It is necessary while doing a task that calls for processing several actions or data. Therefore, switching out and enhancing some ineffective code blocks and functionalities can have amazing results like the following:
- Boost the application’s performance
- Create readable and organized code
- Make the error monitoring and debugging simpler
- Conserve considerable computational power and so forth
Profile Your Code
Before we start optimizing, it’s essential to identify the parts of the project code that are slowing it down. The techniques for profiling in Python include the cProfile and profile packages. Utilize such tools to gauge how quickly certain functions and lines of code execute. The cProfile module produces a report that details how long each script function takes to run. This report can help us find any functions that are running slowly so that we can improve them.
Code Snippet:
def calculateSum(inputNumber):
sum_of_input_numbers = 0
while inputNumber > 0:
sum_of_input_numbers += inputNumber % 10
inputNumber //= 10
print("Sum of All Digits in Input Number is: 'sum_of_input_numbers'")
return sum_of_input_numbers
def main_func():
cP.run('calculateSum(9876543789)')
if __name__ == '__main__':
main_func()
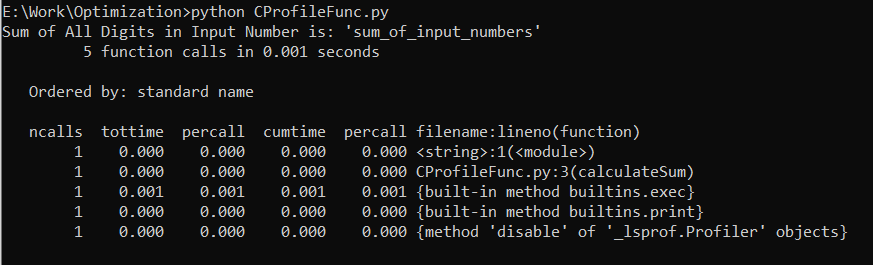
The program makes a total of five function calls as seen in the first line of the output. The details of each function call are shown in the following few lines including the number of times the function was invoked, the overall duration of time in the function, the duration of time per call, and the overall amount of time in the function (including all of the functions it is called).
Additionally, the program prints a report on the prompt screen which shows that the program completes the execution time of all of its tasks within 0.000 seconds. This shows how fast the program is.
Choose the Right Data Structure
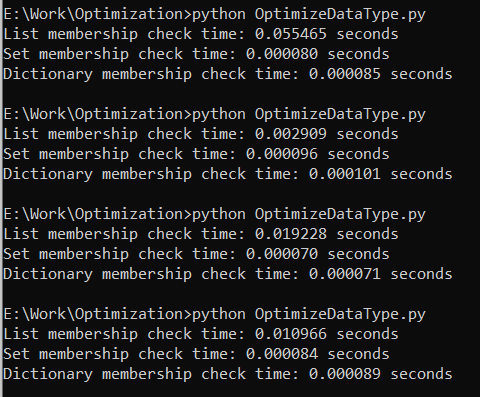
Performance characteristics are dependent on the data structure. In particular, dictionaries are quicker for lookups than lists regarding the general-purpose storage. Select the data structure that is most suitable for the operations that we will conduct on your data if you know those. The following example investigates the effectiveness of different data structures for an identical process to determine whether an element in the data structure is present.
We evaluate the time it takes to check if an element is present in each data structure—a list, a set, and a dictionary—and compare them.
OptimizeDataType.py:
import random as rndobj
# Generate a list of integers
random_data_list = [rndobj.randint(1, 10000) for _ in range(10000)]
# Create a set from the same data
random_data_set = set(random_data_list)
# Create a dictionary with the same data as keys
obj_DataDictionary = {num: None for num in random_data_list}
# Element to search for (exists in the data)
random_number_to_find = rndobj.choice(random_data_list)
# Measure the time to check membership in a list
list_time = tt.timeit(lambda: random_number_to_find in random_data_list, number=1000)
# Measure the time to check membership in a set
set_time = tt.timeit(lambda: random_number_to_find in random_data_set, number=1000)
# Measure the time to check membership in a dictionary
dict_time = tt.timeit(lambda: random_number_to_find in obj_DataDictionary, number=1000)
print(f"List membership check time: {list_time:.6f} seconds")
print(f"Set membership check time: {set_time:.6f} seconds")
print(f"Dictionary membership check time: {dict_time:.6f} seconds")
This code compares the performance of lists, sets, and dictionaries when doing membership checks. In general, sets and dictionaries are substantially faster than lists for membership tests because they use the hash-based lookups, so they have an average time complexity of O(1). Lists, on the other hand, must do linear searches which results in membership tests with O(n) time complexity.
Use the Built-In Functions Instead of Loops
Numerous built-in functions or methods in Python can be used to carry out typical tasks like filtering, sorting, and mapping. Using these routines rather than creating one’s loops helps speed up the code because they are frequently performance-optimized.
Let’s build some sample code to compare the performance of creating custom loops by utilizing the built-in functions for typical jobs (such as map(), filter(), and sorted()). We’ll evaluate how well the various mapping, filtration, and sorting methods perform.
BuiltInFunctions.py:
# Sample list of numbers_list
numbers_list = list(range(1, 10000))
# Function to square numbers_list using a loop
def square_using_loop(numbers_list):
square_result = []
for num in numbers_list:
square_result.append(num ** 2)
return square_result
# Function to filter even numbers_list using a loop
def filter_even_using_loop(numbers_list):
filter_result = []
for num in numbers_list:
if num % 2 == 0:
filter_result.append(num)
return filter_result
# Function to sort numbers_list using a loop
def sort_using_loop(numbers_list):
return sorted(numbers_list)
# Measure the time to square numbers_list using map()
map_time = tt.timeit(lambda: list(map(lambda x: x ** 2, numbers_list)), number=1000)
# Measure the time to filter even numbers_list using filter()
filter_time = tt.timeit(lambda: list(filter(lambda x: x % 2 == 0, numbers_list)), number=1000)
# Measure the time to sort numbers_list using sorted()
sorted_time = tt.timeit(lambda: sorted(numbers_list), number=1000)
# Measure the time to square numbers_list using a loop
loop_map_time = tt.timeit(lambda: square_using_loop(numbers_list), number=1000)
# Measure the time to filter even numbers_list using a loop
loop_filter_time = tt.timeit(lambda: filter_even_using_loop(numbers_list), number=1000)
# Measure the time to sort numbers_list using a loop
loop_sorted_time = tt.timeit(lambda: sort_using_loop(numbers_list), number=1000)
print("Number List contains 10000 elements")
print(f"Map() Time: {map_time:.6f} seconds")
print(f"Filter() Time: {filter_time:.6f} seconds")
print(f"Sorted() Time: {sorted_time:.6f} seconds")
print(f"Loop (Map) Time: {loop_map_time:.6f} seconds")
print(f"Loop (Filter) Time: {loop_filter_time:.6f} seconds")
print(f"Loop (Sorted) Time: {loop_sorted_time:.6f} seconds")
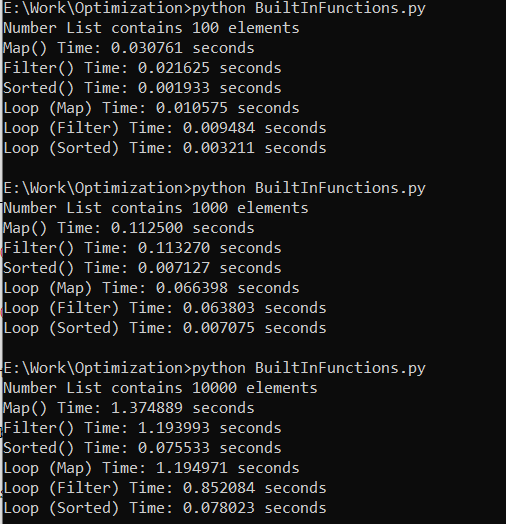
We’ll likely observe that the built-in functions (map(), filter(), and sorted()) are faster than the custom loops for these common tasks. The built-in functions in Python offer a more concise and understandable approach to carry out these tasks and are highly optimized for performance.
Optimize the Loops
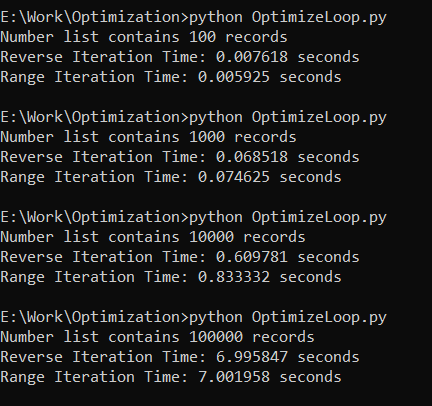
If writing the loops is necessary, there are a few techniques that we can do to speed them up. Generally, the range() loop is quicker than iterating backward. This is because range() generates an iterator without inverting the list which can be a costly operation for lengthy lists. Additionally, since range() doesn’t build a new list in the memory, it uses less memory.
OptimizeLoop.py:
# Sample list of numbers_list
numbers_list = list(range(1, 100000))
# Function to iterate over the list in reverse order
def loop_reverse_iteration():
result_reverse = []
for j in range(len(numbers_list) - 1, -1, -1):
result_reverse.append(numbers_list[j])
return result_reverse
# Function to iterate over the list using range()
def loop_range_iteration():
result_range = []
for k in range(len(numbers_list)):
result_range.append(numbers_list[k])
return result_range
# Measure the time it takes to perform reverse iteration
reverse_time = tt.timeit(loop_reverse_iteration, number=1000)
# Measure the time it takes to perform range iteration
range_time = tt.timeit(loop_range_iteration, number=1000)
print("Number list contains 100000 records")
print(f"Reverse Iteration Time: {reverse_time:.6f} seconds")
print(f"Range Iteration Time: {range_time:.6f} seconds")
Avoid Unnecessary Function Calls
There is some overhead every time a function is called. The code runs more quickly if unnecessary function calls are avoided. For instance, instead of repeatedly executing a function that calculates a value, try storing the result of the calculation in a variable and using it.
Tools for Profiling
To learn more about the performance of your code, in addition to built-in profiling, we can utilize the external profiling packages like cProfile, Pyflame, or SnakeViz.
Cache Results
If our code needs to perform expensive calculations, we might consider caching the outcomes to save time.
Code Refactoring
Refactoring the code to make it easier to read and maintain is sometimes a necessary part of optimizing it. A speedier program may also be cleaner.
Use the Just-in-Time Compilation (JIT)
Libraries like PyPy or Numba can provide a JIT compilation which can significantly speed up certain types of Python code.
Upgrade Python
Ensure that you are using the latest version of Python since newer versions often include performance improvements.
Parallelism and Concurrency
For processes that can be parallelized, investigate the parallel and synchronization techniques like multiprocessing, threading, or asyncio.
Remember that benchmarking and profiling should be the main drivers of optimization. Concentrate on improving the areas of our code that have the most significant effects on performance, and constantly test your improvements to make sure that they have the desired effects without introducing more defects.
Conclusion
In conclusion, Python code optimization is crucial for improved performance and resource effectiveness. Developers can greatly increase the speed of execution and responsiveness of their Python applications using various techniques such as selecting the appropriate data structures, leveraging the built-in functions, reducing the extra loops, and effectively managing the memory. Continuous benchmarking and profiling ought to direct the optimization efforts, ensuring that the code advancements match the real-world performance requirements. To guarantee a long-term project success and lower the chance of introducing new problems, optimizing the code should constantly be balanced with the objectives of code readability and maintainability.