In this blog, we will cover the below-provided content:
- How to Customize Text Generation by Loading Model With “pipeline” Function from Transformers?
- How to Utilize a Transformer-Based Model for Generating Text in PyTorch?
- How to Utilize a Transformer-Based Model for Generating Text in TensorFlow?
How to Customize Text Generation by Loading the Model With “pipeline” Function from Transformers?
The “pipeline” function is used to automatically download the pre-trained AI model according to the user’s requirements. To use this particular function, users need to install the “transformers” packages. This package gives access to state-of-the-art Transformer-based models that can perform sentiment analysis as well as multiple other Natural language processing (NLP) tasks.
To check out the practical demonstration of the above-described scenario, move to the below-given steps!
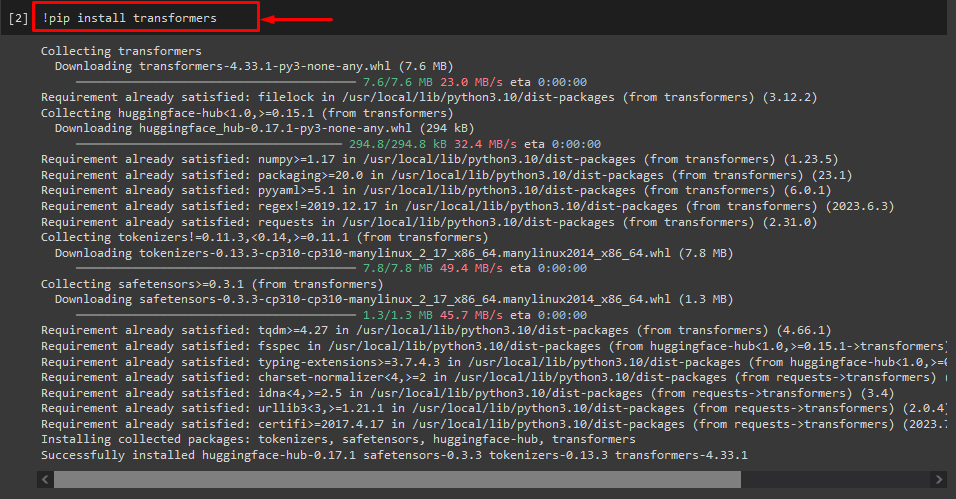
Step 1: Install “transformers” Packages
Initially, execute the “!pip” command to install the transformer packages:
As you can see, the specified package has been installed successfully:
Step 2: Import Transformer-based Model
Afterward, import the required transformer-based model. To do so, first, import the “pipeline” function from “transformers”. Next, use the imported function and pass the “text-generation” as an argument to it along with the required model name “gpt2”. Next, pass them to the “generate” variable:
generate = pipeline('text-generation', model='gpt2')
Step 3: Generate Customize Text
Now, pass the desired text as an argument to the “generate”. As shown below:
According to the provided output, the downloaded pre-trained “gpt3” model has been generated text successfully:

You can also use the other arguments, such as:
pprint(gen(prompt,num_return_sequences = 5, max_length = 20))
Here:
- “prompt” is used as an argument that holds out input.
- “num_return_sequance” argument is used to generate the number of sequences of the provided text.
- “max_length” argument is utilized to specify the length of the generated text. In our case, it is limited to “30” tokens(words or punctuation):
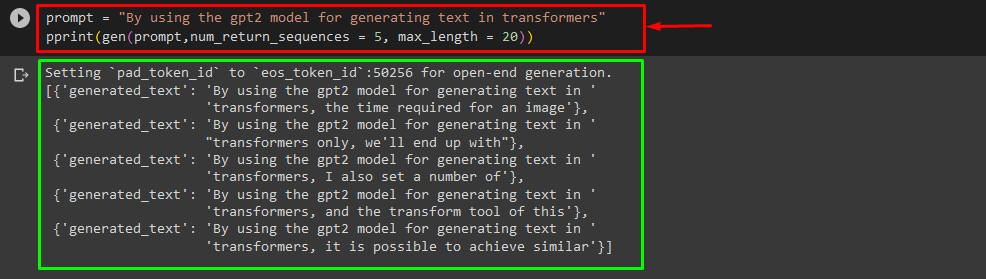
Note: The customized text will be a continuation of the specified prompt that is based on the model’s training data.
How to Utilize a Transformer-Based Model for Generating Text in PyTorch?
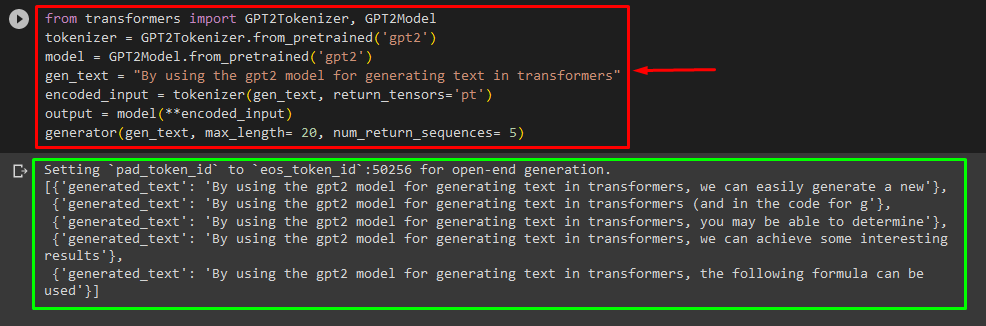
Users can also customize the text in “PyTorch” which is the “Torch” based machine learning framework. It is utilized for different applications, such as NLP and Computer Vision. To use the transformer-based model for customizing the text in PyTorch, first, import the “GPT2Tokenizer” and “GPT2Model” functions from the “transformers”:
Then, use the “GPT2Tokenizer” tokenizer according to our desired pre-trained model named “gpt2”:
Afterward, instantiating the weights from a pre-trained model:
Next, declare a “gen_text” variable that holds the text that we want to customize:
Now, pass the “gen_text” and “return_tensors=‘pt’” as an argument that will generate the text in PyTorch and store the generated value in the “encoded_input” variable:
Lastly, pass the “encoded_input” variable that holds the customized text to the “model” as a parameter and get the resultant output using the “max_length” argument that is set to “20” which indicates that the generated text will be limited to a provided tokens, the “num_return_sequences” that set to “5” that shows that generated text will be relying on 5 sequences of text:
generator(gen_text, max_length= 20, num_return_sequences= 5)
Output
How to Utilize a Transformer-Based Model for Generating Text in TensorFlow?
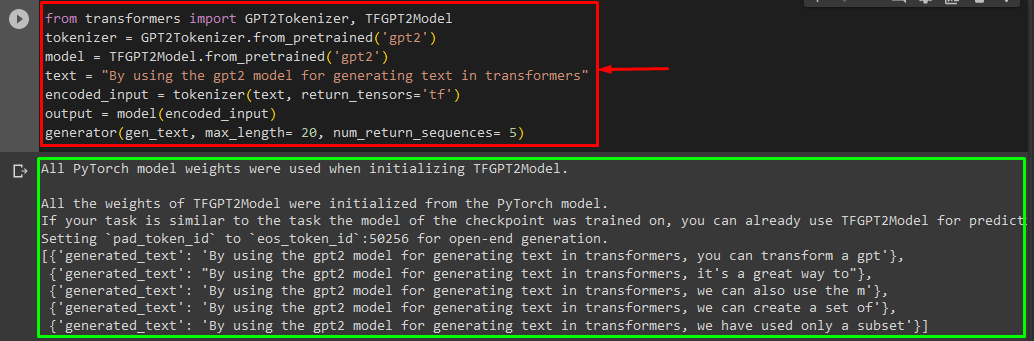
For generating the text in Transformers, the “TensorFlow” based machine learning frameworks are also used. To do so, first, import the required functions, such as the “GPT2Tokenizer” and “TFGPT2Model” from the “transformers”. The rest of the code is the same as above, just we use the “TFGPT2Model” function instead of the “GPT2Model” function. As follow:
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = TFGPT2Model.from_pretrained('gpt2')
text = "By using the gpt2 model for generating text in transformers"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
generator(gen_text, max_length= 20, num_return_sequences= 5)
As you can see, the customized text has been generated successfully:
That’s it! We have elaborated on customizing text generation in Transformers.
Conclusion
To customize text generation in Transformers, there are different ways such as loading the model with the pipeline function, using the transformer-based model in “PyTorch” and “TensorFlow” which are based on machine learning frameworks. In this guide, we have provided brief information along with a practical demonstration of customizing text generation in Transformers.