This post will demonstrate the process of generating hypothetical questions using a multivector retriever in LangChain.
How to Generate Hypothetical Queries Using MultiVector Retriever in LangChain?
Generating hypothetical queries can help the developer test the data set by getting the data using these queries and checking how the model responds. To learn the process of generating hypothetical queries using the MultiVector retriever in LangChain, simply go through the listed steps:
Step 1: Install Modules
First, install the LangChain module to get its dependencies for using the MultiVector retriever:
Install the Chroma database using the pip command to get the database for storing the vectors of the document:
Install the “tiktoken” tokenizer for splitting the document vectors into smaller chunks and store them in the Chroma database:
The last module to install is the OpenAI framework that can be used to get the OpenAI environment and use OpenAIEmbedding() method:
Step 2: Setup Environment & Upload Data
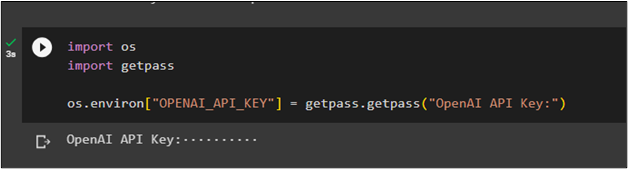
Now, the next step after getting all the required modules is to set the environment using the API key from the OpenAI account:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
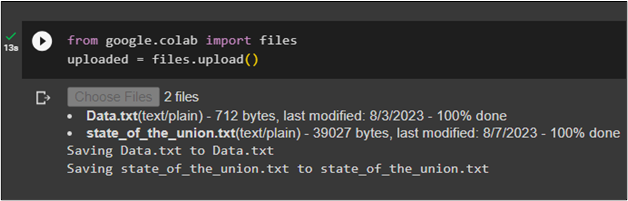
Use the following code to upload the documents in the Python Notebook after importing the files library:
uploaded = files.upload()
After executing the above code, simply click on the “Choose Files” button and upload documents from the local system:
Step 3: Import Libraries
After completing all the installations and setups, simply get the libraries from the installed modules for getting into the process of using the MultiVector retrievers:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
import uuid
from langchain.schema.document import Document
from langchain.storage import InMemoryStore
Using the TextLoader() method to load the documents uploaded in the Python Notebook in the second step:
TextLoader('Data.txt'),
TextLoader('state_of_the_union.txt'),
]
docs = []
for l in loaders:
docs.extend(l.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)
Step 4: Building Hypothetical Queries
Now, configure the functions variable with a template to get the hypothetical queries from the document loaded to the model:
{
"name": "hypothetical_questions",
"description": "Generate hypothetical questions",
"parameters": {
"type": "object",
"properties": {
"questions": {
"type": "array",
"items": {
"type": "string"
},
},
},
"required": ["questions"]
}
}
]
Step 5: Testing the Retriever
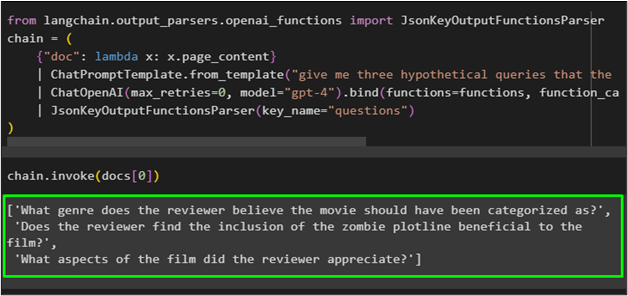
Now test the chains by setting the chains to get the hypothetical questions from the document as configured in the previous step:
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("give me three hypothetical queries that the below document can be used to answer:\n\n{doc}")
| ChatOpenAI(max_retries=0, model="gpt-4").bind(functions=functions, function_call={"name": "hypothetical_questions"})
| JsonKeyOutputFunctionsParser(key_name="questions")
)
Now simply run the chain with the index number of the document to get the hypothetical questions from the documents stored at index 0:
Step 6: Building Tokens
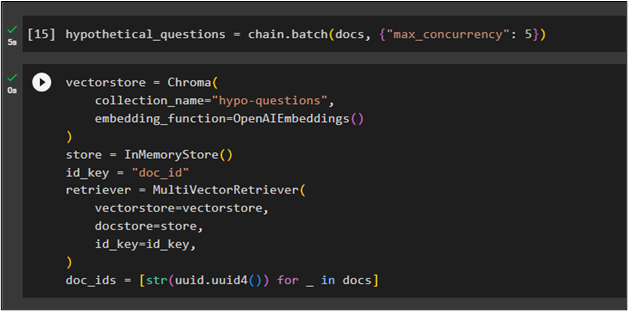
Now build the tokens for the hypothetical questions by running the chain.batch() method:
Configure the “vectorstore” variable by calling the Chroma() and InMemoryStore() methods with multiple arguments to store multiple documents:
collection_name="hypo-questions",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
Step 7: Using the Retriever
After that, simply create the documents containing hypothetical questions for each document to test the efficiency of the model:
for i, question_list in enumerate(hypothetical_questions):
question_docs.extend([Document(page_content=s,metadata={id_key: doc_ids[i]}) for s in question_list])
Store the question documents and the original documents with their ID numbers to call them whenever required:
retriever.docstore.mset(list(zip(doc_ids, docs)))
Get the hypothetical queries from a single document using a keyword inside the similarity_search() method:
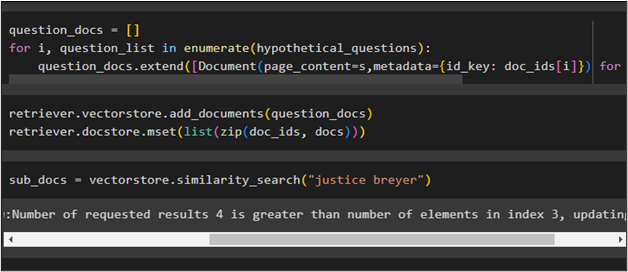
Step 8: Testing the Retriever
Now, test the retriever by printing the hypothetical questions extracted through the similarity_search() method:
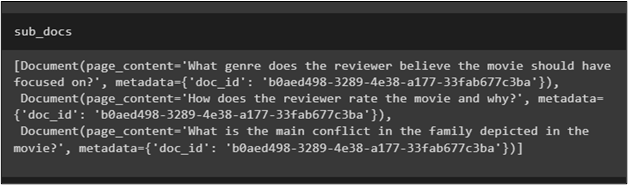
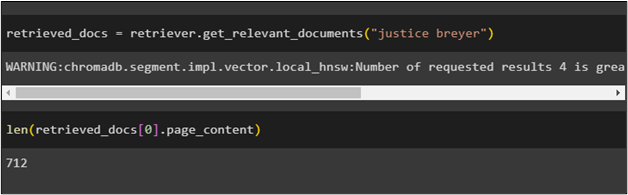
Use the retriever to get questions from all the relevant documents for the query mentioned in the retriever() function:
Print the length of all documents created with hypothetical questions using the retriever:
That’s all about using the MultiVector retriever in LangChain and to learn more about it, visit this guide:
Conclusion
To generate hypothetical questions using the MultiVector retriever in LangChain, simply import all the libraries after setting up the OpenAI environment. Upload the document into a Python Notebook to load it into the model for splitting it into small chunks. After that, build the prompt template for extracting hypothetical queries from each document and then print the length of all the documents’ continuing hypothetical queries. This post has illustrated the process of generating hypothetical questions using the MultiVector retriever in LangChain.