The Pandas module can be used to combine multiple sources of information into one DataFrame. This module provides various functions to join and merge series. DataFrames of Pandas are based on the indexes, columns, or other values. Concatenation is the way to combine data in Python. The “pandas.concat()” method is used to concatenate along an axis and adjust the indexes accordingly.
This tutorial will explain how to concatenate two Python DataFrames. Let’s start with the below contents:
- How to Concatenate Two Python DataFrames?
- Concatenating Two DataFrames Using “concat()” Method
- Concatenating Two DataFrames along Columns Axis Using “concat()” Method
- Concatenating Two DataFrames With Index Reset Using “concat()” Method
- Concatenating Multiple DataFrames Utilizing “concat()” Method
- Joining Two DataFrames Using “concat()” Method
How to Concatenate Two Python DataFrames?
To concatenate two particular Pandas DataFrame along the specified axis, the “pandas.concat()” method is used in Python. This method concatenates multiple DataFrames of Pandas along columns (axis=1) or along rows (axis=0).
Syntax
Parameter
In the above syntax:
- The “objs” parameter shows the Series or DataFrame objects.
- The “axis” parameter represents the axis along which the DataFrame is concatenated.
- Next, the “join” parameters specify how to manage indexes on the other axis, and the “ignore_index=” parameter specifies when to use the index along the concatenation axis.
- The “keys=” specifies a sequence that adds an identifier to the index output while the “levels=” parameter indicates the unique levels to create a multiindex.
- The “names” parameter is the list specifying the name level of the resulting hierarchical index.
- The “verify_integrity” parameter is used to verify the duplicate value in the new concatenated axis.
- The “sort” parameter is used to sort the non-concatenation axis and the “copy” parameter is used to copy the data based on the boolean value.
Return Value
The “pandas.concat()” method retrieves the Series or DataFrame objects.
Example 1: Concatenating Two DataFrames Using “pandas.concat()” Method
The following code created two DataFrame using the “pandas.DataFrame()” function and concatenated it along the rows using the “pandas.concat()” method. Take this code for further demonstration of this method:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'],
'Age': [16, 19, 22, 28],
'Height': [5.4, 6.1, 5.6, 4.8]})
print('First DataFrame:\n', df1, '\n')
df2 = pandas.DataFrame({'Name': ['Jon', 'Sarah', 'Rooney', 'Jenny'],
'Age': [26, 12, 32, 18],
'Height': [5.2, 6.3, 4.6, 3.8]})
print('Second DataFrame:\n', df2, '\n')
df = pandas.concat([df1, df2])
print(df
The below given output verifies that the two DataFrames have been concatenated:
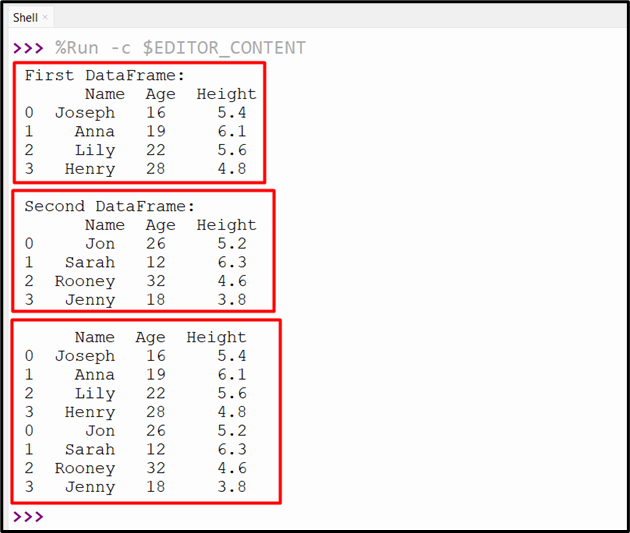
Example 2: Concatenating Two DataFrames along Columns Axis Using “pandas.concat()” Method
We can also concatenate multiple DataFrames along the column’s axis using the “axis=1” parameter value. Here is the code that demonstrates this method:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'],
'Age': [16, 19, 22, 28],
'Height': [5.4, 6.1, 5.6, 4.8]})
print('First DataFrame:\n', df1, '\n')
df2 = pandas.DataFrame({'Name': ['Jon', 'Sarah', 'Rooney', 'Jenny'],
'Age': [26, 12, 32, 18],
'Height': [5.2, 6.3, 4.6, 3.8]})
print('Second DataFrame:\n', df2, '\n')
df = pandas.concat([df1, df2], axis=1)
print(df)
The following snippet shows the concatenated DataFrame along the column axis:
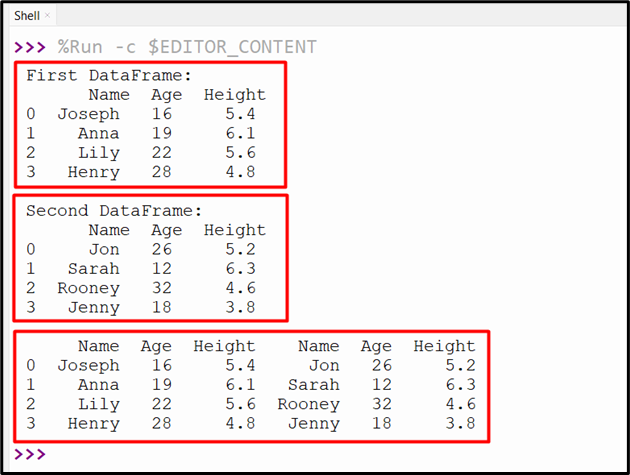
Example 3: Concatenating Two DataFrames With Index Reset Using “pandas.concat()” Method
The following code uses the “ignore_index” value “True” to reset the index after the concatenation of Pandas DataFrame. The parameter is passed to the “pandas.concat()” method along with the concatenate DataFrame object. Here is an example code to concatenate two DataFrames with index reset:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'],
'Age': [16, 19, 22, 28],
'Height': [5.4, 6.1, 5.6, 4.8]})
print('First DataFrame:\n', df1, '\n')
df2 = pandas.DataFrame({'Name': ['Jon', 'Sarah', 'Rooney', 'Jenny'],
'Age': [26, 12, 32, 18],
'Height': [5.2, 6.3, 4.6, 3.8]})
print('Second DataFrame:\n', df2, '\n')
df = pandas.concat([df1, df2], ignore_index=True)
print(df)
The below provided output shows the successful concatenation of two DataFrames objects:
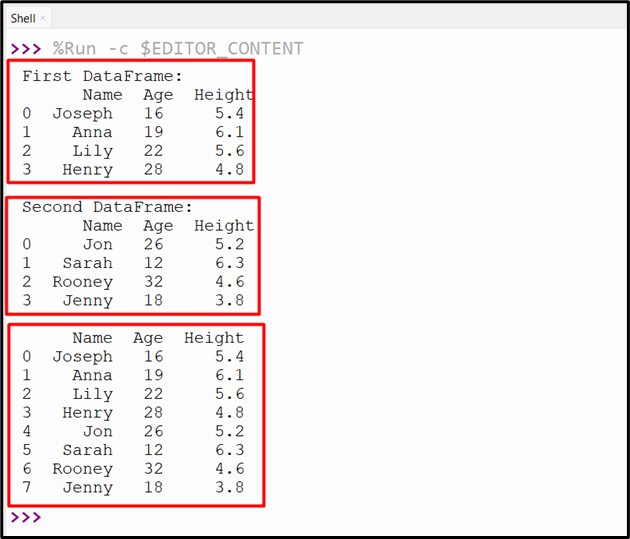
Example 4: Concatenating Multiple DataFrames Using “pandas.concat()” Method
We can also concatenate more than two DataFrames via the “pandas.concat()” method. The following code is used to demonstrate this example:
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'],
'Age': [16, 19, 22, 28],
'Height': [5.4, 6.1, 5.6, 4.8]})
df2 = pandas.DataFrame({'Name': ['Jon', 'Sarah', 'Rooney', 'Jenny'],
'Age': [26, 12, 32, 18],
'Height': [5.2, 6.3, 4.6, 3.8]})
df3 = pandas.DataFrame({'Name': ['Jane', 'Ali', 'Siri', 'Johnson'],
'Age': [16, 22, 12, 38],
'Height': [4.2, 5.3, 5.6, 4.8]})
df = pandas.concat([df1, df2, df3], ignore_index=True)
print(df)
Here is a snippet that verified the concatenation of multiple DataFrames:
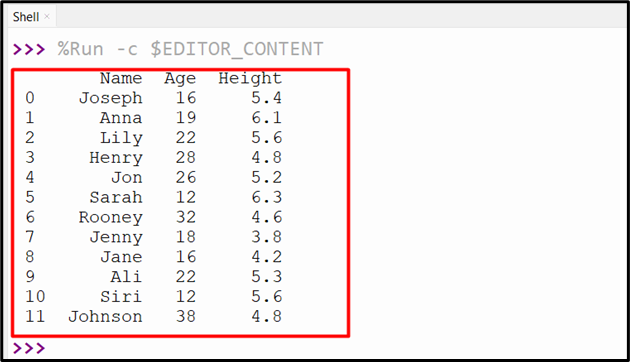
Example 5: Joining Two DataFrames Using “pandas.concat()” Method
We can also use the “join=” parameter to join the two DataFrames using the “pandas.concat()” method. The below code is used to combine two DataFrames:
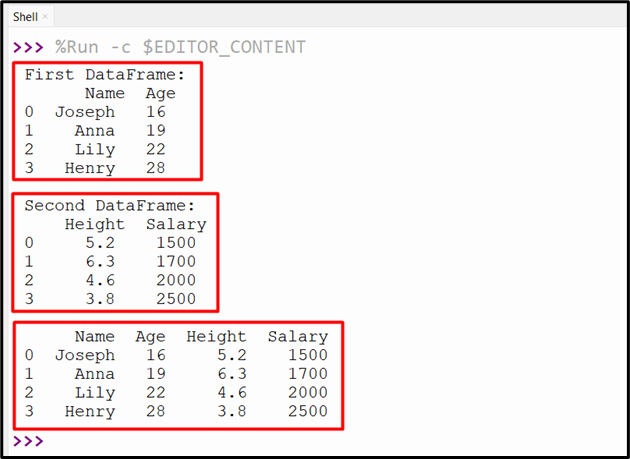
df1 = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'],
'Age': [16, 19, 22, 28]})
print('First DataFrame:\n', df1, '\n')
df2 = pandas.DataFrame({'Height': [5.2, 6.3, 4.6, 3.8],
'Salary': [1500, 1700, 2000, 2500]})
print('Second DataFrame:\n', df2, '\n')
df = pandas.concat([df1, df2], axis=1, join='inner')
print(df)
This output snippet verifies that the Pandas DataFrame has been joined successfully:
Conclusion
The “pandas.concat()” method of the “pandas” module is used to concatenate two DataFrames objects along the axis, such as rows and columns. We can use several parameters like “axis=”, “ignore_index=”, “join=” and others to concatenate two or more than two DataFrames. This blog offered a comprehensive overview of Pandas concatenating two DataFrames using appropriate examples.