Using Pandas.DataFrame.Drop
The pandas.DataFrame.drop() is used to drop specific rows/columns from the Pandas DataFrame. We can drop the rows/columns based on the axis value (0 or 1).
Syntax:
Let’s see the syntax and parameters that are passed to this function:
1. The row labels are passed to the “labels” parameter (by default = None). You can pass the single row label/row index inside a tuple. Pass the columns through a list if you want to drop multiple rows.
2. The “axis” (by default = 0) parameter is used to drop the rows. There is no need to pass this parameter.
3. The “inplace” parameter updates the original DataFrame if it is set to “True”. By default, it is “False”. If it is set to “False”, the original DataFrame is not updated and it needs to store the result in another DataFrame or any object in this scenario.
Example 1: Drop the Rows Using the Labels
We delete single/multiple rows based on the index label. Let’s create a DataFrame (Contacts) with three columns and five records. Pass the index labels [“C1”, “C2”, “C3”, “C4”, “C5”] to the “index” parameter while creating the DataFrame itself.
1First, we drop the second row by passing “C2” to the “labels” parameter.
Contacts = pandas.DataFrame([['Sravan','Manager', 'Sales'],
['Manju','Lead', 'Technical'],
['Siri','Analyst', 'Marketing'],
['Gowthami','Trainee', 'Technical'],
['Rani','Trainee', 'Technical']],
columns=['Name', 'Role','Department'],
index=['C1','C2','C3','C4','C5'])
print(Contacts,"\n")
# Drop second row
final_Contacts=Contacts.drop(labels=('C2'),axis=0)
print(final_Contacts,"\n")
# Drop first three rows
final_Contacts=Contacts.drop(labels=['C1','C2','C3'],axis=0)
print(final_Contacts,"\n")
Output:

There are five rows in the “Contacts” DataFrame. After removing the second row, the total number of records is four. After dropping the first three rows, the DataFrame holds only two rows.
Example 2: Drop the Rows Using the Index Position
Utilize the previous “Contacts” DataFrame and drop the rows using the index position. Indexing starts from 0. So, we pass the Contacts.index[] to the “labels” parameter. The row index positions are specified within the square brackets.
1. Drop the first row – labels=Contacts.index[0].
2. Drop last two rows – labels=Contacts.index[[3,4]]
Contacts = pandas.DataFrame([['Sravan','Manager', 'Sales'],
['Manju','Lead', 'Technical'],
['Siri','Analyst', 'Marketing'],
['Gowthami','Trainee', 'Technical'],
['Rani','Trainee', 'Technical']],
columns=['Name', 'Role','Department'],
index=['C1','C2','C3','C4','C5'])
print(Contacts,"\n")
# Drop first row
final_Contacts=Contacts.drop(labels=Contacts.index[0],axis=0)
print(final_Contacts,"\n")
# Drop last two rows
final_Contacts=Contacts.drop(labels=Contacts.index[[3,4]],axis=0)
print(final_Contacts,"\n")
Output:
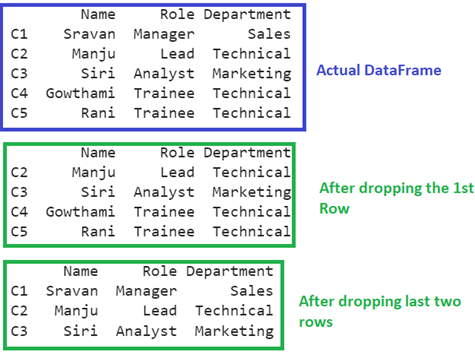
There are five rows in the “Contacts” DataFrame. After removing the first row, the total number of records is four. After dropping the last two rows, the DataFrame holds only three rows.
Example 3: Drop the Rows Using the Default Index
We have the same DataFrame with no index labels. The default indices are 0, 1, 2, 3, and 4.
1. Drop the first row by specifying the default index as 0.
2. >Drop first, third, and last rows by specifying the default indices as 0, 2, and 4.
Contacts = pandas.DataFrame([['Sravan', 'Sales'],
['Manju','Technical'],
['Siri', 'Marketing'],
['Gowthami', 'Technical'],
['Rani', 'Technical']],
columns=['Name','Department'])
print(Contacts,"\n")
# Drop first row by specifying default index
final_Contacts=Contacts.drop(labels=0)
print(final_Contacts,"\n")
# Drop multiple rows by specifying default indices
final_Contacts=Contacts.drop(labels=[0,2,4])
print(final_Contacts,"\n")
Output:

There are five rows in the “Contacts” DataFrame. After removing the first row, the total number of records are four. After dropping the last two rows, the DataFrame holds only three rows.
Example 4: Drop the Rows Conditionally Using Isin()
The tilde operator (~) negotiates the condition that is specified in the isin() function.
1. Remove the rows where the Department is “Technical”.
2. Remove the rows where the Department is “Sales”.
Contacts = pandas.DataFrame([['Sravan',45, 'Sales'],
['Manju',37, 'Technical'],
['Siri',25, 'Marketing'],
['Gowthami',22, 'Technical'],
['Rani',56, 'Technical']],
columns=['Name', 'Age','Department'])
print(Contacts,"\n")
# Use the isin() with ~ to remove the rows where Department is "Technical"
final_Contacts= Contacts[~Contacts["Department"].isin(["Technical"])]
print(final_Contacts,"\n")
# Use the isin() with ~ to remove the rows where Department is "Sales"
final_Contacts= Contacts[~Contacts["Department"].isin(["Sales"])]
print(final_Contacts,"\n")
Output:
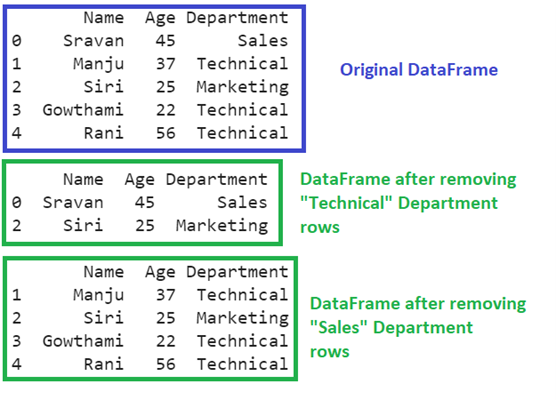
Three “Technical” rows exist in the DataFrame under the “Department” column. These three rows are removed from the DataFrame and one “Sales” row exists under the “Department” column. So, only one row is removed from the DataFrame.
Example 5: Drop the Rows Conditionally Using Loc[]
Basically, the loc[] property is used to select the rows based on the row labels. The tilde operator (~) negotiates the condition that is specified in the loc[] property. Use this property with ~ to remove the rows with Age > 38.
Contacts = pandas.DataFrame([['Sravan',45, 'Sales'],
['Manju',37, 'Technical'],
['Siri',25, 'Marketing'],
['Gowthami',22, 'Technical'],
['Rani',56, 'Technical']],
columns=['Name', 'Age','Department'])
# Use the loc[] property with ~ to remove the rows with Age > 38
final_Contacts= Contacts.loc[~(Contacts['Age'] > 38)]
print(final_Contacts,"\n")
Output:

There are two rows with an age that is greater than 38 (45 and 56). These two rows are removed from the “Contacts” DataFrame.
Example 6: Drop the Rows that Contain Missing Values
1. Drop the row if any missing values are present by passing “any” to the “how” parameter.
2. Drop the row if all are missing by passing “all” to the “how” parameter.
3. Drop the rows that are present in “Name” and “Age” columns by passing the “subset” parameter.
Contacts = pandas.DataFrame([['Sravan',45, None],
['Manju',37, 'Technical'],
[None,None ,None],
['Gowthami',22, 'Technical'],
[None,56, 'Technical']],
columns=['Name', 'Age','Department'])
print(Contacts,"\n")
# Drop the row if any missing values are present
print(Contacts.dropna(how='any'),"\n")
# Drop the row if all are missing
print(Contacts.dropna(how='all'),"\n")
# Drop the rows that are present in 'Name' and 'Age' columns.
print(Contacts.dropna(subset=['Name', 'Age']),"\n")
Output:
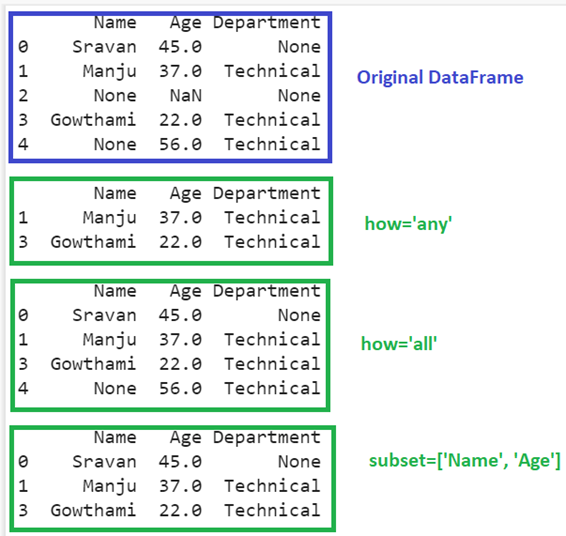
1. how = ‘any’ : There are only three rows in the DataFrame with at least one missing value. So, these three are dropped from the DataFrame.
2. how = ‘all’ : There is one row in the DataFrame that holds all missing values. So, it is dropped.
3. subset=[‘Name’, ‘Age’] : The rows are dropped with the missing values that are present in the “Name” and “Age” columns.
Conclusion
We learned how to drop the rows from the Pandas DataFrame using the pandas.DataFrame.drop() function. Three examples are discussed in this scenario based on the labels and default indices. Then, we discussed how to remove the rows conditionally using the pandas.DataFrame.isin() function and pandas.DataFrame.loc[] property. Finally, we provided an example by removing the rows with missing values using the pandas.DataFrame.dropna() function.