In Pandas DataFrame or Series, a column is a group of data values having the same data type. Sometimes to convert numerical values to strings or strings to DateTime objects, we need to change the type of DataFrame column. To change the column type in Pandas DataFrame, different methods are employed in Python.
This write-up will present you with a comprehensive tutorial on changing the column type of Pandas DataFrame using numerous examples.
How to Change/Modify the Pandas DataFrame Column Type?
To change/modify column type in Pandas DataFrame, the following methods are used in Python:
- “DataFrame.astype()”
- “DataFrame.apply()” With “pd.to_numeric()” Function
- “convert_dtypes()” Method
- “DataFrame.infer_objects()” Method
Method 1: Change/Modify Column Type in Pandas DataFrame Utilizing the “DataFrame.astype()”
In Python, the “DataFrame.astype()” method of the “pandas” module is used to change the specified data type to another data type. The syntax of “DataFrame.astype()” method is shown below:
For a detailed understanding of the “DataFrame.astype()” method, check this dedicated guide.
Example 1: Change/Modify the Single Column Type of DataFrame Into Another Type
Here is an example code that modifies the data type of the single DataFrame column:
df=pandas.DataFrame({'id_no':[14,12,15,16],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, 18, 12, 13]})
print(df, '\n')
print(df.dtypes, '\n')
df['id_no'] = df['id_no'].astype(float)
print(df, '\n')
print(df.dtypes)
According to the above code:
- The “pandas” module is added, and the DataFrame is constructed utilizing the “pandas.DataFrame()” method.
- The “df.astype()” method takes the data type as an argument and converts the single column of the Pandas DataFrame to the specified column.
Output
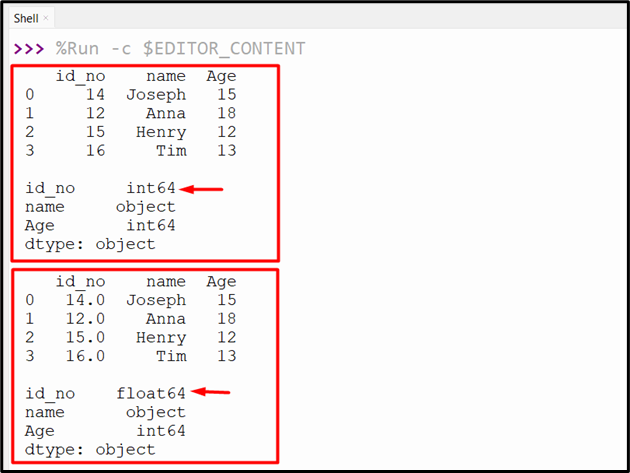
The column “id_no” data type has been changed from “int64” to a “float64”.
Example 2: Change the Multiple Column Type of DataFrame Into Another Type
The following code converts the multiple columns of DataFrame into another type:
df=pandas.DataFrame({'id_no':[14,12,15,16],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, 18, 12, 13]})
print(df, '\n')
print(df.dtypes, '\n')
df[['id_no', 'Age']] = df[['id_no', 'Age']].astype(float)
print(df, '\n')
print(df.dtypes)
In this code, the “df.astype()” method takes the specified datatype and modifies the data type of the numerous columns “id_no” and “Age”.
Output
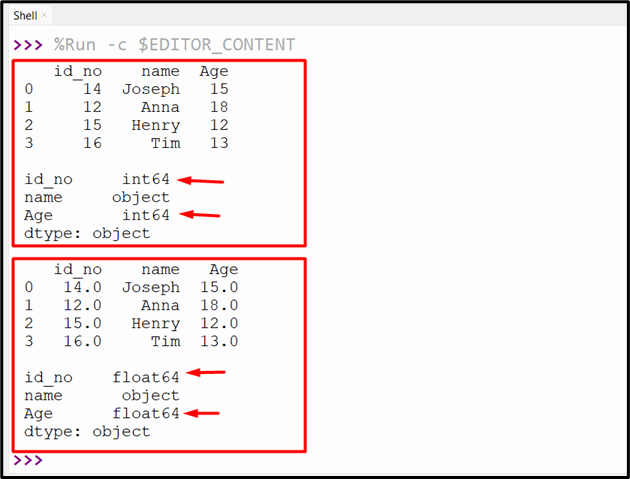
The multiple columns of the DataFrame have been modified successfully.
Example 3: Change All the Column Types of DataFrame Into Specified Type
Let’s overview the following code to change all the DataFrame columns:
df=pandas.DataFrame({'id_no':[14,12,15,16],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, 18, 12, 13]})
print(df, '\n')
print(df.dtypes, '\n')
df = df.astype(str)
print(df, '\n')
print(df.dtypes)
In the above-provided code, the “df.astype()” method can also be utilized to change all the columns of the DataFrame into the specified type (string).
Output
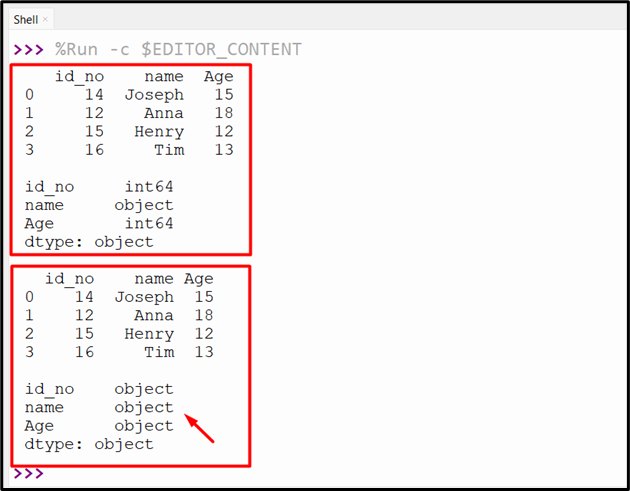
The data types of all the DataFrame columns have been changed to the specified type.
Method 2: Change/Modify Column Type in Pandas DataFrame Utilizing the “DataFrame.apply()” With “pd.to_numeric()” Function
The “pd.to_numeric()” function is used along with the “DataFrame.apply()” method to convert the DataFrame column type into the numeric type. The syntax of the “pd.to_numeric()” function is shown below:
In the above syntax, the “arg” parameters represent the argument that needs to be converted. The remaining parameters are optional and can execute specific operations.
Example 1: Changing Column Type of Pandas DataFrame Into Numeric Type
In the below example, the “df.apply()” takes the “pandas.to_numeric” function and applies this function to the DataFrame column for changing the specified data type to numeric data type:
df=pandas.DataFrame({'id_no':['14','12','15','16'],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, '18', 12, '13']})
print(df, '\n')
print(df.dtypes, '\n')
df[['id_no', 'Age']] = df[['id_no', 'Age']].apply(pandas.to_numeric)
print(df, '\n')
print(df.dtypes)
The above code execution generates the following output:
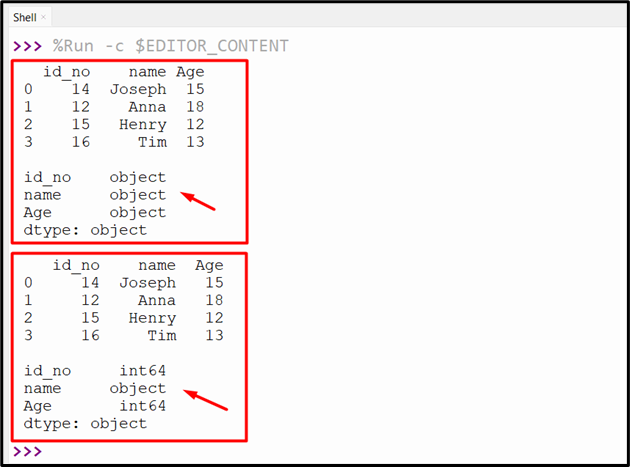
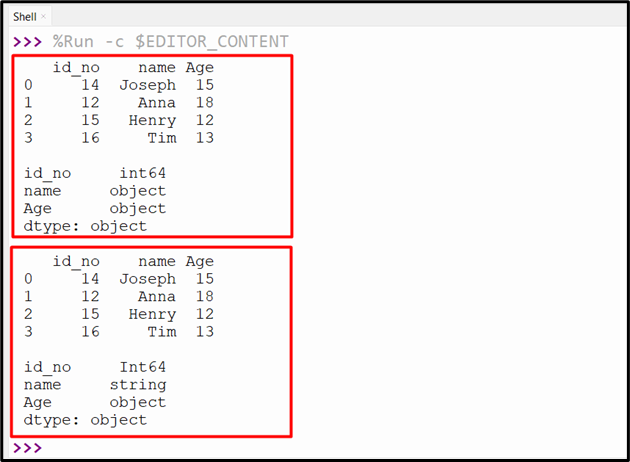
Method 3: Change Column Type in Pandas DataFrame Using the “convert_dtypes()” Method
The “convert_dtypes()” method can also be used to convert/transform the default or assigned data types of the DataFrame columns to the best datatype automatically. The following code is utilized to demonstrate this method:
df=pandas.DataFrame({'id_no':[14,12,15,16],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, '18', 12, '13']})
print(df, '\n')
print(df.dtypes, '\n')
df = df.convert_dtypes()
print(df, '\n')
print(df.dtypes)
After executing the above provided code, the following output will be retrieved on the console:
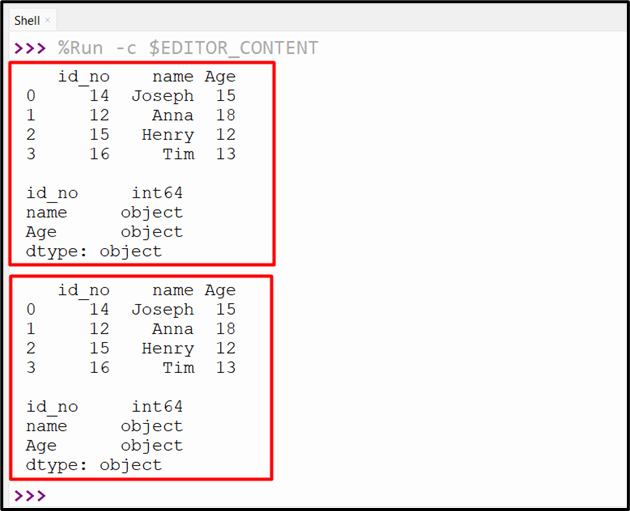
Method 4: Change Column Type in Pandas DataFrame Using the “DataFrame.infer_objects()” Method
The “df.infer_objects()” method is used to retrieve the new DataFrame by changing/modifying the data type of the DataFrame columns to the best possible data type that fits the solutions. Try out the following code to demonstrate this particular method:
df=pandas.DataFrame({'id_no':[14,12,15,16],'name':['Joseph','Anna','Henry','Tim'],'Age':[15, '18', 12, '13']})
print(df, '\n')
print(df.dtypes, '\n')
df = df.infer_objects()
print(df, '\n')
print(df.dtypes)
The above-described code generates the following output:
Conclusion
The “df.astype()”, “pd.to_numeric()”, “convert_dtypes()”, and “df.infer_objects()” methods are used to change the column type of Pandas DataFrame. These methods can change the column type of single, multiple, or entire DataFrame into the specified DataFrame. This guide demonstrated an in-depth tutorial on changing the column type of Pandas DataFrame using several examples.