Pandas Module in Python
The Python Pandas module is essentially a free Python package. It has a wide range of applications in computing, data analysis, statistics, and other fields.
The Pandas module makes use of the NumPy module’s core features. NumPy is a low-level data structure. It allows users to manipulate multi-dimensional arrays and apply various mathematical operations to them. Pandas offer a more advanced user interface. It also includes robust time series capability and improved tabular data alignment.
The DataFrame is Pandas’ primary data structure. It is a 2-D data structure that lets you store and manipulate data that is in tabular form.
Pandas have a lot of features for the DataFrame. Data alignment, slicing, data statistics, grouping, concatenating data, merging, and so on are examples.
Why Compare Two Columns in Pandas?
When we wish to compare the values of two columns or see how similar they are, we must compare them. For example, if we have two columns and want to determine whether the column is more or less than the other column or their resemblance, comparing the columns is the appropriate way to do it.
To associate the values in pandas and NumPy, there are a variety of approaches. In this editorial, we will go through numerous strategies and the actions involved in putting them into practice.
Let’s suppose we have two columns: column A contains various projects, and column B has the associated names. In column D, we have several unrelated projects. Based on the projects in column D, we wish to return the associated names from column B. In Excel, how might you compare columns A and D and get the relative values from column B? Let’s look at some examples and understand how you can achieve this.
Example 1:
The np.where() technique will be used in this example. The syntax is numpy.where(condition[,a, b]). This method receives the condition, and if the condition is true, the value we provide (‘a’ in the syntax) will be the value we provide to them.
We import the necessary libraries, pandas, and NumPy, in the code below. We constructed a dictionary and listed the values for each column.
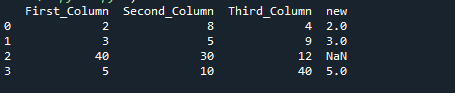
We get the condition to compare the columns using the Where() method in NumPy. If ‘First_Column’ is smaller than ‘Second_Column’ and ‘First_Column’ is smaller than ‘Third_Column,’ the values of ‘First_Column’ are printed. If the condition fails, the value is set to ‘NaN.’ These results are saved in the dataframe’s new column. Finally, the dataframe is presented on the screen.
import numpy
data = {
'First_Column': [2, 3, 40, 5],
'Second_Column': [8, 5, 30, 10],
'Third_Column': [4, 9, 12, 40]
}
d_frame = pandas.DataFrame(data)
d_frame['new'] = numpy.where((d_frame['First_Column'] <= d_frame['Second_Column']) & (
d_frame['First_Column'] <= d_frame['Third_Column']), d_frame['First_Column'], numpy.nan)
print(d_frame)
The output is shown below. Here you can see the First_Column, Second_Column, and Third_Column. The ‘new’ column shows the resultant values after executing the command.
Example 2:
This example demonstrates how to use the equals() method to compare two columns and return the result in the third column. DataFrame.equals(other) is the syntax. This method checks if two columns have the same elements.
We are using the same method in the code below, which involves importing libraries and building a dataframe. We have created a new column (named: Fourth_Column) in this dataframe. This new column equals ‘Second_Column’ in order to show what the function performs in this dataframe.
import numpy
data = {
'First_Column': [2, 3, 40, 5],
'Second_Column': [8, 5, 30, 10],
'Third_Column': [4, 9, 12, 40],
'Fourth_Column': [8, 5, 30, 10],
}
d_frame = pandas.DataFrame(data)
print(d_frame['Fourth_Column'].equals(d_frame['Second_Column']))
When we run the sample code given above, it returns ‘True,’ as you can view in the attached image.
![]()
Example 3:
This method allows us to pass the method and otherwise conditions in our article’s final example and have the same function executed across the pandas dataframe series. Using this strategy, we minimize time and code.
The same code is also used in this example to create a dataframe in Pandas. We create a temporary anonymous function in apply() itself utilizing lambda using the apply() method. It determines if ‘column1’ is smaller than ‘column2’ and ‘column1’ is smaller than ‘column3’. If True, the value ‘column1’ will be returned. It will display NaN if it is False. The New column is used to hold these values. As a result, the columns were compared.
import numpy
data = {
'First_Column': [2, 3, 40, 5],
'Second_Column': [8, 5, 30, 10],
'Third_Column': [4, 9, 12, 40],
}
d_frame = pandas.DataFrame(data)
d_frame['New'] = d_frame.apply(lambda x: x['First_Column'] if x['First_Column'] <=
x['Second_Column'] and x['First_Column']
<= x['Third_Column'] else numpy.nan, axis=1)
print(d_frame)
The attached image shows the comparison of two columns.

Conclusion:
This was a short post about using Pandas and Python to compare one or more columns of two DataFrames. We have gone over the equals() function (which checks whether two Pandas objects have the same elements), the np.where() method (which returns items from x or y depending on the criteria), and the Apply() method (which accepts a function and applies it to all values in a Pandas series). If you’re unfamiliar with the concept, you can use this guide. For your convenience, the post includes all of the details as well as numerous samples.