The ability to generate the nested runs in MLflow is helpful for tracking the complex workflows. A run that is connected to another run, known as the parent run, is called a nested run. The parent run is able to monitor the child run’s metrics, parameters, and artifacts. The nested runs act as threads and are very helpful in managing the complex machine learning workflows that involve a parallel or sequential execution of multiple processes. Each thread or process may consist of nested runs or stages.
Advantages of Nested Runs in MLflow
- Improved visibility and traceability: The nested runs can be used to clarify the relationships between various workflow components. As a result, it may be less complicated to pinpoint the source of problems and recreate successful solutions.
- Efficient storage and retrieval: The amount of data that is saved in MLflow can be decreased with the support of nested runs. This is so that the parent run may save the metrics, experiments, and artifacts of the child runs.
- Simplified reporting: The reporting of ML experiments can be made simpler by nested runs. This is due to the fact that it can provide reports that display the metrics and instances for each run in a workflow.
Things to Keep in Mind When Working with Nested Runs in MLflow
- A parent run must be launched before any child run may begin: As a result, we are unable to launch a child’s run directly. Start the child’s run under the parent run after initiating the parent run first.
- The child in the run receives the parent run ID: This is necessary in order for a child’s run to understand which parent run it belongs to.
- Nested runs can be nested to any level: This indicates that it is possible to build a hierarchy of runs to monitor even the most complex workflows.
Syntax to Create Nested Runs
To create a nested run, set the nested=True argument when using the mlflow.start_run() function. For example:
with mlflow.start_run(nested=True) as nested_child_run:
# Do some work
Nested_child_run_id = nested_child_run.info.run_id
Example: University Management System with Nested Runs
Let’s consider a simplified scenario of a University Management System with three main functionalities: student registration, course enrollment, and student transcript generation. Each functionality is represented as a separate method and uses nested runs in MLflow to manage the different stages within each method.
Setup the MLflow Tracking
The tracking server URI is set to “http://127.0.0.1:5000” in the first line of the University System’s main function. The MLflow tracking server at this URL is used to keep track of the runs.
Create the Parent Run
An entirely new MLflow run called “University System” is launched in the third line. The run name serves as the run’s identification and is a human-readable string. It is used to track and distinguish the runs in the MLflow tracking user interface. It is used to track and distinguish the runs in the MLflow tracking user interface.
The code starts a fresh run of MLflow named “University System”. The run keeps track of a student’s registration, course enrollment, and transcript generation processes. The fourth line calls the std_registration function to register the student. The std_registration function accepts the student’s name, age, and major as parameters and returns the student ID.
To enroll the student in the courses, the std_enrollment function is invoked in the fifth line. The list of courses and the student ID are inputted into the std_enrollment function.
To print the student transcript, the print_transcript function is called on the sixth line. The transcript is printed to the console using this function which takes the student ID as input.
Here is the snippet of the code:
# Tracking Server URI in this case localhost
mlflow.set_tracking_uri("http://127.0.0.1:5000")
with mlflow.start_run(run_name="University System") as parent_run:
# Step 1: Student Registration
student_name = "James Web"
student_age = 44
student_major = "Information Technology"
std_id=std_registration(student_name, student_age, student_major)
# Step 2: Course Enrollment
courses_list = ["Intro to IT", "Data Structures", "Machine Learning", "Web Programming"]
std_enrollment(std_id, courses_list)
# Step 3: Student Transcript Generation
print_transcript(std_id)
Create a Nested Run: Student Registration
A function named std_registration is defined in the first line. This function returns the student ID upon receiving the student’s name, age, and major as arguments. A new nested run with the “Student Registration” name starts in the second line. A run that is launched inside of another run is referred to as a nested run. Therefore, it is the parent run’s earlier-created child run.
The third line mimics the registration process for students. This can entail entering the student’s information into a database or giving them a unique ID. The record_student_registration function is called in the fourth line in order to enter the student information into the database.
The registration information is logged as parameters in MLflow on the fifth line. The “Store Student Registration to Database table” is the name of the nested run that begins on the sixth line. This nested run keeps track of the procedures that are used to enter the student registration information into the database. It returns the student ID in the final line.
Code:
# Student Name, Student Age, Student Major
def std_registration(std_name, std_age, std_major):
#start the nested run for and name it std_registration_run
with mlflow.start_run(nested=True,run_name="Student Registration") as std_registration_run:
# Simulate student registration process (e.g., database insertion, ID assignment)
std_id = generate_student_id()
#call the record_student_registration function and pass name, age, major and student id to the function
#this function stored the details into mysql database
with mlflow.start_run(nested=True,run_name="Store Student Registration to Database table") as std_registration_run:
record_student_registration(std_name, std_age, std_major, std_id)
# Log registration details as parameters in MLflow
mlflow.log_param("Student Name", std_name)
mlflow.log_param("Student Age", std_age)
mlflow.log_param("Student Major", std_major)
mlflow.log_param("Student ID", std_id)
#return the student id
return std_id
Nested Run of the Student Registration
The code creates a connection to the MySQL database and inserts the student data into the database table for students. The “mysql.connector” library is imported on the first line. With the help of this library, we may connect to the MySQL databases. A function called record_student_registration is defined in the second line. This function stores the student data in the MySQL database after receiving the student’s name, age, major, and student ID as inputs.
The host name, user name, password, and database name are the connection parameters. A cursor object is created in the fourth line. To run the SQL queries, a cursor object is used. The SQL query to add the student data to the students’ database table is specified in the fifth line.
The information about students is kept in the MySQL table called “students”. The SQL query is executed with the supplied parameters on the sixth line. The database is updated as a result of doing this. The cursor object is closed on the seventh line. The database connection is closed on the ninth line.
def record_student_registration(name, age, major, student_id):
# Connect to the MySQL database
db_con = mysql.connector.connect(
host="localhost", user="root", password="1234", database="UNI_DB"
)
# cursor object used to execute SQL queries
cursor = db_con.cursor()
# SQL query to insert student information into the students database table
sql_insert = "INSERT INTO students (name, age, major, student_id) VALUES (%s, %s, %s, %s)"
# Execute the SQL query with the provided parameters
cursor.execute(sql_insert, (name, age, major, student_id))
db_con.commit()
# Close the object of cursor and the connection
cursor.close()
db_con.close()
Nested Run: Student Enrollment
A new nested run called “Student Enrollment” is initiated by the code. The run keeps track of the actions that are taken to register a student for courses. In MLflow, the enrollment information is logged as parameters and metrics. A function called “std_enrollment” is defined on the first line.
This function logs the enrolment information in MLflow using the student ID and the list of courses as input. A nested run with the “Student Enrollment” name begins on the second line. The third line represents the application process for a course. This can entail verifying the course prerequisites, adding the student to the table of courses, or notifying the student through email.
The registration information is logged as parameters and metrics in MLflow in the fourth line. The student ID and courses are logged as parameters in MLflow in the fifth and sixth lines. The seventh line logs the number of students who are enrolled in classes as an MLflow metric.
with mlflow.start_run(nested=True,run_name="Student Enrollment") as enrollment_run:
# Simulate course enrollment process (e.g., checking prerequisites, adding to courses table)
enrolled_courses = record_enrollment(std_id, courses_list)
# Log enrollment details as parameters and metrics in MLflow
mlflow.log_param("enrolled_std_id", std_id)
mlflow.log_param("enrolled_courses", ", ".join(enrolled_courses))
mlflow.log_metric("num_courses_enrolled", len(enrolled_courses))
Other Nested Runs Code
This includes the generate_student_id, record_renrollment, print_transcript, and its nested runs:
with mlflow.start_run(nested=True,run_name="Generate Student ID") as enrollment_run:
# Generate a random alphanumeric student ID of length 10
Std_New_ID = string.ascii_letters + string.digits
student_id = ''.join(random.choice(Std_New_ID) for _ in range(10))
return student_id
def record_enrollment(std_id, courses_list):
# Register Student Courses and records Enrollment in Database
with mlflow.start_run(nested=True,run_name="Record Student Enrollment") as record_enrollment_run:
return courses_list
def get_student_grades(std_id):
with mlflow.start_run(nested=True,run_name="Calculate Grade") as calculate_grades_run:
# Fetch Student Grades Records from Database and Caculate Grades And return Final Grade
return "A"
def calculate_gpa(grades):
with mlflow.start_run(nested=True,run_name="Calculate GPA") as calculate_gpa_run:
return "4.0"
def print_transcript(std_id):
with mlflow.start_run(nested=True,run_name="Print Transcript") as transcript_run:
# Simulate transcript generation process (e.g., retrieving grades, calculating GPA)
grades = get_student_grades(std_id)
gpa = calculate_gpa(grades)
print("Student Grade: "+grades)
print("GPA: " +gpa)
# Log transcript details as metrics in MLflow
mlflow.log_metric("GPA", gpa)
Snippet of Complete Code:
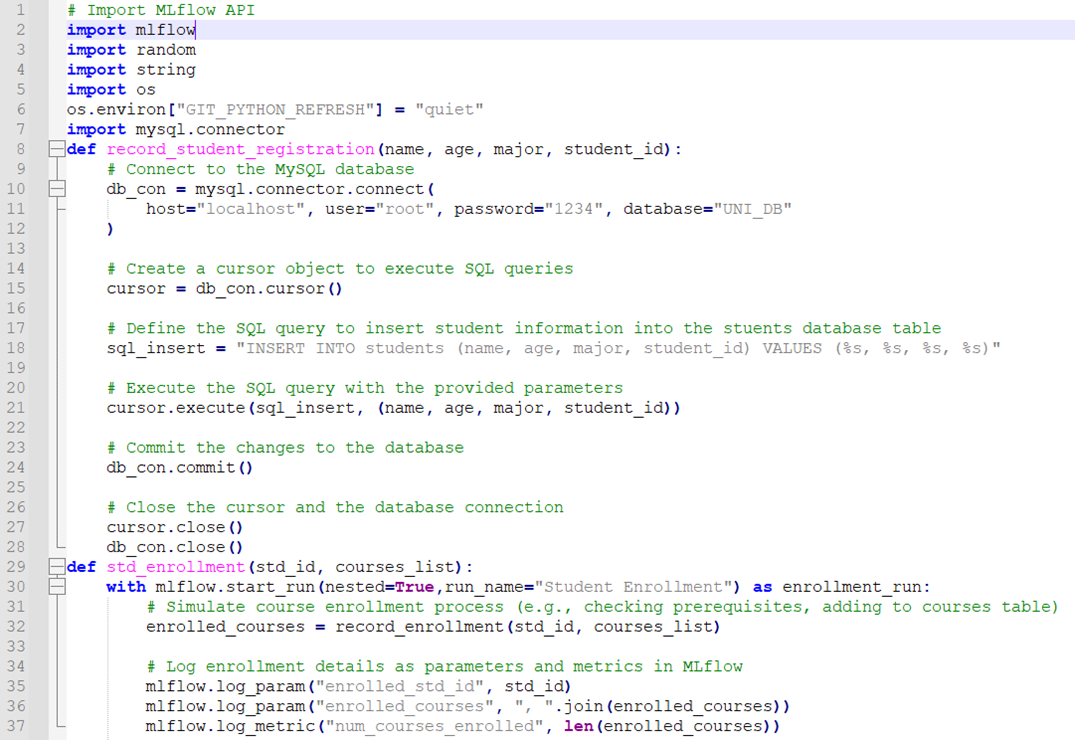
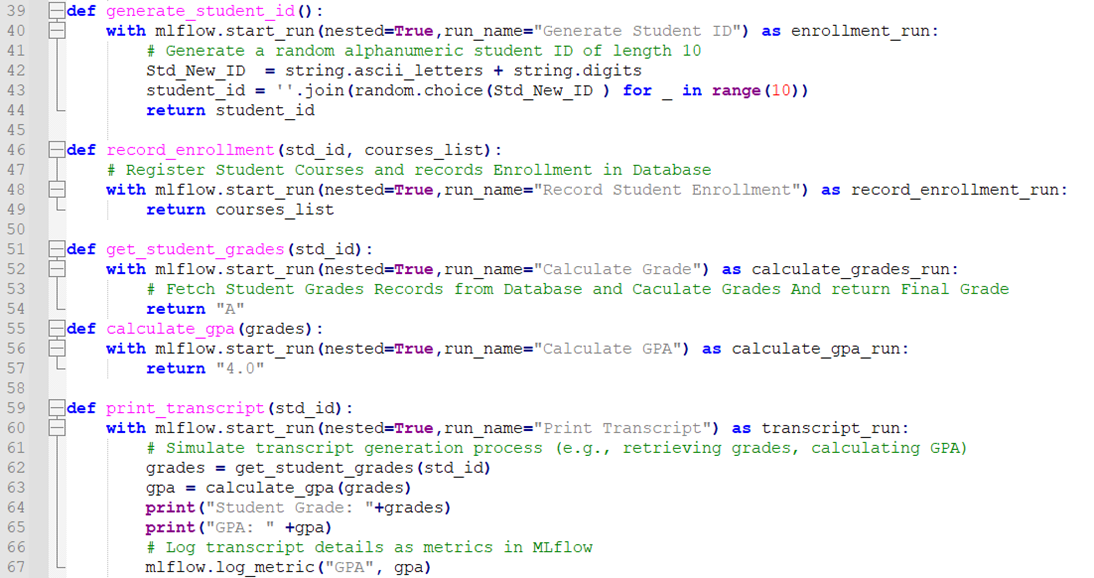
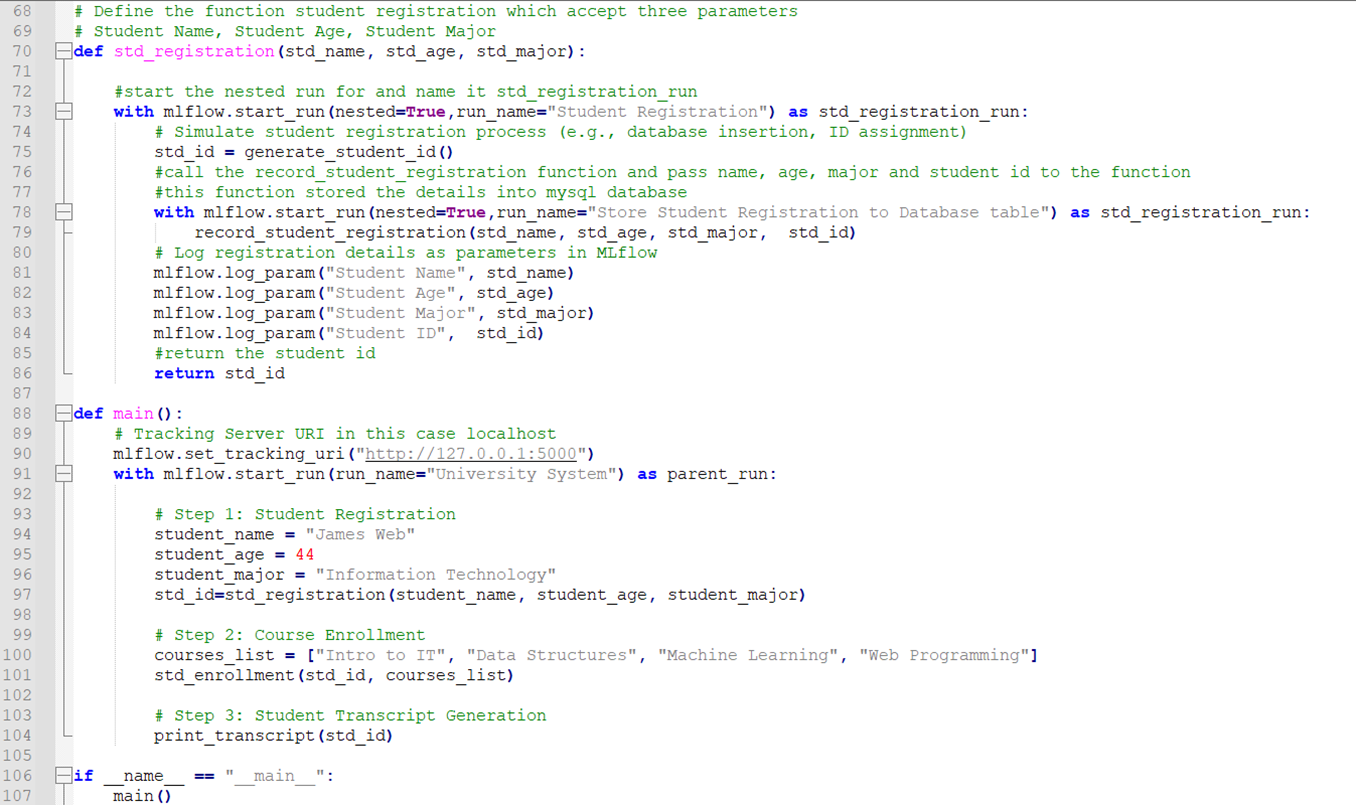
Execute the Code
Run the code using the Python compiler if it gives an error in the MySQL module like in the following:

To install the MySQL connector, enter the following command:
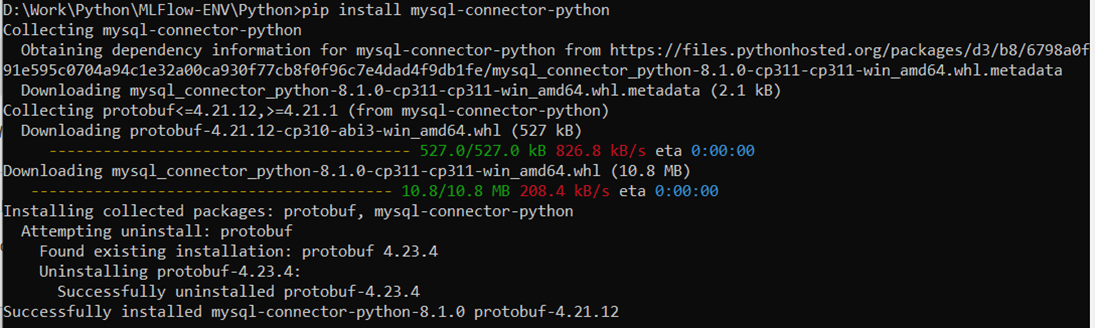
Here is the successful execution of nested runs:
![]()
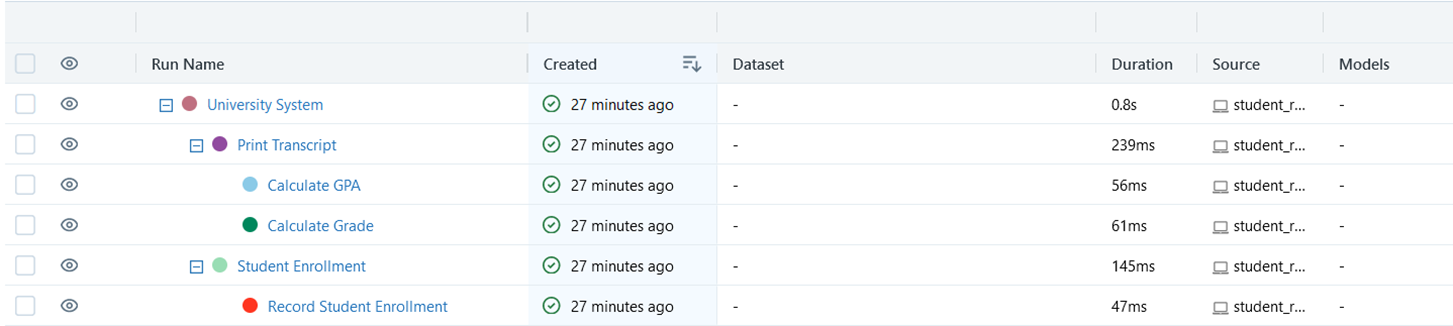
Tracking the UI Visualization: With nested runs, the MLflow Tracking UI shows a hierarchical view of the parent and nested runs. This makes it easy to analyze the overall workflow and drill down into each nested run to inspect the associated metrics, parameters, and artifacts. Here is the UI view of the nested runs:
Conclusion
Nested runs are a powerful way to track the complex workflows in MLflow. They allow breaking down a workflow into smaller, more manageable steps. This can make it easier to track the progress of the workflow, identify the steps that are causing problems, and reproduce the results of the workflow. The nested runs are used to improve traceability, reproducibility, and scalability.