read from CSV and contains the new column labels:
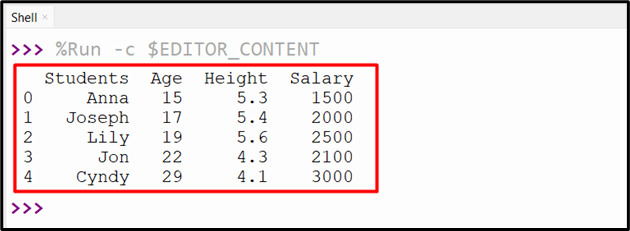
Example 5: Creating DataFrame From CSV with Specified Index Column Value
The DataFrame can also be created from CSV by specifying the column values as an index. We can use the “index_col[]” parameter that accepts the index of the columns of the label of CSV. This parameter with index value is passed to the “pandas.read_csv()” method along with the file name to create a DataFrame with a particular index:
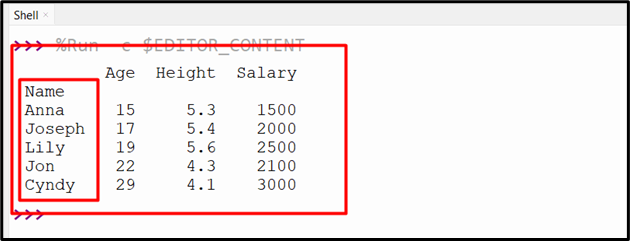
df = pandas.read_csv('new.csv',index_col=[0])
print(df)
The execution of the above code displayed the below output:
Conclusion
In Python, the “pandas.read_csv()” method of the “pandas” module is utilized to read CSV data and convert it into DataFrame. We can use the “pandas.read_csv()” method to read the data without the header, by specifying a new header, a specific number of rows or columns. This tutorial delivered a comprehensive guide on Pandas DataFrame from CSV using numerous examples.