Syntax:
With the help of this article, we will be able to learn the method to use the Hugging Face datasets in Python. We will learn the tools and the methods to visualize, load, split, and train any Hugging Face dataset. The major benefit of using this Hugging Face library package is that we can use these datasets with other frameworks which include Numpy, Tensorflow, Pandas, and Pytorch. If we specifically want to train the natural language processing models, the Hugging Face’s library and its datasets are highly recommended. To load the datasets, we require the installation of the Hugging Face dataset library, and that can be done by simply using the following command:
The installation of the dataset’s library from Hugging Face is slightly different based on the type of requirement of the dataset. If we want to load the dataset that stored the audio data in it, we may install the dataset library using the command as follows:
If we want to acquire the datasets that have the relevant data to the computer vision/image recognition tasks, we install the Hugging Face library dataset as mentioned in the following lines:
Example 1: How to Visualize the List of the Datasets that Are Available in the Hugging Face Hub
Since we now know about the methods to install the datasets library package, we will see how we can visualize what datasets are available under the Hugging Face datasets library in this example. To do so, we follow the method as explained previously to download the datasets library with the help of the pip command. After this, we import the “list_datasets” and from the “pprint” from the datasets. We also import the “pprint ()” to display the results.
With this, we import of the packages now. We use the “list_datasets ()” function to save it in some variables like “data”. Then, we pass this data to the pprint() function. Now, we run this code and the output displays the lists of the datasets that are available and can be loaded to train them on any neural network. The snippet for this example is given as follows:
from datasets import list_datasets
from pprint import print
dataset = list_datasets()
pprint(dataset,compact=True)
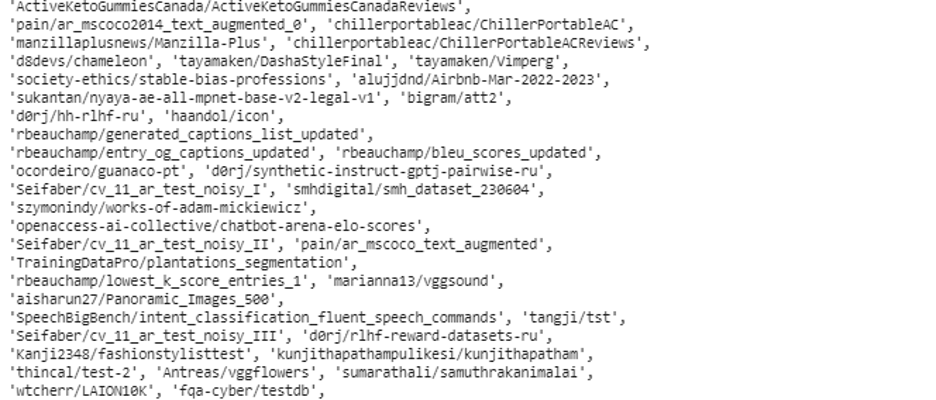
If we want to know the details of the datasets that are being displayed in the list, we follow the same method as we did earlier in this example. But this time around, while calling the “list_dataset()” function, we add an argument to this function which is “with_details” and set its value equals to Boolean “True”. Then, we print it using the pprint() function. This is shown in the following code:
from datasets import list_datasets
from pprint import pprint
datasets = list_datasets(with_details=True)
pprint(datasets)

Adding the with_details argument, the list_dataset displays the list of the available datasets with the id names, the descriptions, and the file types of the datasets.
Example 2: Loading the Hugging Face Dataset
When we want to work on a specific type of dataset, we need to know a complete description of that dataset so that we should be aware that we are choosing the right dataset. So, before loading the data set, we can use a “load_dataset_builder()” and check for the features and the attributes of the dataset before actually downloading it.
After installing the datasets library, import the “load_dataset_builder” package. Now, use this function and pass any dataset name to the input argument of this function, e.g. rotten_tomatoes dataset, and then save it in some variable. Then, call this variable with the “.info.description” and just display its output. The dataset builder gives information about the classes of the datasets and other details.
Also, if we want to know about the features of the dataset, we can call the variable again where we loaded the datset_builder with the “.info.features” and it displays the class labels and the features/text’s type as str, int char, etc. If, after knowing the information about the dataset we still want to load the dataset, we import the “load_datasets” from the datasets. Then, use the load_dataset() function with its input arguments set as the “name” of the dataset and the part of the dataset which we want to download like validation, train, or test instead of the entire dataset. This can be done by following the method as follows:
from datasets import load_dataset_builder
dataset = load_dataset_builder("rotten_tomatoes")
dataset.info.description

from datasets import load_dataset_builder
dataset = load_dataset_builder("rotten_tomatoes")
dataset.info.features

Example 3: Loading the Dataset from the Local File
We can also download any dataset of any file format from our local machines. To do so, we use the load_dataset() function. We first specify the type or the format of the file of the dataset, e.g. CSV to its input arguments. Then, specify the second argument as the “file path” which is the location where the file is located in your local machine. This is shown in the following lines of code:
from datasets import load_dataset
dataset = load_dataset('csv', data_files='my_file.csv')
Conclusion
We now learned the methods to use the Hugging Face datasets in Python. We demonsrated three examples that show the methods to check the information regarding the dataset before downloading and the methods to load the datasets’ files with different file formats.