Syntax:
Different functions fall under the Natural Language Processing for the word embedding of the text. This article covers the “word2vec” function for this purpose. To make it clearer, the word embedding converts our text inputs into the vector representation where those words that have more or less the same contextual meanings have given the same representation.
The “word2vec” algorithm is a neural network model which is trained in such a way that it learns the embedding of the words by first predicting the word’s context in which it appears. This model takes in the text as its input. Then, for each word in the text, the vector representation is created for that word. This model is based on the idea that the words that appear to have the same context have the same meanings. The syntax for “word2vec” is as follows:
This algorithm has two parameters which are “sentences” and “minimum_count”. The sentence is the variable where the list of sentences or the text in the form of sentences is stored and the minimum_count talks about the count value of 1 which means that any of the words in the text that has appeared less than one needs to be ignored.
Example 1:
In this example, we create the word embeddings for the words that exist in the list of English sentences. To create the word “embedding”, we need to use the “word2vec” model. This model is a package of Python’s “gensim” library. We need to have Gensim installed in our Python library repositories to work with “word2vec”.
To implement this example, we will work on the “google colab” online Python compiler. To install the gensim, use the “pip install gensim” command. This starts downloading this library with all its associated packages. Once it is installed, siwe import the “word2vector” package from the gensim.
To train this “word2vec” model, we need to create a training dataset. For that, we create a list of sentences that contains four to five English sentences. We save this list in the “training_data” variable.
Our next step after creating the training dataset is to train the “word2vec” model on this data. So, we call the model. We give the training data in the input parameters of this model which we saved in the “input” variable. Then, we specify the second parameter which is the “minimum_count”. We set its value equal to “1”. The output from this training model is saved in the “trained_model” variable.
Once we are done with training the model, we can simply access the model with the “wv” prefix which is the word vector model. We may also access the token’s vocabulary of our words and can print them with the method as follows:
The model represents the trained model in our case. Now, we access the vector representation of the one word in the list of the sentence which, in our case, is “apple”. We do this by simply calling the trained model. We pass the word whose vector representation we want to print as “model. wv [‘apple’]” to its input argument. Then, we print the results with the “print” function.
training_data = [['apple', 'is', 'the', 'sweet', 'apple', 'for', 'word2vec'],
['this', 'is', 'the', 'second', 'apple'],
['here', 'another', 'apple'],
['one', 'sweet', 'apple'],
['and', 'more', 'sweet', 'apple']]
model = Word2Vec(training_data, min_count=1)
print(model)
vocabof_tokens = list(model.wv.index_to_key)
print(vocabof_tokens)
print(model.wv['apple'])
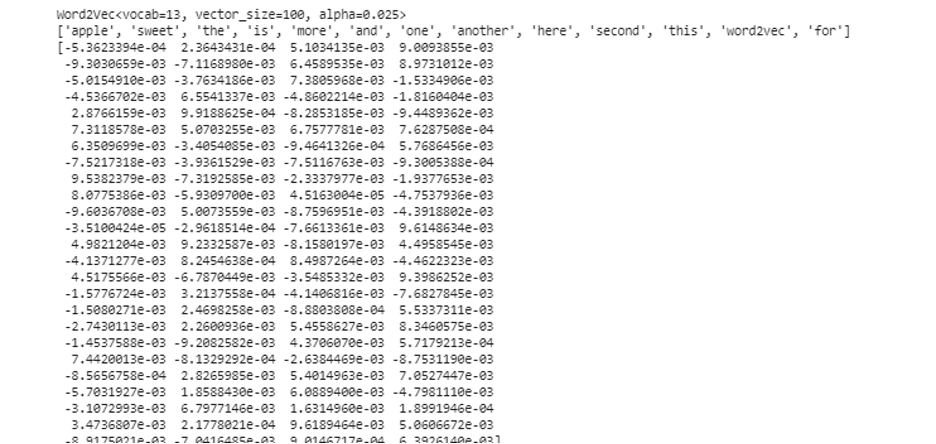
From the previously mentioned output and code, the word embedding for the word “apple” is shown. In the example, we first created a training dataset. Then, we trained a model on it and summarized the model. Then, using the model, we got an access to the token vocabulary of the words. After that, we displayed the word embedding for the word “apple”.
Example 2:
Using the gensim library, let’s create another list of sentences. Train our model for each word in the sentence to create the word embedding using the “word2vec” model. First, from the gensim library package, the “word2vec” model is imported. Then, we create another data set which will be the list that has the two sentences in it. Each sentence in the list has four words.
Now, we save this list in the “data” variable. Then, we call the “word2vec()” model and feed the data to the arguments of this model with the minimum_count value which is equal to “1”. This is how we train our model. Now, it is able and can learn the word embedding of the words that exist in the sentences that are present in the list by predicting the context in which they exist. To test the results of our model, we simply pass a word like “dog” in our data to the model. Then, we print the results using the “print()” function.
data = [["rabbit", "has", "teeth"], ["dog", "has", "ears"]]
model = Word2Vec(data, min_count=1)
print(model.wv["dog"])
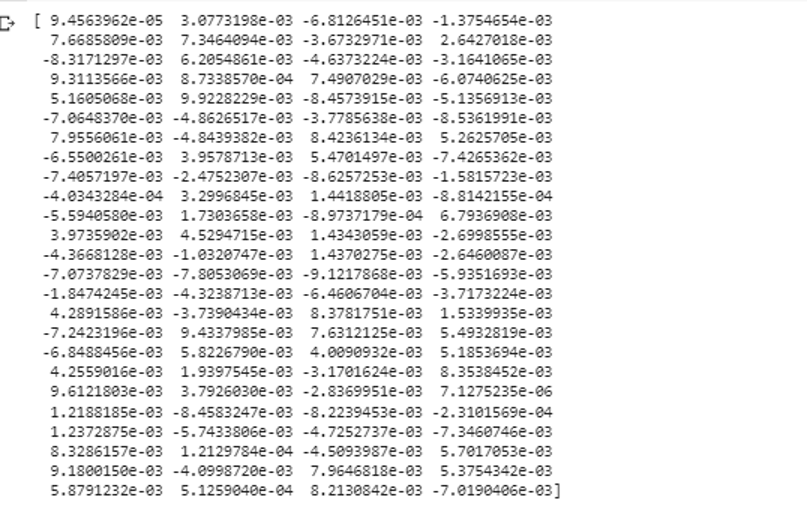
We can observe the vector representation of the word that we fed to the model as its input from the previous snippet of the output.
Conclusion
This guide demonstrates the method to create the word embedding for the words that exist in the list of English sentences. We learned about the “gensim” library of Python that provides the “word2vec” model to create the word embedding. Furthermore, we learned about input parameters, how to train the “word2vec” model on the training data, and how to present the word in a representation of the vector.