DataFrames in Pandas are two-dimensional data structures that can be used to store and analyze data. DataFrames can be distinguished by their indexes, as each row in the DataFrame has a unique index identifier. This indexing can be used to access specific rows or subsets of data. To add an index in Python, various methods are used in Python.
This Python blog post presents a detailed guide on how to add an index to pandas DataFrame.
How to Add/Insert an Index to Pandas DataFrame?
To add an index to Pandas DataFrame, the following methods are used in Python:
Method 1: Add an Index to Pandas DataFrame Using the “set_index()” Method
The “set_index()” method is used to add the index to Pandas DataFrame. This method takes multiple columns as input and sets them as the index for the DataFrame.
Example 1: Adding a Single Column as the Index of DataFrame
The following code will add the specific column as the index for the DataFrame:
data1 = pandas.DataFrame({"students": ["Mary", "Queen", "Anna"], "marks": [52, 63, 84], "Id_no": [5, 6, 2]})
print('Before Adding Index:\n', data1)
data1 = data1.set_index("Id_no")
print('\nAfter Adding Index:\n',data1)
In the above code, the “set_index()” method is used to add the “Id_no” column as an index to the specified DataFrame.
Output
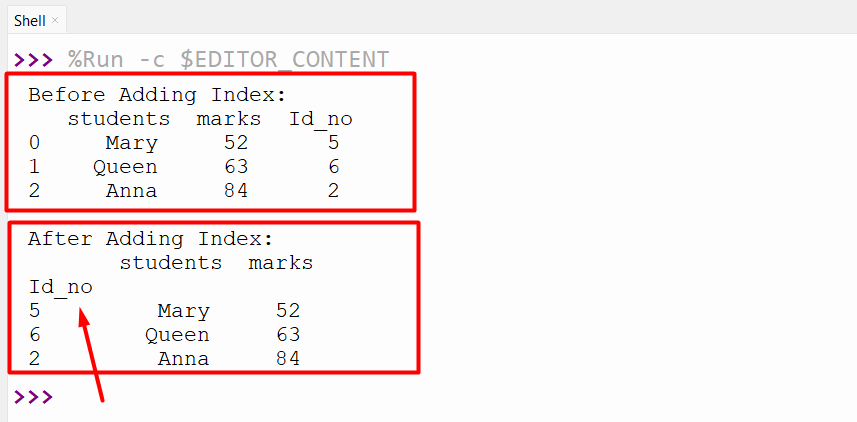
The column “Id_no” has been added as a Pandas DataFrame index appropriately.
Example 2: Adding Multiple Columns as the Index of DataFrame
The below code is used to add multiple columns as the index of the DataFrame:
data1 = pandas.DataFrame({"students": ["Mary", "Queen", "Anna"], "marks": [52, 63, 84], "id_no": [5, 6, 2]})
print('Before Adding Index:\n', data1)
data1 = data1.set_index(["marks", "id_no"])
print('\nAfter Adding Index:\n',data1)
In this code block, the “set_index()” method takes the “marks” and “id_no” columns from the DataFrame as its arguments and adds these two columns as the index for the DataFrame.
Output
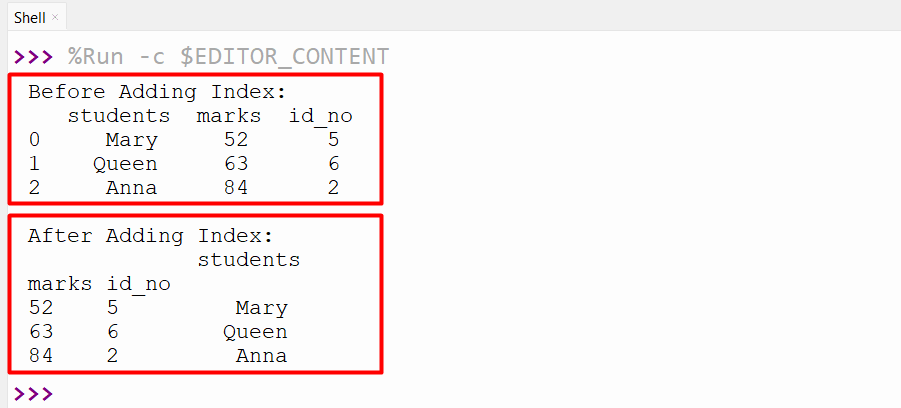
The above snippet verified that the “marks” and “id_no” columns had been added as the index for the DataFrame.
Method 2: Add an Index to Pandas DataFrame Using the “df.index” Attribute
The “index” attribute can be used to set the index for a DataFrame. This attribute’s value can be a list of values, a NumPy array, or a Pandas series.
Example
The below code sets/adds the DataFrame index:
data1 = pandas.DataFrame({"students": ["Mary", "Queen", "Anna"], "marks": [52, 63, 84], "id_no": [5, 6, 2]})
print('Before Adding Index:\n', data1)
data1.index = [10, 11, 12]
print('\nAfter Adding Index:\n',data1)
In the above example, the “data1.index” attribute adds the custom index values to the defined Pandas DataFrame.
Output
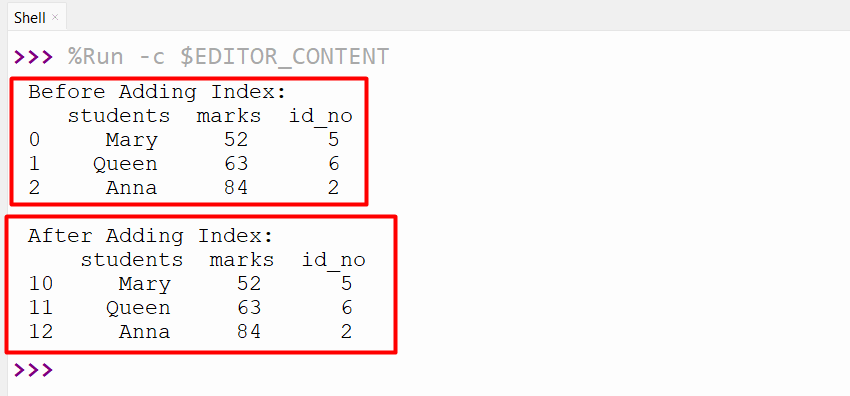
The custom column has been added (having the stated index values) to Pandas DataFrame accordingly.
Conclusion
To add an index to the Pandas DataFrame, the “dataframe.set_index()” method or the “dataframe.index” attribute is used in Python. This Python post presented a comprehensive guide on adding/inserting an index to Pandas DataFrame using various examples.