Python is a good choice for data analysis because of the data-focused libraries and tools. In Python, the “pandas” library is used for multiple data functions, such as for joining and merging datasets, adding or removing index columns, and others. We can also join data by cross join which is a type of join operation. This join operation combines each row of the first DataFrame with each row of the second DataFrame. In Python, the “merge()” method of the Pandas module can be used to cross-join the DataFrame using the “outer” join and “cross” join parameter values.
This guide will provide an overview of performing cross-join in Pandas DataFrame. Here is the content to get started:
How to Perform Cross Join in Pandas DataFame in Python?
In Python, the “merge()” function is used to perform a cross-join in Pandas DataFrame. However, there is no direct way to perform a cross-join in Pandas, so we need to create a common key in both DataFrames and merge them using an outer join on the common key.
Syntax
First, we need to create a common key:
df2['key'] = 0
Next, we can apply the outer merge using the below syntax:
Note: If you use the “how=cross” parameter value of the “df.merge()” function then you do not need to create a common key. You just need to create specified DataFrames and perform the cross-join operation using the pandas.merge() method with “how=cross” parameter value.
The illustration of the cross join will look like this:
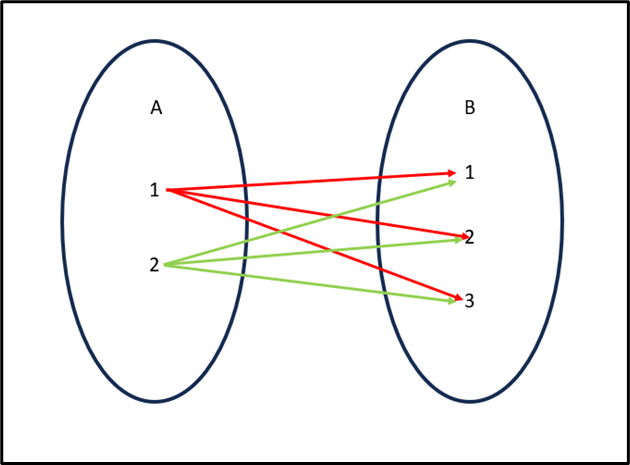
Performing Cross Join on Two DataFrame
The following code is used to cross-join the two DataFrame by using the “pandas.merge()” method:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna']})
print(df1, '\n')
df2 = pandas.DataFrame({'Age': [18, 22, 19]})
print(df2, '\n')
df1['key'] = 0
df2['key'] = 0
df3 = df1.merge(df2, on='key', how='outer')
del df3['key']
print(df3)
In the above code:
-
- First of all, we imported the “pandas” module.
- Next, the “DataFrame()” method is used twice to create two DataFrame with specific column values.
- After that, the new column named “key” is created for the input two DataFrame “df1” and “df2”. Here, the value of the column is zero for all rows.
- Next, the “merge()” method is used to perform an “outer” join between the two DataFrame based on the “key” column.
- Lastly, we use the “del” keyword to delete the key column from the newly merged DataFrame to leave only the columns from “df1” and “df2”.
Output
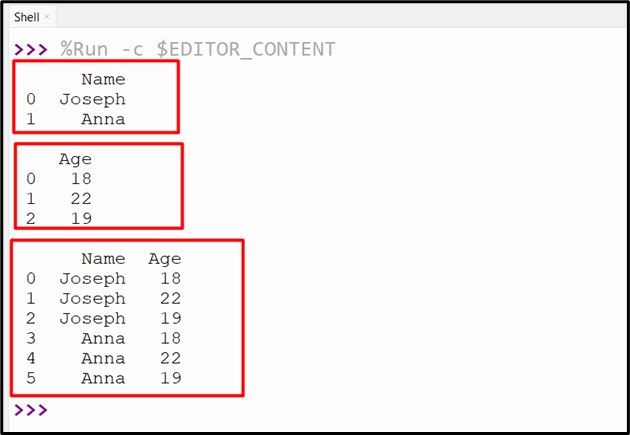
The two DataFrames have been cross joined successfully.
We can also cross-join the two DataFrame using the “cross” parameter value. If we use the cross parameter then we don’t need to create a new column, such as the “key” we created in the previous code. Take the following code as an example:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna']})
print(df1, '\n')
df2 = pandas.DataFrame({'Age': [18, 22, 19]})
print(df2, '\n')
df3 = df1.merge(df2, how='cross')
print(df3)
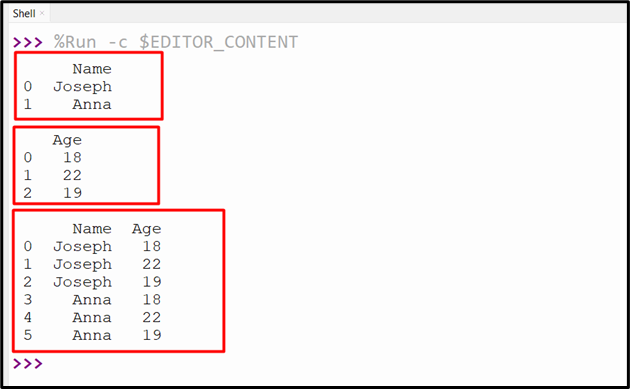
The above code successfully cross-joined the DataFrame:
Performing Cross Join on More Than Two DataFrames
In the below example, we merge more than two DataFrames using the “merge()” method:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna']})
df2 = pandas.DataFrame({'Age': [18, 22, 19]})
df3 = pandas.DataFrame({'Height': [4.8, 5.2, 6.9]})
df1['key'] = 0
df2['key'] = 0
df3['key'] = 0
merged_df = df1.merge(df2, on='key', how='outer').merge(df3, on='key', how='outer')
del merged_df['key']
print(merged_df)
According to the provided code:
-
- We imported the “pandas” module and created three DataFrame using the “pandas.DataFrame()” method.
- Next, we created the new column name “key” for all three DataFrame and assigned the zero value for all rows.
- Next, the “df.merge()” method is used to merge the first two DataFrames based on the key column using an outer join.
- Lastly, the resulting DataFrame has merged again with the third DataFrame based on the key value and using the outer join.
- In the end, the key column is deleted and the rest of the merged DataFrame is displayed.
Output
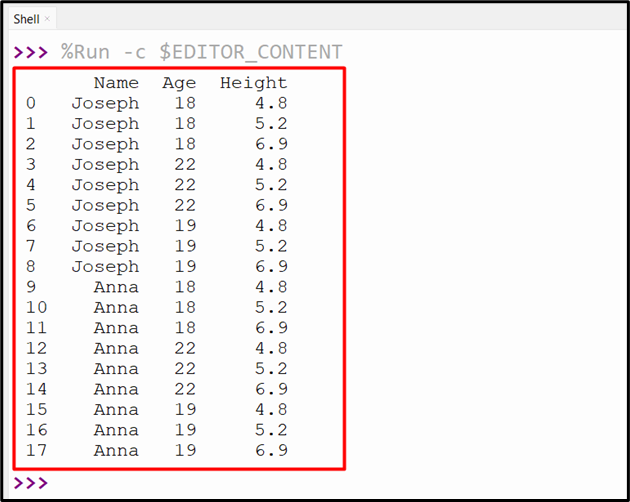
Based on the above output, the multiple DataFrames have been joined successfully.
Conclusion
The “pandas.merge()” method is used with the “how=outer” or “how=cross” parameter value to cross-join the two or more than two DataFrame. The “pandas.merge()” method takes the “how=outer” parameter and applies the outer merge on the specified new column. On the other hand, the “how=cross” does not require the new column as it cross-joins the entire DataFrame column. This guide delivered a detailed overview of how to cross-join pandas using numerous examples.