
These OCR software are especially useful for converting and preserving old documents as they can be used to identify text and create digital copies. Sometimes the identified text may not be 100% accurate but OCR software removes the need for manual edits to a great extent by extracting as much text as possible. Manual edits can be made later to improve accuracy further and create one-to-one replicas. Most OCR software can extract text into separate files, though some also support superimposing a hidden text layer on original files. Superimposed text allows you to read content in original print and format but also allows you to select and copy text. This technique is specially used to digitize old documents into PDF format.
Tesseract OCR
Tesseract OCR is a free and open source OCR software available for Linux. Sponsored by Google, and maintained by many volunteers, it is probably the most comprehensive OCR suite available out there that can even beat some paid, proprietary solutions. It provides command line tools as well as an API that you can integrate in your own programs. It can detect text in many languages with good accuracy. It comes with a set of pre-trained data that can be used to identify and extract text. You can also use your own trained data if you need a custom solution or you can get more models from third parties. Tesseract OCR comes with multiple detection engines and you can use them according to your needs depending on the installation method.
To install Tesseract OCR in Ubuntu, use the command specified below:
You can install it in other Linux distributions from default repositories through the package manager. A universal AppImage file and more installation instructions are available here.
Tesseract OCR comes with support for detecting English language content by default. If you want to enable additional languages, you may have to download more language packs. The link given above has instructions for installing additional language packs. In Ubuntu, you can directly find language packages by running the command below:
The command above will output package names for different language packs. Just install them by running a command in the following format:
You can get a list of all installed language packs by running the command below:
Once the main Tesseract OCR package and additional language packages have been installed, you can start detecting text from images and PDF files. To extract text, use commands in following formats:
$ tesseract image.png output -l eng+spa
$ tesseract image.png output -l eng pdf
The first command will extract text from “image.png” file in “eng” language and store it in a file called “output”. The second command will parse the image using multiple language packs. The third command can be used to create a PDF file with a text layer superimposed on the image file.
For more information on command line usage of Tesseract OCR, use the following two commands:
$ man tesseract
gImageReader
gImageReader is a graphical client for the Tesseract OCR engine mentioned above. You can use it to run most of the command line options and actions supported by Tesseract OCR, including extracting text from multiple files, spell-checking the extracted text and performing post-processing on the identified text.
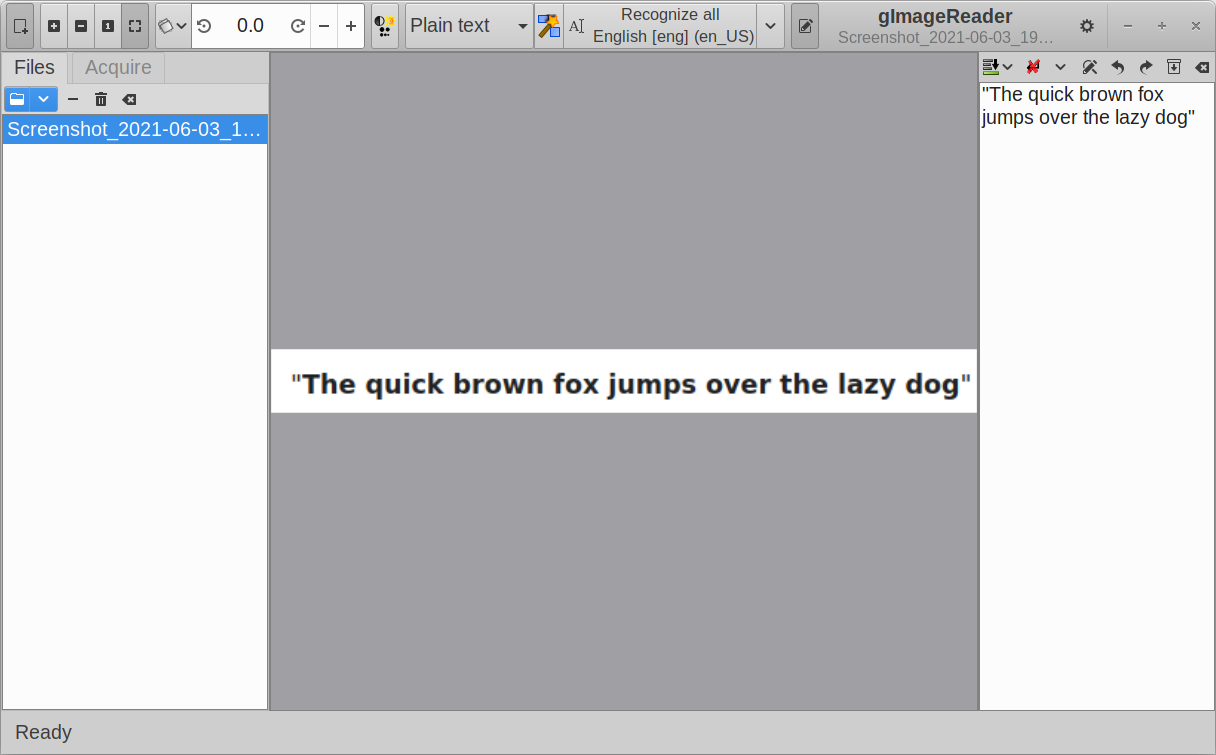
To install gImageReader in Ubuntu, use the command specified below:
You can install it in other Linux distributions from default repositories through the package manager. More distribution specific packages are available here.
Paperwork
Paperwork is a free and open source document manager. You can use it to efficiently manage your library of documents, especially if you have a large collection. It also comes with a built-in OCR mode that uses “Pyocr”, a Python module based on Tesseract and Cuneiform OCR engines. Other main features of Paperwork include ability to edit scanned documents, a search bar to search document library, ability to sort documents, scanner support, and so on.
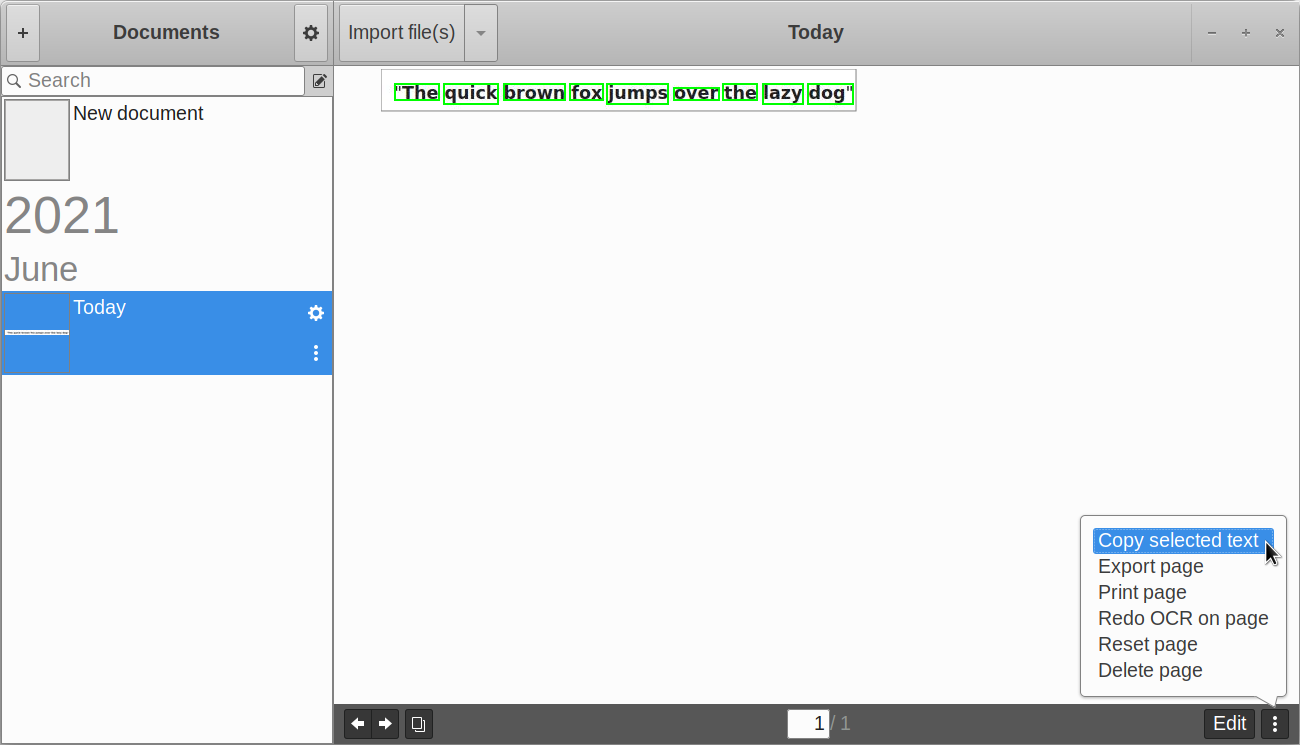
To install Paperwork in Ubuntu, use the command specified below:
You can install it in other Linux distributions from default repositories through the package manager. A universal flatpak package is also available here.
OCRFeeder
OCRFeeder is a free and open source graphical OCR software maintained by the GNOME team. It supports recognizing text in numerous languages and can export content in numerous file formats. It supports many OCR engines, including Tesseract OCR, GOCR, Ocrad and Cuneiform. It also allows you to do some post-processing to improve formatting and layout of the extracted text content.
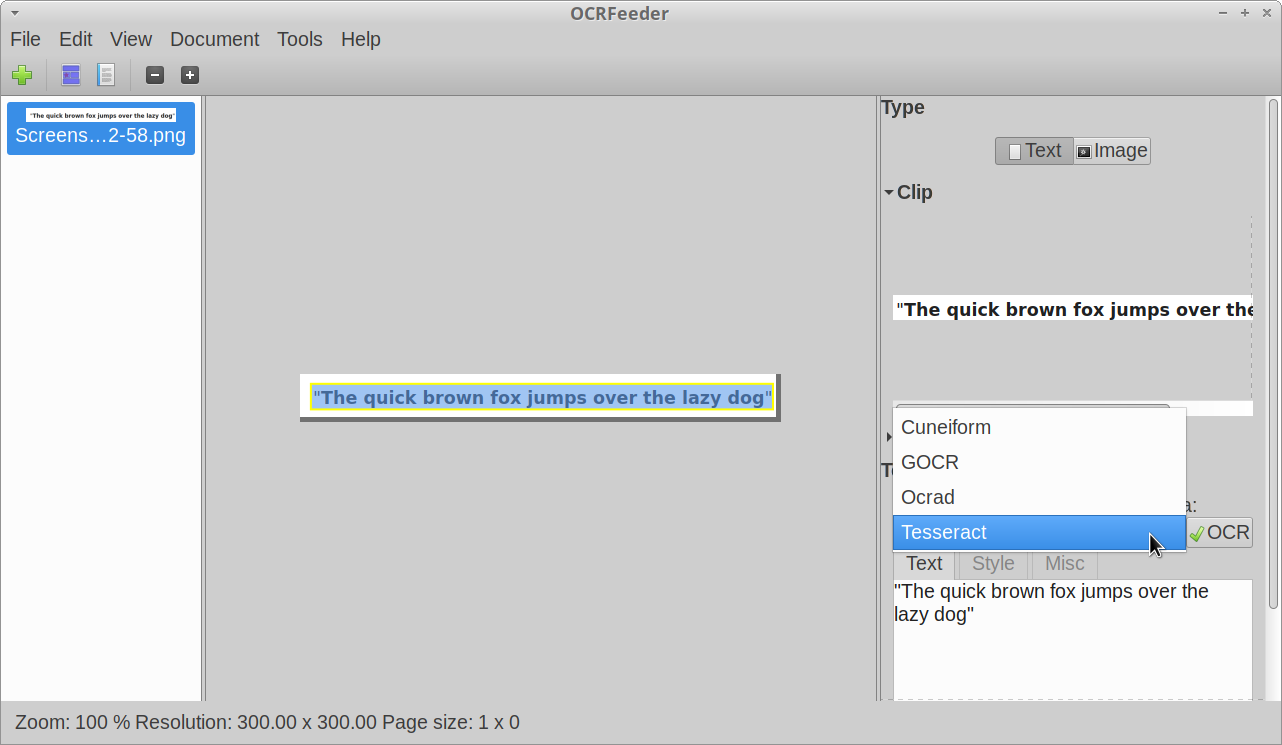
To install OCRFeeder in Ubuntu, use the command specified below:
You can install it in other Linux distributions from default repositories through the package manager. A universal flatpak package is also available here.
Note that in my testing, OCRFeeder installed from Ubuntu repositories came with only one OCR engine. However, the flatpak build came with all four supported OCR engines though it downloaded around 2GB data. The package included in the Ubuntu repository was much smaller in size.
gscan2pdf
gscan2pdf is a free and open source graphical utility that can identify and extract text from a variety of file formats. It can directly work with scanners to scan papers and then export OCR detected text content into PDF files. It also supports multiple OCR engines including Tesseract OCR, GOCR, Ocropus and Cuneiform, as long as packages for these engines are installed on your system. Other than direct scanning of papers, you can also import image files and extract text from them.
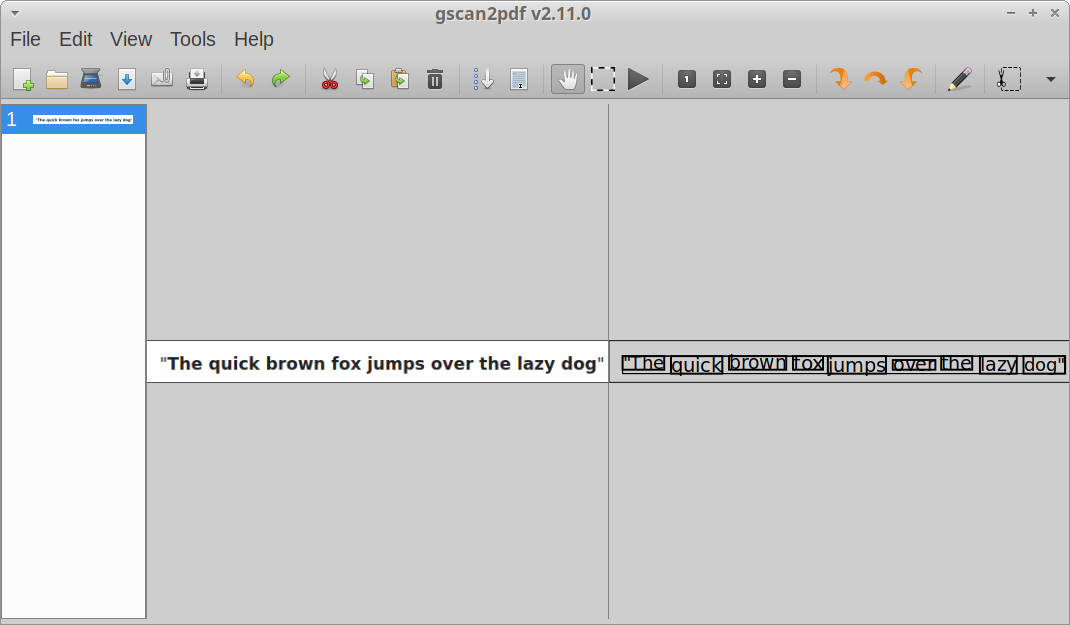
To install gscan2pdf in Ubuntu, use the command specified below:
You can install it in other Linux distributions from default repositories through the package manager. Source code and executable binaries are also available here.
Conclusion
These are some of the most useful command line and graphical OCR engines and software available for Linux. Tesseract OCR is the most actively developed and most comprehensive tool for detecting text and it should be enough for most of your needs. Though you can also try other apps mentioned in this article if you are not satisfied with the results of Tesseract OCR.