Using Pandas.DataFrame.Append
The pandas.DataFrame.append() function is used to append the rows of another DataFrame to the existing DataFrame. If the columns in the existing DataFrame do not exist, the other DataFrame columns are created in the existing DataFrame. Use this function in such a way that the row has to be inserted into the DataFrame by appending the dictionary.
Syntax:
The following is the actual syntax of the pandas.DataFrame.append() function:
- other: This refers to another DataFrame in which the rows of this DataFrame are appended to the existing DataFrame. If you want to append a single row, you need to pass a dictionary of values as the parameter.
- ignore_index (by default = False): This parameter is utilized when you are appending rows to the DataFrame that already has rows. If it is “False”, the existing rows indices are also appended. If it is “True”, the rows are labelled from 0 to n-1. Make sure that this parameter is set to “True” while appending a dictionary to the DataFrame. Otherwise, an error type is raised – “TypeError: Can only append a dict if ignore_index=True”.
- We can check for the duplicate indices using the verify_integrity parameter (by default = False). If the indices are duplicate and the verify_integrity is set to “True”, it returns the “ValueError: Indexes have overlapping values”.
- It is possible to sort the columns if the columns of the existing DataFrame and another DataFrame are not aligned using the sort parameter by setting it to “True” (by default = False).
Example 1: Append a Single Dictionary
Create a Pandas DataFrame with four columns – “Campaign_Name”, “Location”, “StartDate”, and “Budget” – and three rows. Append a dictionary to this DataFrame.
# Create DataFrame - Campaign with 4 columns and 3 rows
Campaign=pandas.DataFrame([['Marketing Camp','India','12/01/2023',8000],
['Sales Camp','Italy','25/01/2022',10000],
['Other Camp','USA','17/04/2023',2000]],
columns=['Campaign_Name','Location','StartDate','Budget'])
print(Campaign,"\n")
# Append Single row
Campaign = Campaign.append({'Campaign_Name' :'Technical Camp','Location' :'USA','StartDate' :'12/05/2023','Budget' :2000},ignore_index = True)
print(Campaign,"\n")
Output:
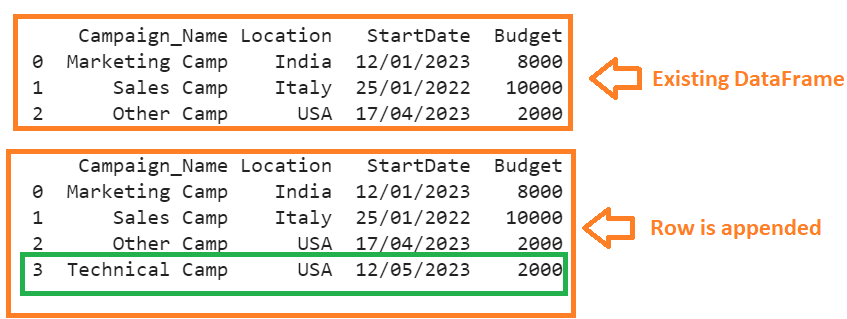
We can see that the dictionary is appended to the “Campaign” DataFrame. The index of this new row is 3 since the index is ignored.
Example 2: Append Multiple Dictionaries
Use the same DataFrame that is created under Example 1 and append three rows at a time using the pandas.DataFrame.append() function. Set the ignore_index parameter to “True”.
# Create DataFrame - Campaign with 4 columns and 3 rows
Campaign=pandas.DataFrame([['Marketing Camp','India','12/01/2023',8000],
['Sales Camp','Italy','25/01/2022',10000],
['Other Camp','USA','17/04/2023',2000]],
columns=['Campaign_Name','Location','StartDate','Budget'])
print(Campaign,"\n")
Campaign = Campaign.append({'Campaign_Name' :'Technical Camp','Location' :'USA','StartDate' :'12/05/2023','Budget' :2000},ignore_index = True)
Campaign = Campaign.append({'Campaign_Name' :'Marketing camp','Location' :'India','StartDate' :'23/06/2023','Budget':9000},ignore_index = True)
Campaign = Campaign.append({'Campaign_Name' :'MSales camp','Location' :'Italy','StartDate' :'24/01/2023','Budget':1200},ignore_index = True)
print(Campaign)
Output:
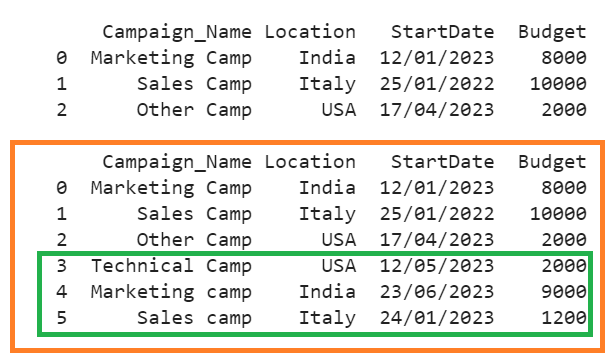
Three rows are appended one after another with 3, 4, and 5 indices to the existing DataFrame.
Using Pandas.Concat
The pandas.concat() function concatenates two or more DataFrames along the rows or columns. So, we need to transform the dictionary to the DataFrame and pass two DataFrames to this function.
Syntax:
Append a dictionary to the existing DataFrame:
- If axis = 0, the concatenation is done along the rows. The concatenation is done along the columns if it is set Applied necessary capitalization since this is a subheading. Added necessary article for brevity.to 1.
- The ignore_index (by default = False): This parameter is utilized when you are appending the rows to the DataFrame that already has rows. If it is “False”, the existing rows indices are also appended. If it is “True”, the rows are labelled from 0 to n-1.
- We can check for the duplicate indices using the verify_integrity parameter (by default = False). If the indices are duplicate and the verify_integrity is set to “True”, it returns the “ValueError: Indexes have overlapping values”.
Example 1: Append a Single Dictionary
Create a Pandas DataFrame with four columns – “Campaign_Name”, “Location”, “StartDate”, and “Budget” – and three rows. Using the pandas.concat() function, append one dictionary (DataFrame) as a row to this DataFrame.
# Create DataFrame - Campaign with 4 columns and 3 rows
Campaign=pandas.DataFrame([['Marketing Camp','India','12/01/2023',8000],
['Sales Camp','Italy','25/01/2022',10000],
['Other Camp','USA','17/04/2023',2000]],
columns=['Campaign_Name','Location','StartDate','Budget'])
print(Campaign,"\n")
dictionary_from_DataFrame=pandas.DataFrame([{'Campaign_Name':'Service Camp','Location':'USA','StartDate':'17/04/2023','Budget':1000}])
# Append Single row
Campaign = pandas.concat([Campaign,dictionary_from_DataFrame],axis=0)
print(Campaign,"\n")
Output:
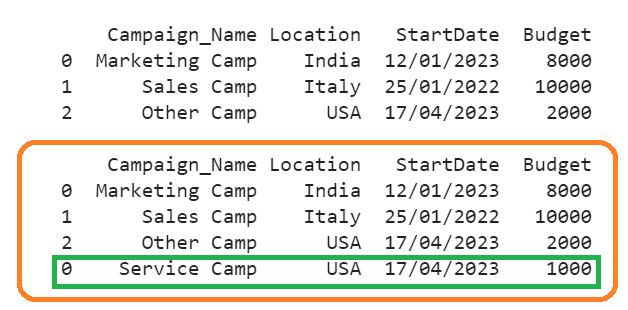
We can see that the dictionary is appended to the “Campaign” DataFrame. The index of this new row is 0 since the index is not ignored.
Example 2: Append Multiple Dictionaries
Use the previous DataFrame and append three dictionaries (DataFrame) by ignoring the index.
# Create DataFrame - Campaign with 4 columns and 3 rows
Campaign=pandas.DataFrame([['Marketing Camp','India','12/01/2023',8000],
['Sales Camp','Italy','25/01/2022',10000],
['Other Camp','USA','17/04/2023',2000]],
columns=['Campaign_Name','Location','StartDate','Budget'])
print(Campaign,"\n")
dictionary_from_DataFrame=pandas.DataFrame([{'Campaign_Name':'Tech Camp','Location':'USA','StartDate':'17/05/2023','Budget':1000},
{'Campaign_Name':'Social services','Location':'Japan','StartDate':'17/04/2023','Budget':200},
{'Campaign_Name':'Sales Camp','Location':'USA','StartDate':'18/04/2023','Budget':500}])
# Append multiple rows
Campaign = pandas.concat([Campaign,dictionary_from_DataFrame],axis=0,ignore_index=True)
print(Campaign,"\n")
Output:
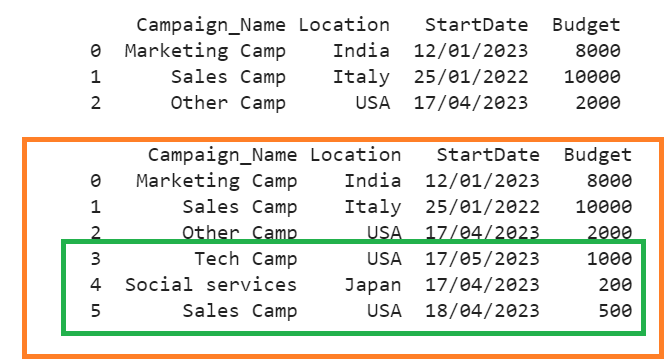
We can see that three dictionaries are appended to the “Campaign” DataFrame. The indices of these dictionaries are 3, 4, and 5 since the ignore_index parameter is set to “False”.
Conclusion
The single/multiple dictionaries are appended to the DataFrame using the pandas.DataFrame.append() and pandas.concat() functions. The indices of the new rows can be unique by setting the ignore_index parameter to “True” in the pandas.concat() function. While using the pandas.DataFrame.append() function, set the ignore_index parameter to “True”. Otherwise, TypeError is raised.