Using pandas.DataFrame.combine_first
pandas.DataFrame.combine_first() is used to update the missing (null) elements with values from the same location in another DataFrame. This function combines two DataFrames by filling null values in one DataFrame with non-null values from other DataFrame.
In our scenario, instead of two DataFrames, we will pass another column from the first DataFrame as the second DataFrame. We can use this function on multiple columns also. It will take the value from the first column if it is not null. Otherwise, it will search for non – null in other columns and use that value.
Syntax
Let’s see the syntax of utilizing the combine_first() function.
Example 1
Create a DataFrame named emp_names with FirstName and LastName columns, which may contain some missing values. Use the combine_first() function to coalesce names from the ‘FName’ and ‘LName’ columns into a ‘FullName’ column. This column we are creating in the existing DataFrame only.
# Create DataFrame - emp_names with FirstName and LastName
emp_names = pandas.DataFrame([['Sravan',None],
[None,'Kumar'],
[None,'Sanjay'],
['Bobby','Choudhary'],
['Rani',None]],
columns=['FName', 'LName'])
print(emp_names,"\n")
# Coalesce names from 'FName' and 'LName' columns into 'FullName' column
# using combine_first()
emp_names['FullName']=emp_names['FName'].combine_first(emp_names['LName'])
print(emp_names)
Output
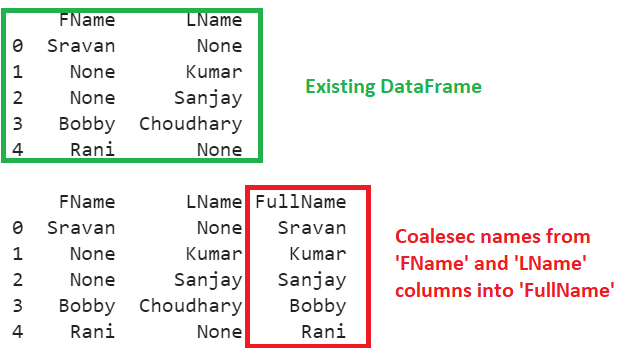
Explanation
- First row – FName is not null, so FullName is ‘Sravan.’
- Second row – FName is null, so FullName will be LName i.e ’kumar.’
- Third row – FName is null, so FullName will be LName i.e ’Sanjay.’
- Fourth row – FName is not null, so FullName is ‘Bobby.’
- Last row – FName is not null, so FullName is ‘Rani.’
Example 2
Create a DataFrame named subject_electives with columns ‘Elective-1,’ ‘Elective-2,’ and ‘Elective-3,’ containing three records that include missing (NULL) values. Use the combine_first() function to coalesce subjects from ‘Elective-1,’ ‘Elective-2,’ and ‘Elective-3’ columns into the ‘Opted Subject’ column.
# Create DataFrame - subject_electives with three subjects
subject_electives = pandas.DataFrame([['java',None,None],
[None,None,'Python'],
[None,'HTML',None]],
columns=['Elective-1', 'Elective-2','Elective-3'])
print(subject_electives,"\n")
# Coalesce subjects from 'Elective-1', 'Elective-2' and 'Elective-3' columns into 'Opted Subject' column
# using combine_first()
subject_electives['Opted Subject']=subject_electives['Elective-1'].combine_first(subject_electives['Elective-2']).combine_first(subject_electives['Elective-3'])
print(subject_electives)
Output

Explanation
- ‘java’ exists in the first column, so it is considered and placed in the ‘Opted Subject’ column.
- ‘Python’ exists in the third column, so it is considered and placed in the ‘Opted Subject’ column.
- ‘HTML’ exists in the second column, so it is considered and placed in the ‘Opted Subject’ column.
Using pandas.DataFrame.bfill
pandas.DataFrame.bfill() known as backward fill which will replace the missing values with the values from the next row or next column in the pandas DataFrame.
Syntax
You will find the actual syntax of bfill() function in this tutorial, and we demonstrate how to use this function in this scenario.
In our scenario, first, we will get the first column values using the iloc[] property. DataFrame.iloc[:, 0]. Now we will pass the bfill() function to set the next column values and store them in the new column of the same DataFrame – bfill(axis=1).iloc[:, 0].
Example 1
Create a DataFrame named emp_names with FirstName and LastName columns, with some missing values. Coalesec names from the ‘FName’ and ‘LName’ columns into the ‘FullName’ column using the bfill() function.
# Create DataFrame - emp_names with FirstName and LastName
emp_names = pandas.DataFrame([['Sravan',None],
[None,'Kumar'],
[None,'Sanjay'],
['Bobby','Choudhary'],
['Rani',None]],
columns=['FName', 'LName'])
print(emp_names,"\n")
# Coalesec names from 'FName' and 'LName' columns into 'FullName' column
# using bfill()
emp_names['FullName']=emp_names.bfill(axis=1).iloc[:, 0]
print(emp_names)
Output
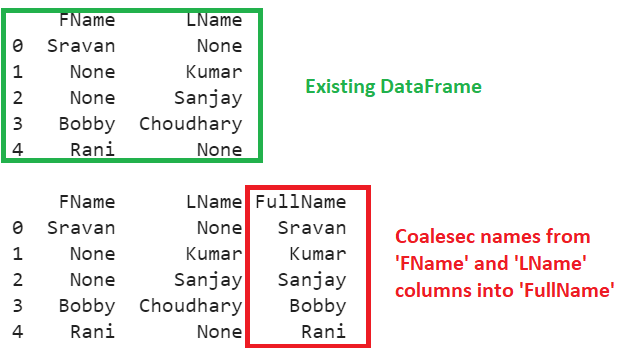
Explanation
- First row – FName is not null, so FullName is ‘Sravan.’
- Second row – FName is null, so the bfill() function fills this with the next column value – ‘Kumar’ and stores it in the ‘FullName’ column.
- Third row – FName is null, so the bfill() function fills this with the next column value – ‘Sanjay’ and stores it in the ‘FullName’ column.
- Fourth row – FName is not null, so FullName is ‘Bobby.’
- Last row – FName is not null, so FullName is ‘Rani.’
Example 2
Let’s have a DataFrame named ‘marks’ with numeric columns: ‘exam-1’ and ‘exam-2,’ with some NA values. Coalesce values from ‘exam-1’ and ‘exam-2’ columns into the ‘Finalized_marks’ column using the bfill() function.
import numpy
# Create DataFrame - marks with exam-1 and exam-2
marks = pandas.DataFrame([[76,numpy.nan],
[100,89],
[89,numpy.nan],
[numpy.nan,numpy.nan],
[numpy.nan,80]],
columns=['exam-1', 'exam-2'])
print(marks,"\n")
# Coalesce values from 'exam-1' and 'exam-2' columns into 'Finalized_marks' column
# using bfill()
marks['Finalized_marks']=marks.bfill(axis=1).iloc[:, 0]
print(marks)
Output
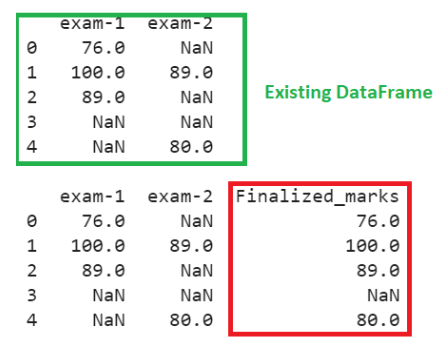
Explanation
First three rows of the first column are not NA, so Finalized_marks will be the same as the first column values. In the fourth row, all the values are NaN, so NaN will be considered. In the last row, the second column has a value of 80.0, and the first value is NA, so 80.0 is considered.
Using pandas.DataFrame.where
pandas.DataFrame.where() is used to replace the values in a pandas Series/DataFrame with the specified value if the condition is False. It basically takes the condition and keeps the existing values if the condition becomes True.
Syntax
Let’s see how to use the where() function.
- We need to specify the condition as the first parameter.
- If the condition fails, the value passed to the other parameter is replaced.
- We can perform this operation directly on the existing DataFrame by setting the inplace parameter to True (By default = False).
Example
Coalesce values from ‘first_test_score’ and ‘second_test_score’ columns into the ‘Maximum_score’ column using the where() function.
# Create DataFrame - student_scores with first_test_score and second_test_score
student_scores = pandas.DataFrame([[100,90],
[78,98],
[83,83],
[90,91],
[89,84]],columns=['first_test_score', 'second_test_score'])
print(student_scores,"\n")
# Coalesce values from 'first_test_score' and 'second_test_score' columns into 'Maximum_score' column
# using where()
student_scores['Maximum_score']=student_scores['first_test_score'].where
(student_scores['first_test_score']>student_scores['second_test_score'], other=student_scores['second_test_score'])
print(student_scores,"\n")
Output
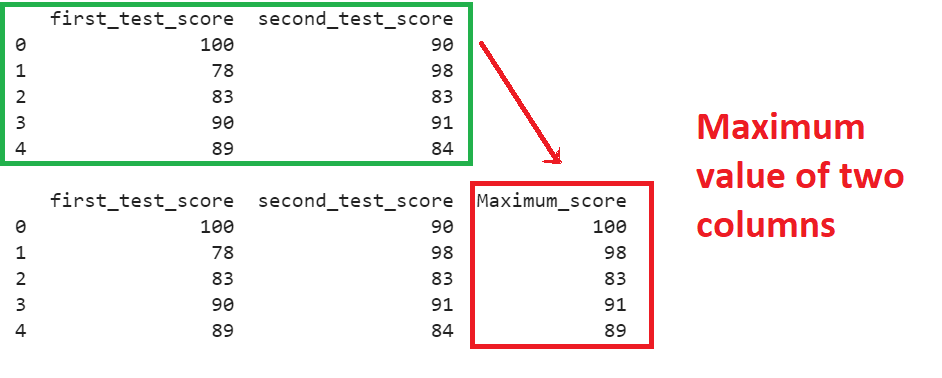
Explanation
- 100 is maximum among 100 and 90. Therefore, 100 is considered the Maximum score.
- 98 is maximum among 78 and 98. Therefore, 98 is considered the Maximum score.
- 83 is maximum among 83 and 83. Therefore, 100 is considered as the Maximum score.
- 91 is maximum among 90 and 91. Therefore, 100 is considered as the Maximum score.
- 89 is maximum among 89 and 84. Therefore, 100 is considered as the Maximum score.
Using pandas.DataFrame.mask
pandas.DataFrame.mask() is used to replace the values in the pandas Series/DataFrame with a specified value when the condition is True. It basically takes the condition and keeps the existing values if the condition becomes False. It is opposite to the where() function.
Syntax
Let’s see how to use the mask() function.
- We need to specify the condition as the first parameter.
- If the condition is satisfied, the value passed to the other parameter is replaced.
- We can perform this operation in the existing DataFrame directly by setting the inplace parameter to True (By default = False).
Example
Coalesce names from the ‘FName’ and ‘LName’ columns into the ‘FullName’ column using the mask() function. We passed the condition to pandas.isnull, which will return True if the value present in the ‘FName’ column is null or not. If a name is not null for this column, it will be used; otherwise, it will take the name from the ‘LName’ column.
# Create DataFrame - emp_names with FirstName and LastName
emp_names = pandas.DataFrame([['Sravan',None],
[None,'Kumar'],
[None,'Sanjay'],
['Bobby','Choudhary'],
['Rani',None]],
columns=['FName', 'LName'])
print(emp_names,"\n")
# Coalesce names from 'FName'and'LName' columns into 'FullName' column
# using mask()
emp_names['mask']=emp_names['FName'].mask(pandas.isnull, emp_names['LName'])
print(emp_names)
Output

Explanation
- First row – FName is not null, the condition is failed. So, it will keep FName – ‘Sravan’ in the mask column.
- Second row – FName is null, the condition is true. So, it will keep LName – ‘Kumar’ in the mask column.
- Third row – FName is null, the condition is true. So, it will keep Lname – ‘Sanjay’ in the mask column.
- Fourth row – Fname is not null, the condition is failed. So, it will keep FName – ‘Bobby’ in the mask column.
- Fifth row – FName is not null, the condition is failed. So, it will keep FName – ‘Rani’ in the mask column.
Conclusion
We saw how to coalesce values from multiple columns into a single column within an existing DataFrame using the following pandas functions: pandas.DataFrame.mask(), pandas.DataFrame.where(), pandas.DataFrame.combine_first() and pandas.DataFrame.bfill(). First, we explained the functionality of these functions with syntax. Then, we demonstrated how to utilize them in our scenarios with examples.