Machine learning (ML) projects can be handled throughout their lifecycle using the MLflow framework. Data versioning is one of the features that it offers to track the ML experiments. The “mlflow.data.version” API can be used to create the data versioning in MLflow. This API makes it feasible to keep track of a dataset’s version and any modifications that have been made to it.
Data artifacts such as datasets can be kept in parallel with the metadata of machine learning that runs using MLflow. Maintaining the track of the data that is employed throughout the model development lifecycle is straightforward because these artifacts may be versioned and accessible with ease.
Artifacts Data Versioning
Data management and versioning are both possible with the help of the “artifacts” notion that is offered by MLflow. In MLflow, the artifacts are the files or directories that can be downloaded, versioned, and tracked. Establish the data versioning via the following steps:
Step 1: Install MLflow
First, ensure that MLflow is installed or install it via the pip command:
Step 2: Create an MLflow Project Directory (Optional)
Here, we create a project data which is “mlflow_versions_project” that is used for artifacts versioning purposes:
Make a directory for the data set and add the data file (such as a CSV file) to it:
![]()
![]()
![]()
Here is the screenshot of the dataset directory:

Step 3: Log the Dataset as an Artifact
To log the dataset as an artifact, use the mlflow.log_artifact() function to log it.
The following code logs the dataset as an artifact to the specified location. The artifact will be versioned, so track its changes over time. The first line of the code specifies the path to the folder in which we want to keep the artifacts. Setting the MLFLOW_TRACKING_URI in the environment variable accomplishes this. In this case, the path is “mlflow_customer_artifacts”.
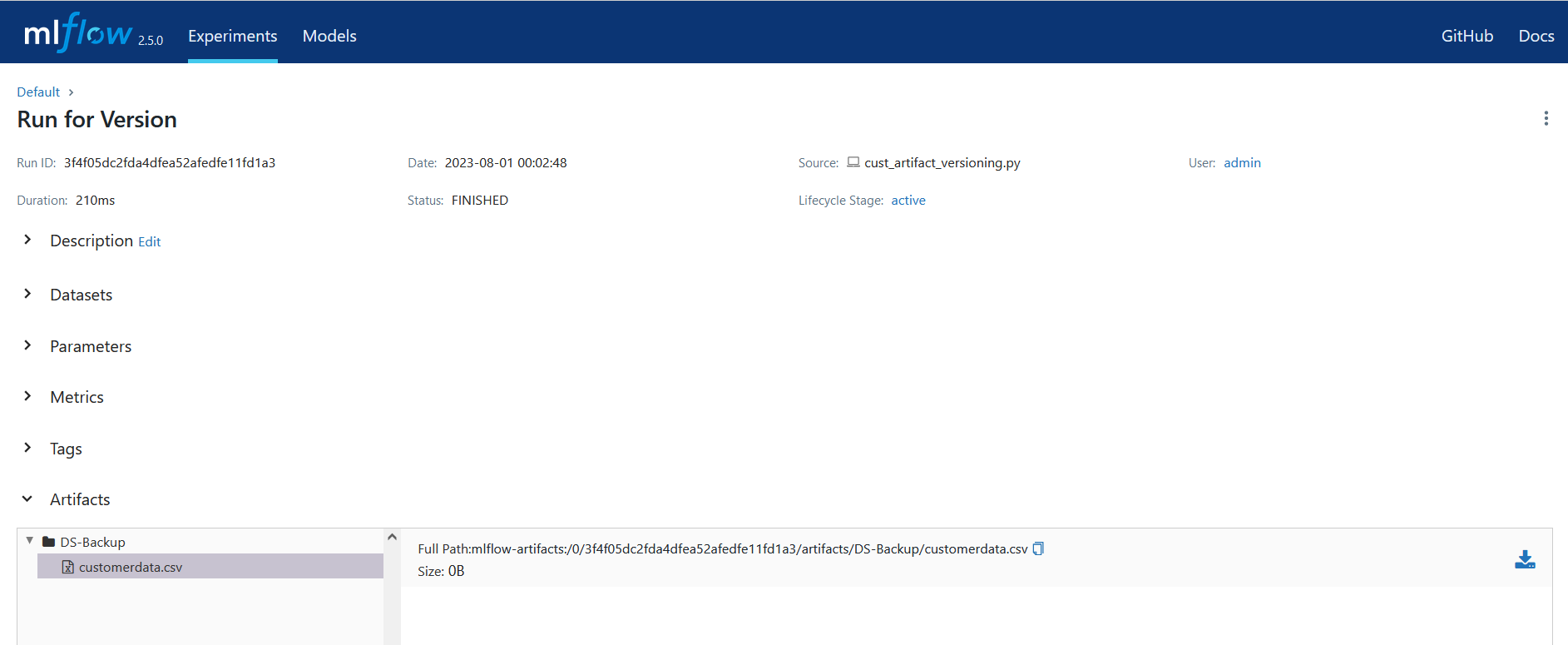
Next, the code starts an MLflow run to log the artifact. The run is given with the “Run for Version” name. The dataset is then logged as an artifact to the specified location. The dataset_location variable determines the locale. The artifact is given with the “DS-Backup” name.
Finally, the code prints a success message to the screen.
Code Snippet:
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
# Set the path to the folder where we want to store the artifacts
project_artifacts = "mlflow_customer_artifacts"
# Set the Tracking URI desired location
#mlflow.set_tracking_uri(project_artifacts)
mlflow.set_tracking_uri("http://127.0.0.1:5000")
# Location of file that contains dataset
dataset_location = "Dataset_Customer/customerdata.csv"
# Start an MLflow run to log the artifact
with mlflow.start_run(run_name="Run for Version") as run_version:
# Log the dataset as an artifact to the specified location
mlflow.log_artifact(dataset_location, "DS-Backup")
# Print the success message on the screen
print("Artifact versioning successful!")
print("Run ID: "+run_version.info.run_id)
print("Artifact Path (Artifact URI):", run_version.info.artifact_uri)
Step 4: Execute the Python Code
Run the code from the command line after saving it as a Python file. If we save the code as cust_artifact_versioning.py, for instance, we can execute it by typing the following command on the command prompt or terminal window:
The code prints the “Artifact versioning successful!” success message to the screen.

Step 5: Track the Different Versions of Artifacts or Data Sets
Record multiple versions of the dataset by creating various runs and giving the dataset artifacts with different names. The datasets that are contained in the designated artifact directory (in this case, “DS-Backup”) will be versioned by MLflow. We can then check the artifact store to see that the artifact has been successfully logged.
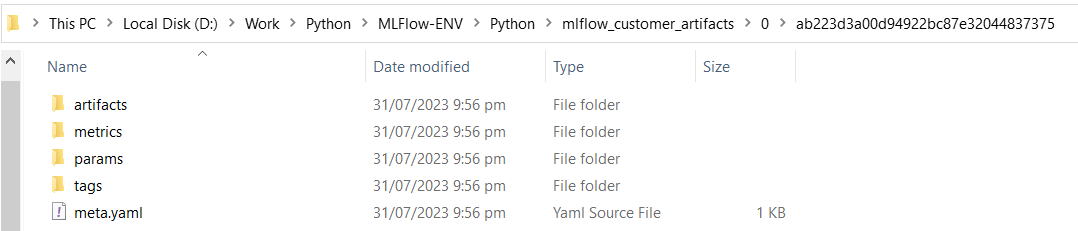
Each time the Python program is executed, a new folder is created for that run. That folder contains the artifacts folder, which includes the DS-Backup folder, which has the “customerdata.csv” file. Here are the screenshots of different versions of runs that are created on each execution:
Created on Run Version 1:

Created on Run Version 2:

Note: If we go back to the run folder, we can see that the metrics, parameters, tags, and artifacts folders are created on the execution of each run. So, MLflow, by default, is doing the versioning of data and other details of experiments.
Step 6: Retrieve the Run ID
The MLflow run that is established in the code is referenced by the run_version variable. The run_version variable’s info attribute details the run, including the run ID. An exclusive identifier for the run is the run_id. The run ID is printed to the screen using the print() function. The run ID is prefixed with the “Run ID:” string to make it easier to understand:

Step 7: Fetch the Dataset from a Specific Run
We can use the MLflow API to retrieve a specific version of the dataset. Please provide the run ID and artifact path:
# Specify the run ID and the dataset's artifact path
run_id = "bac9445396ed45e2a25cf5bdf2c9e63a"
# Set the artifact path which is DS-Backup in this case
artifact_path = "DS-Backup"
# Download the dataset artifact from the specified run
mlflow.artifacts.download_artifacts(run_id, artifact_path, dst_path="downloaded_dataset")
Step 8: Set the Tracking Server for the Versioning of Data
Add the following line to set the tracking server for the data version:
The dataset file will be posted for each run, and we can download it by selecting a run at a given time and date.

The MLflow module is initially imported by the code. This module offers several tracking options for ML experiments such as logging the metrics, parameters, and data artifacts. Setting the MLflow URI is the following step. This is the location of the MLflow tracking server.
In this case, the localhost’s port 5000 is being used by the tracking server. After that, the train_ML_Model function is defined. This function logs the metrics, parameters, and data artifacts for the specified data version that is passed in as input. Using the log_artifact function, the data artifacts are recorded. Using the log_param function, the data version is recorded as an attribute. Using the log_metric function, the model metrics and parameters are logged.
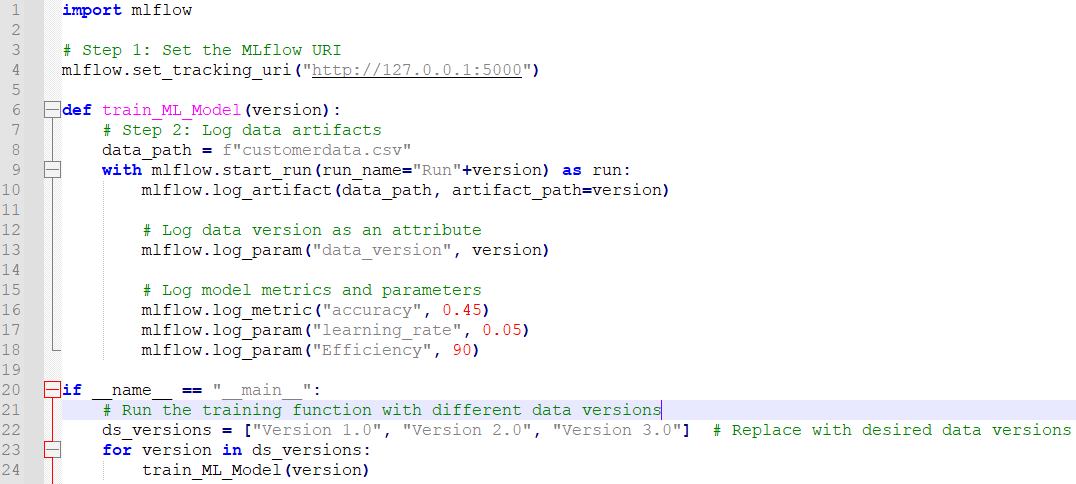
The main procedure is then completed. As this function runs through the list of data versions, the train_ML_Model function is invoked for each data version. The code can be run by saving it into a Python file and then running the file from the command line.
Code Details:
# Step 1: Set the MLflow URI
mlflow.set_tracking_uri("http://127.0.0.1:5000")
def train_ML_Model(version):
# Step 2: Log data artifacts
data_path = f"customerdata.csv"
with mlflow.start_run(run_name="Run"+version) as run:
mlflow.log_artifact(data_path, artifact_path=version)
# Log data version as an attribute
mlflow.log_param("data_version", version)
# Log model metrics and parameters
mlflow.log_metric("accuracy", 0.45)
mlflow.log_param("learning_rate", 0.05)
mlflow.log_param("Efficiency", 90)
if __name__ == "__main__":
# Run the training function with different data versions
ds_versions = ["Version 1.0", "Version 2.0", "Version 3.0"] # Replace with desired data versions
for version in ds_versions:
train_ML_Model(version)
Working Screenshots:
![]()
Here is the output of the code on the Tracking Server UI:

Conclusion
MLflow offers various features for machine learning code including experiment tracking, model packaging, model registry, data versioning, code versioning, artifacts management, tracking server, and API/CLI. It allows for easy tracking and comparison of experiments, package the models, manage the data versioning, and store the artifacts. Version control systems like Git manages the code versioning. MLflow also provides a tracking server for runs, experiments, and artifacts metadata. MLflow offers a comprehensive suite of tools for machine learning, simplifying the workflow management and improving the collaboration, reproducibility, and efficiency in the machine learning community.