“MapReduce” is one of the third components of Hadoop. This framework is efficient for the processing of large data in parallel with the other tasks. The basic purpose of “MapReduce” is to Map each job collectively in groups, and then this will reduce it to equal tasks to reduce the cluster formation of the processes. The “MapReduce” task is split into two phases.
- Map phase
- Reduce phase
Map Reduce Concept and architecture
The input data is distributed into small chunks for the processing of data through different workers. Each small chunk is mapped to an intermediate situation/state. That intermediate data is then collected together, and then the partitioning process occurs that is based on a key-value to keep all the related material with each other. Then this partitioning of data leads to the resultant reduced set. Let us consider the below diagram.
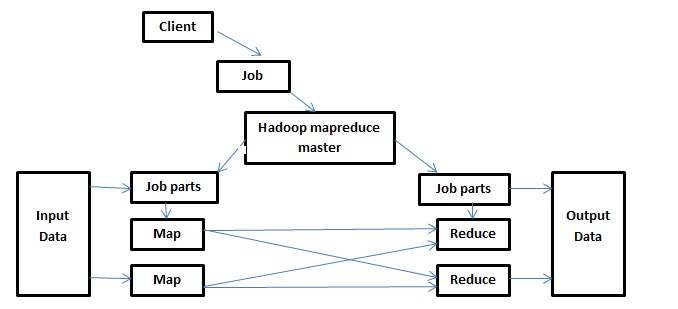
Parts of architecture
- Client: It is the one who is responsible for taking the job to “Mapreduce” for the processing function. There can be a possibility of multiple clients that send jobs continuously for the processing to the “Mapreduce” Manager.
- Job: it is the actual task/work that the client wants to do that contains many smaller tasks that the client wants for the execution.
- Hadoop MapReduce Master: The function of this master is to divide the job into smaller job parts.
- Job parts: The sub-jobs obtained from the main job function. The resultant value of all the job parts collectively forms a final output.
- Input Data: The data that is introduced to the map-reduce for the processing of data.
- Output data: Contains the limited words in a result.
The job parts that are obtained from the job are then transferred to the Map and Reduce tasks. These two tasks have programs and algorithms that depend on the requirement of the user. The input data is used and entered into the Map task. Map task will then generate the intermediate key-value pair that will act as an input for the Reduce phase. In the Reduce phase, after performing the reduction process, store the final results in the HDFS. Now moving towards the example of Map-reduce, the code in the example is explained with both the phases separately and their output as well.
Code of Python Mapreduce
Hadoop Streaming API is used to pass data between the Map and Reduce code through STDIN and STOUT. To read input data and print the output, “sys.stdin” is used. Other procedures are handled through Hadoop streaming itself.
Map Phase
The main use of the Map phase is to map the input data in the form of keys pairs. The key-value we used can act as the id is some address, and the value contains the actual value that is kept. This map phase will generate an intermediate value with the key as an output. To reduce the function, the output of the map is used as input. Let us consider the code for the map function. This function is also known as Mapper.py.
You should create a file and save the code in that file. i.e /home/aqsa/mapper.py. The map script is not able to calculate an intermediate value of total words that occurs several times. Instead, it will give the parts of data even the words are repeating multiples times in the input data. We will let the function reduce the number of words by calculating the sum of their occurrence. One thing that should be kept in mind, the file has execution permission (chmod+x/home/aqsa/mapper.py). Moving towards the code, the first step will be importing of sys module. The input will be taken by using a FOR loop through stdin.
For line in sys.stdin:
This function will then read line by line, strip all the lines, and remove the whitespaces between them through the strip function. Similarly, each line is split into words by using a split function. Both functions are declared inside the FOR loop body.
# words = line.split()
"""mapper.py"""
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# tab-delimited; the trivial word count is 1
print('%s\t%s' % (word, 1))
After all the functions are performed, each word will be printed one by one.
The intermediate values undergo two processes before entering the reduction phase. These two stages are the shuffling and the sorting phase.
Shuffling Phase:
The purpose of this function is to associate all the values of a similar key. For instance, consider a word (yes, 1) that has occurred 4 times in the output file. So after this phase, the output will be shown as (yes, [1,1,1,1]).
Sorting Phase:
When the shuffling process is completed, the output values are sent to the sorting phase. In this phase, all the keys and values are sorted automatically. In Hadoop, the sorting process does not require any sorting algorithm, as it is an automatic process. It is because of the built-in interface named ‘writablecomparableinterface’.
Reduce Phase
The intermediate values are then transferred to the reduce function after they are sorted. The reduce function group the data depending on the key-value pair according to the reducer algorithm used by the programmer.
The code that we will implement is saved in a file of the path “/home/aqsa/reducer.py”. This file will read the results from the “mapper.py” file from the STDIN. For that purpose, the format of the “mapper.py” file and the input coming from the mapper.py should be the same. After that, this function takes the sum of the occurrence of each word, and the final output is displayed through STDOUT.
"""reducer.py"""
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
if current_word == word:
print('%s\t%s' % (current_word, current_count))
Sys module is imported first. Then a variable for the counting process is declared 0 as the initial value. We have taken the input values using for loop, and the lines are separated just like the map function. To split the words, we use both the words and count variables.
In the try body, the count variable is assigned the value. The if-statement is used to check if the coming word is the same as the stored; the count variable is incremented.
Resultant value
To check the results, go to the terminal of Linux. Here we will use a string that combines single and repetitive words to get versatile results.

Conclusion
‘Mapreduce Python example’ consists of the basic functionality and architecture of map-reduce collectively and separately. The intermediate value formation plays an important role in this purpose. To get the limited value, whenever you want to manage big data, you need to use a “MapReduce” function in the program. Reading this article will be a source of complete information regarding the “MapReduce” function.