What is the “pandas.Series.argmax()” in Python?
The “pandas.Series.argmax()” method is used to retrieve the integer position of the largest series value in Python. The syntax of the “pandas.Series.argmax()” method is shown below:
Note: If the max value is found in more than one place, then the first-row position is retrieved.
In the above syntax:
- The “axis” parameter is an unused parameter needed for DataFrame compatibility.
- The “skipna” parameter is used to remove or exclude the NA/null values.
- The “*args” and “**kwargs” parameters specify the additional arguments and keywords.
Return Value
The “pandas.Series.argmax()” method retrieves the row position of the maximum value.
Example: Getting Row Label of the Maximum Value Using “pandas.Series.argmax()” Method
Let’s have a look at the following example that is used to get the maximum value of the row:
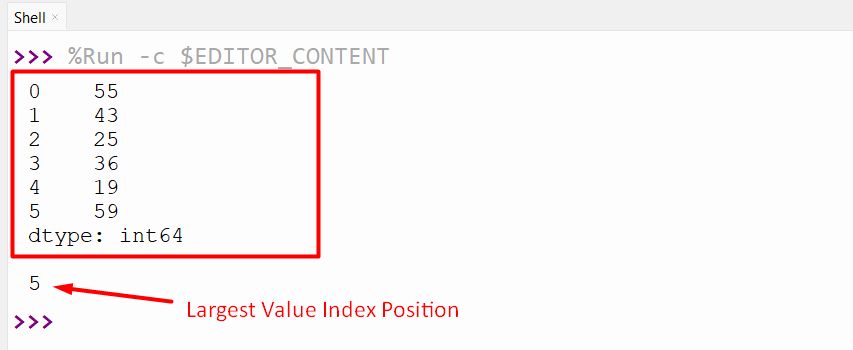
ser_obj = pandas.Series([55, 43, 25, 36, 19, 59])
print(ser_obj, '\n')
print(ser_obj.argmax())
In the above code:
- First of all, imported the “pandas” modules.
- Then, used the “pandas.Series()” method to create the series object and store it in the “ser_obj” variable.
- The “series.argmax()” method retrieves the integer row label of the maximum series value.
As you can see, the row label integer of the largest value of the series object has been retrieved successfully:
What is the “pandas.Index.argmax()” in Python?
The “pandas.Index.argmax()” method is used to retrieve the integer position of the maximum value of the index. Here is the syntax of this particular method:
Note: This method’s parameter and retrieve value are the same as the “pandas.Series.argmax()” method.
Example: Getting the Maximum Index Value Using the “pandas.Index.argmax()” Method
To retrieve the maximum value present in the specified index, use the provided example:
index_obj = pandas.Index([27, 39, 43, 55, 10, 24, 30])
print(index_obj, '\n')
print(index_obj.argmax())
According to the above-specified code:
- We imported the required module and then used the “pandas.Index()” method to create the specified index.
- Next, invoked the “print()” method to show the provided index values.
- Lastly, apply the “index.argmax()” method inside the “print()” method to retrieve the index position of the maximum value of the specified index.
Output
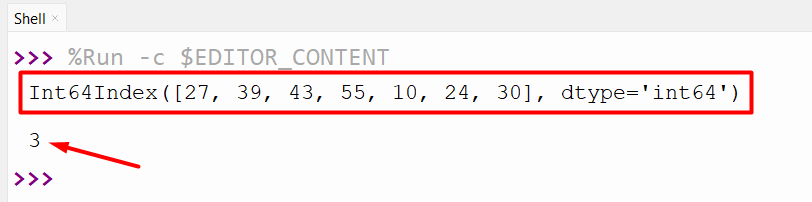
The index of the max value present/exists in the specified index has been retrieved successfully.
Bonus Tip: Finding the Index of the Max Value of the Pandas DataFrame Column
The “df.argmax()” method can also be used to find the maximum value index position of the specified column. Here is an example:
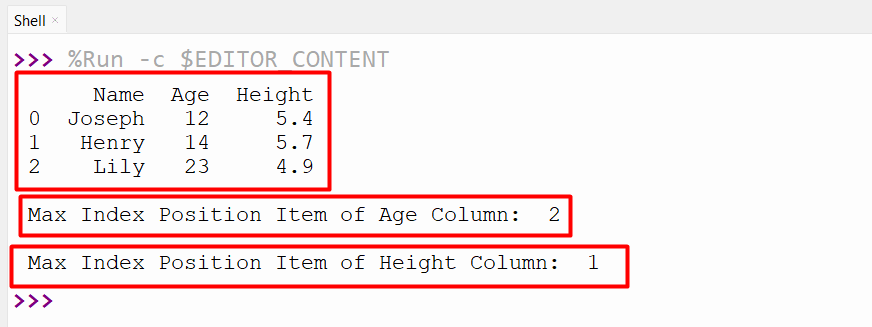
df = pandas.DataFrame({'Name': ['Joseph', 'Henry', 'Lily'], 'Age':[12, 14, 23],'Height': [5.4, 5.7, 4.9]})
print(df,"\n")
print('Max Index Position Item of Age Column: ',df['Age'].argmax())
print('\nMax Index Position Item of Height Column: ',df['Height'].argmax())
Here:
- Used the “pandas.DataFrame()” function to create a DataFrame with three columns “Name”, “Age”, and “Height”, respectively.
- Then, they applied the “df.argmax()” method to retrieve the index position of the max value of the particular DataFrame column.
According to the provided output, the max index position item of the specified column has been retrieved:
Conclusion
The “pandas.Series.argmax()” and “pandas.Index.argmax()” methods are used to find the integers position of the maximum value of the series and index object. We can also utilize this method to retrieve the index position of the maximum value present in the specified columns of DataFrame. In this tutorial, we have illustrated the “argmax()” method of “Pandas” aids with different examples.