In this blog, we will discuss how to implement a feature extractor in Transformer models.
What is the Importance of Extracting Features in Transformers?
The core aim of the training loop of Transformer models is to learn about the raw input data and recognize its many features to assess new data during inference. This “extraction” of features is fundamental to the success of a Transformer model and defines its applicability in real-world situations.
Key attributes of a Feature Extractor are listed below:
- Extracting features can reduce the number of dimensions of the raw input data thereby improving the processing time.
- It can also transfer the learned parameters from models that have been trained on millions of rows of data to new models that are yet to run their first training loop iteration.
- The possibilities for control are impressive with feature extraction because it gives a complete overview of the progress of the model.
- Controlling model progress also means that developers and data scientists can introduce new techniques within the model to optimize it.
- Extracting and learning about model features has the potential to allow users to make their model as efficient as possible by removing redundancies as they are found.
How to Implement a Feature Extractor in Transformers?
Features can only be extracted once we have defined the Transformer model and laid down its specifications to train on some data. Then, the unpacking operator can be employed to extract features for a better understanding of the progress of the model.
Follow the steps given below to learn how to implement a feature extractor in transformers:
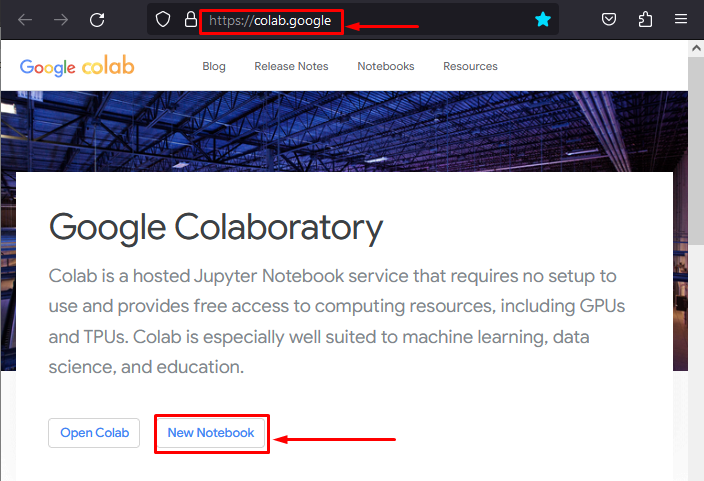
Step 1: Set up the Colab IDE
The first step includes the setup of an IDE. Open the Google Colab website and click on the “New Notebook” to get started:
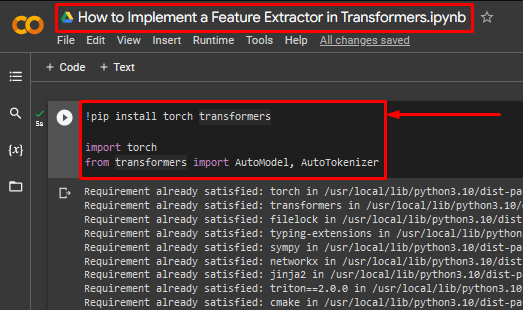
Step 2: Install and Import the Required Libraries
This tutorial needs the “torch” and “transformers” libraries to access all the functionalities required:
import torch
from transformers import AutoModel, AutoTokenizer
The above code works as follows:
- The “!pip” package installer by Python is used to install the torch and transformers libraries.
- Next, the “import” command is used to add the required libraries to the project.
- The “AutoModel” transformer and the “AutoTokenizer” are imported from the transformers library:
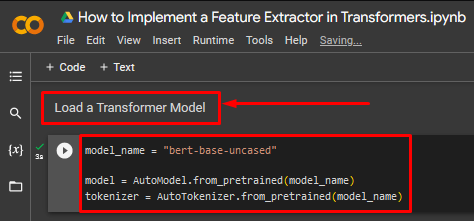
Step 3: Load the Transformer Model
Next, load the transformer model into the project to implement the feature extractor:
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
The above code works as follows:
- The model selected for demonstration in this tutorial is the “Bert” transformer model.
- Next, define the model using the “AutoModel.from_pretrained()” function as shown. Add the “model_name” variable as its argument.
- Lastly, define the tokenizer for the transformer model using the “AutoTokenizer.from_pretrained()” function as shown. Once again, add the “model_name” variable as its argument:
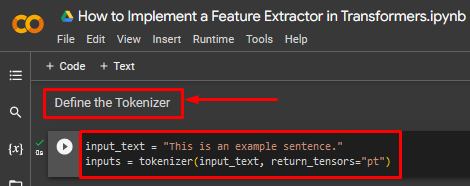
Step 4: Define the Tokenizer
This step involves specifying the code for the tokenizer of the transformer. This tokenizer will define how the raw input data is divided into equal bits to optimize processing:
inputs = tokenizer(input_text, return_tensors="pt")
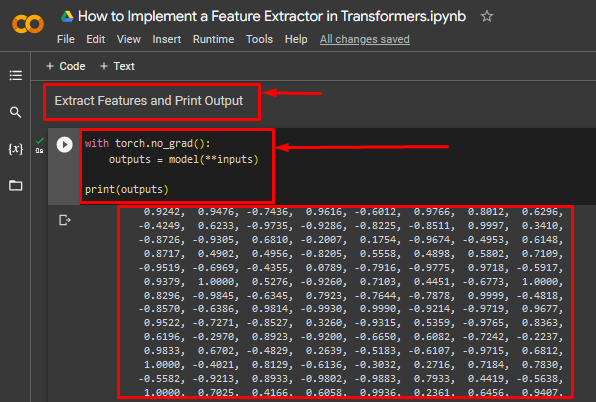
Step 5: Extract Features and Print Output
This tutorial is concluded by extracting the features from the “Bert” transformer and printing the output for display:
outputs = model(**inputs)
print(outputs)
The above code works as follows:
- The “with” loop is used to define the feature extractor method.
- The “torch.no_grad()” method is designed to remove gradient computation for PyTorch tensors to reduce the load on the hardware processor.
- The double-asterisk (**) as seen in the code is the syntax of the fundamental “unpacking operator” of the Python language.
- Lastly, the “print()” method is used to print the “outputs” variable.
The output below shows the tensor of the feature extractor with the output data values:
Note: You can access our Colab Notebook at this link.
Pro-Tip
Another technique to extract features from Transformers is to use the “get_output_embeddings()” method in PyTorch. The embedded layers accessed by this method possess the underlying features of the transformer models. These features control the progress of the model from behind the scenes.
Success! We have shown how to implement the feature extractor in Transformers.
Conclusion
Extracting Features in Transformers is done by first defining the Transformer model and its tokenizer and then extracting its features and printing the output. The extraction of features is crucial in obtaining an accurate overview of the progress of the model and avoiding pitfalls such as overfitting and local minima. In this blog, we have showcased how you can use a feature extractor in PyTorch Transformer models.